Home

This website is out of date but retained for posterity. Awesome New Website
- Currently: Postdoctoral researcher at the University of Edinburgh
- Unit: ILCC in the School of Informatics
- Supervisor: Mark Steedman
- 2008–2014: Ph.D. student at Carnegie Mellon University
- Department: Language Technologies Institute in the School of Computer Science
- Advisor: Noah Smith (Lab: Noah’s ARK)
- Thesis: Lexical Semantic Analysis in Natural Language Text
- Summer 2012: Intern at USC ISI
- 2004–2008: Undergraduate at UC Berkeley, majoring in Computer Science and Linguistics
- CV (PDF)
I study the semantics of natural language text. My research aims to address the questions: What is the nature of linguistic knowledge that participates in the communication of meaning? How can humans represent aspects of this knowledge computationally in data? How can algorithms recover it in new data for scientific inquiry or for natural language processing applications?
My work draws techniques and insights from statistical machine learning, descriptive linguistics, construction grammar, and cognitive linguistics. My dissertation was on lexical semantics. A research overview provides more detail. Here are some topics, with superscripts denoting languages other than English:
| NER/lexical semantics | (EACL’12)a (ACL’12)a (NAACL’13b)a (LREC’14a) (LREC’14b) (TACL’14) (NAACL’15) (LAW’15) (CoNLL’15) |
|---|---|
| morphology, POS, syntax | (BLS’10)h (CSDL’10) (ACL’11) (NAACL’13a) (LAW’13)e,k,m (COLING’14) (EMNLP’14) |
| relational semantic parsing | (NAACL’10) (SemEval’10) (IFNW’13) (CL’14) (SP’14a) (SP’14b) (SemEval’14) (ACL’15) |
| second language | (BEA’13) |
| linguistic annotation | (ACL’11) (EACL’12)a (ACL’12)a (NAACL’13a) (LAW’13)e,k,m (LAW’13) (LREC’14a) (LREC’14b) (EMNLP’14) (NAACL’15) (LAW’15) (LREC’16) |
| social web | (CMU-Q’11)a,e (ACL’11) (EACL’12)a (NAACL’13a) (NAACL’13b)a (LAW’13)e,k,m (LREC’14a) (TACL’14) (EMNLP’14) (NAACL’15) |
News & presentations:
- In Fall 2016, I will join Georgetown University as an Assistant Professor of Linguistics and Computer Science!
- 2016-06-17 | NAACL-HLT Workshop on Multilingual and Cross-lingual Methods in NLP
- 2016-06-02 | University of Amsterdam
- 2016-02-19 | UC San Diego
- 2016-02-02 | Georgetown University
- Participate in the SemEval 2016 shared task on Detecting Minimal Semantic Units and their Meanings (DiMSUM)!
- 2016-01-04 | Bar-Ilan University
- 2015-12-29 | Hebrew University of Jerusalem
- 2015-10-20 | Saarland University
- 2015-06-23 | Keynote at Workshop on Natural Language Processing for Informal Text
- 2015-06-05 | Linguistic Annotation Workshop panel on syntactic annotation of non-canonical language
- 2015-05-31 | AMR tutorial at NAACL-HLT
- 2015-05-31 | FrameNet tutorial at NAACL-HLT
- 2015-04-30 | University of Copenhagen
- 2015-04-27/28 | Bielefeld University
- 2015-02-06 | Google Mountain View
- 2014-11-19 | University of Gothenburg
- 2014-10-24 | University of Edinburgh
- 2014-08-08 | University of Toronto
- 2014-04-02 | Johns Hopkins University
This homepage is brought to you by the letter θ, a friend to linguists and statisticians alike.
Papers
Dissertation
- Nathan Schneider (2014). Lexical Semantic Analysis in Natural Language Text.
Refereed
- Nathan Schneider, Jena D. Hwang, Vivek Srikumar, Meredith Green, Abhijit Suresh, Kathryn Conger, Tim O’Gorman, and Martha Palmer (2016). A corpus of preposition supersenses. Linguistic Annotation Workshop. [paper] We present the first corpus annotated with preposition supersenses, unlexicalized categories for semantic functions that can be marked by English prepositions (Schneider et al., 2015). The preposition supersenses are organized hierarchically and designed to facilitate comprehensive manual annotation. Our dataset is publicly released on the web. @InProceedings{psstcorpus, author = {Schneider, Nathan and Hwang, Jena D. and Srikumar, Vivek and Green, Meredith and Suresh, Abhijit and Conger, Kathryn and O'Gorman, Tim and Palmer, Martha}, title = {A Corpus of Preposition Supersenses}, booktitle = {Proceedings of the 10th Linguistic Annotation Workshop}, month = aug, year = {2016}, address = {Berlin, Germany}, pages = {99--109}, publisher = {Association for Computational Linguistics}, url = {http://aclweb.org/anthology/W16-1712} } Dataset to appear.
- Hannah Rohde, Anna Dickinson, Nathan Schneider, Christopher N. L. Clark, Annie Louis, and Bonnie Webber (2016). Filling in the blanks in understanding discourse adverbials: consistency, conflict, and context-dependence in a crowdsourced elicitation task. Linguistic Annotation Workshop. [paper] [slides] The semantic relationship between a sentence and its context may be marked explicitly, or left to inference. Rohde et al. (2015) showed that, contrary to common assumptions, this isn't exclusive or: a conjunction can often be inferred alongside an explicit discourse adverbial. Here we broaden the investigation to a larger set of 20 discourse adverbials by eliciting ≈28K conjunction completions via crowdsourcing. Our data replicate and extend earlier findings that discourse adverbials do indeed license inferred conjunctions. Further, the diverse patterns observed for the adverbials include cases in which more than one valid connection can be inferred, each one endorsed by a substantial number of participants; such differences in annotation might otherwise be written off as annotator error or bias, or just a low level of inter-annotator agreement. These results will inform future discourse annotation endeavors by revealing where it is necessary to entertain implicit relations and elicit several judgments to fully characterize discourse relationships. @InProceedings{disadv, author = {Rohde, Hannah and Dickinson, Anna and Schneider, Nathan and Clark, Christopher N. L. and Louis, Annie and Webber, Bonnie}, title = {Filling in the Blanks in Understanding Discourse Adverbials: Consistency, Conflict, and Context-Dependence in a Crowdsourced Elicitation Task}, booktitle = {Proceedings of the 10th Linguistic Annotation Workshop}, month = aug, year = {2016}, address = {Berlin, Germany}, pages = {49--58}, publisher = {Association for Computational Linguistics}, url = {http://aclweb.org/anthology/W16-1707} } Dataset to appear.
- Nathan Schneider, Dirk Hovy, Anders Johannsen, and Marine Carpuat (2016). SemEval-2016 Task 10: Detecting Minimal Semantic Units and their Meanings (DiMSUM) DiMSUM @SemEval. [paper] This task combines the labeling of multiword expressions and supersenses (coarse-grained classes) in an explicit, yet broad-coverage paradigm for lexical semantics. Nine systems participated; the best scored 57.7% F1 in a multi-domain evaluation setting, indicating that the task remains largely unresolved. An error analysis reveals that a large number of instances in the data set are either hard cases, which no systems get right, or easy cases, which all systems correctly solve. @inproceedings{dimsum-16, address = {San Diego, California, {USA}}, title = {\mbox{{SemEval}-2016} {T}ask~10: {D}etecting {M}inimal {S}emantic {U}nits and their {M}eanings ({DiMSUM})}, booktitle = {Proc. of {SemEval}}, author = {Schneider, Nathan and Hovy, Dirk and Johannsen, Anders and Carpuat, Marine}, month = jun, year = {2016} }
- Nora Hollenstein, Nathan Schneider, and Bonnie Webber (2016). Inconsistency detection in semantic annotation. LREC. [paper] [slides] Inconsistencies are part of any manually annotated corpus. Automatically finding these inconsistencies and correcting them (even manually) can increase the quality of the data. Past research has focused mainly on detecting inconsistency in syntactic annotation. This work explores new approaches to detecting inconsistency in semantic annotation. Two ranking methods are presented in this paper: a discrepancy ranking and an entropy ranking. Those methods are then tested and evaluated on multiple corpora annotated with multiword expressions and supersense labels. The results show considerable improvements in detecting inconsistency candidates over a random baseline. Possible applications of methods for inconsistency detection are improving the annotation procedure and guidelines, as well as correcting errors in completed annotations. @inproceedings{annoinconsistency, address = {Portoro{\v z}, Slovenia}, title = {Inconsistency Detection in Semantic Annotation}, booktitle = {Proceedings of the Tenth International Conference on Language Resources and Evaluation}, publisher = {{ELRA}}, author = {Hollenstein, Nora and Schneider, Nathan and Webber, Bonnie}, editor = {Calzolari, Nicoletta and Choukri, Khalid and Declerck, Thierry and Grobelnik, Marko and Maegaard, Bente and Mariani, Joseph and Moreno, Asuncion and Odijk, Jan and Piperidis, Stelios}, month = may, year = {2016}, pages = {3986--3990} }[data and software]
- Meghana Kshirsagar, Sam Thomson, Nathan Schneider, Jaime Carbonell, Noah A. Smith, and Chris Dyer (2015). Frame-semantic role labeling with heterogeneous annotations. ACL-IJCNLP. [paper] [slides] We consider the task of identifying and labeling the semantic arguments of a predicate that evokes a FrameNet frame. This task is challenging because there are only a few thousand fully annotated sentences for supervised training. Our approach augments an existing model with features derived from FrameNet and PropBank and with partially annotated exemplars from FrameNet. We observe a 4% absolute increase in F1 versus the original model. @InProceedings{heterosrl, author = {Kshirsagar, Meghana and Thomson, Sam and Schneider, Nathan and Carbonell, Jaime and Smith, Noah A. and Dyer, Chris}, title = {Frame-Semantic Role Labeling with Heterogeneous Annotations}, booktitle = {Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing}, month = jul, year = {2015}, address = {Beijing, China}, publisher = {Association for Computational Linguistics} }[software]
- Lizhen Qu, Gabriela Ferraro, Liyuan Zhou, Weiwei Hou, Nathan Schneider, and Timothy Baldwin (2015). Big data small data, in domain out-of domain, known word unknown word: the impact of word representations on sequence labelling tasks. CoNLL. [paper] Word embeddings — distributed word representations that can be learned from unlabelled data — have been shown to have high utility in many natural language processing applications. In this paper, we perform an extrinsic evaluation of four popular word embedding methods in the context of four sequence labelling tasks: part-of-speech tagging, syntactic chunking, named entity recognition, and multiword expression identification. A particular focus of the paper is analysing the effects of task-based updating of word representations. We show that when using word embeddings as features, as few as several hundred training instances are sufficient to achieve competitive results, and that word embeddings lead to improvements over out-of-vocabulary words and also out of domain. Perhaps more surprisingly, our results indicate there is little difference between the different word embedding methods, and that simple Brown clusters are often competitive with word embeddings across all tasks we consider. @InProceedings{wordrepseq, author = {Qu, Lizhen and Ferraro, Gabriela and Zhou, Liyuan and Hou, Weiwei and Schneider, Nathan and Baldwin, Timothy}, title = {Big Data Small Data, In Domain Out-of Domain, Known Word Unknown Word: The Impact of Word Representations on Sequence Labelling Tasks}, booktitle = {Proceedings of the Nineteenth Conference on Computational Natural Language Learning}, month = jul, year = {2015}, address = {Beijing, China}, publisher = {Association for Computational Linguistics}, pages = {83--93}, url = {http://www.aclweb.org/anthology/K15-1009} }
- Nathan Schneider (2015). Struggling with English prepositional verbs. ICLC. [abstract] [slides]
- Nathan Schneider and Noah A. Smith (2015). A corpus and model integrating multiword expressions and supersenses. NAACL-HLT. [paper] [slides] [video] This paper introduces a task of identifying and semantically classifying lexical expressions in running text. We investigate the online reviews genre, adding semantic supersense annotations to a 55,000 word English corpus that was previously annotated for multiword expressions. The noun and verb supersenses apply to full lexical expressions, whether single- or multiword. We then present a sequence tagging model that jointly infers lexical expressions and their supersenses. Results show that even with our relatively small training corpus in a noisy domain, the joint task can be performed to attain 70% class labeling F1. @InProceedings{sst, author = {Schneider, Nathan and Smith, Noah A.}, title = {A Corpus and Model Integrating Multiword Expressions and Supersenses}, booktitle = {Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies}, month = {May--June}, year = {2015}, address = {Denver, Colorado, USA}, publisher = {Association for Computational Linguistics}, pages = {1537--1547}, url = {http://www.aclweb.org/anthology/N15-1177} }[data and software]
- Nathan Schneider, Vivek Srikumar, Jena D. Hwang, and Martha Palmer (2015). A hierarchy with, of, and for preposition supersenses. Linguistic Annotation Workshop. [paper] [poster] English prepositions are extremely frequent and extraordinarily polysemous. In some usages they contribute information about spatial, temporal, or causal roles/relations; in other cases they are institutionalized, somewhat arbitrarily, as case markers licensed by a particular governing verb, verb class, or syntactic construction. To facilitate automatic disambiguation, we propose a general-purpose, broad-coverage taxonomy of preposition functions that we call supersenses: these are coarse and unlexicalized so as to be tractable for efficient manual annotation, yet capture crucial semantic distinctions. Our resource, including extensive documentation of the supersenses, many example sentences, and mappings to other lexical resources, will be publicly released. @InProceedings{pssts, author = {Schneider, Nathan and Srikumar, Vivek and Hwang, Jena D. and Palmer, Martha}, title = {A Hierarchy with, of, and for Preposition Supersenses}, booktitle = {Proceedings of the 9th Linguistic Annotation Workshop}, month = jun, year = {2015}, address = {Denver, Colorado, USA}, publisher = {Association for Computational Linguistics}, pages = {112--123}, url = {http://www.aclweb.org/anthology/W15-1612} } [resource]
- Lingpeng Kong, Nathan Schneider, Swabha Swayamdipta, Archna Bhatia, Chris Dyer, and Noah A. Smith (2014). A dependency parser for tweets. EMNLP. [paper] [slides] [video] We describe a new dependency parser for English tweets, Tweeboparser. The parser builds on several contributions: new syntactic annotations for a corpus of tweets (Tweebank), with conventions informed by the domain; adaptations to a statistical parsing algorithm; and a new approach to exploiting out-of-domain Penn Treebank data. Our experiments show that the parser achieves over 80% unlabeled attachment accuracy on our new, high-quality test set and measure the benefit of our contributions. Our dataset and parser can be found at http://cs.cmu.edu/~ark/TweetNLP. @inproceedings{twparse, address = {Doha, Qatar}, title = {A Dependency Parser for Tweets}, booktitle = {Proceedings of the Conference on Empirical Methods in Natural Language Processing}, publisher = {Association for Computational Linguistics}, author = {Kong, Lingpeng and Schneider, Nathan and Swayamdipta, Swabha and Bhatia, Archna and Dyer, Chris and Smith, Noah A.}, month = oct, year = {2014}, publisher = {Association for Computational Linguistics}, pages = {1001--1012}, url = {http://www.aclweb.org/anthology/D14-1108} }
- Sam Thomson, Brendan O’Connor, Jeffrey Flanigan, David Bamman, Jesse Dodge, Swabha Swayamdipta, Nathan Schneider, Chris Dyer, and Noah A. Smith (2014). CMU: Arc-Factored, Discriminative Semantic Dependency Parsing. Task 8: Broad-Coverage Semantic Dependency Parsing @SemEval. [paper] [poster] We present an arc-factored statistical model for semantic dependency parsing, as defined by the SemEval 2014 Shared Task 8 on Broad-Coverage Semantic Dependency Parsing. Our entry in the open track placed second in the competition. @inproceedings{chen-schneider-das-smith-10, author = {Thomson, Sam and O'Connor, Brendan and Flanigan, Jeffrey and Bamman, David and Dodge, Jesse and Swayamdipta, Swabha and Schneider, Nathan and Dyer, Chris and Smith, Noah A.}, title = {{CMU}: Arc-Factored, Discriminative Semantic Dependency Parsing}, booktitle = {Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014)}, month = aug, year = {2014}, address = {Dublin, Ireland}, publisher = {Association for Computational Linguistics and Dublin City University}, pages = {176--180}, url = {http://www.aclweb.org/anthology/S14-2027} }
-
Nathan Schneider,
Emily Danchik,
Chris Dyer, and
Noah A. Smith (2014).
Discriminative lexical semantic segmentation with gaps: running the MWE gamut.
TACL 2(April):193−206.
Presented at ACL 2014.
[paper] [poster]
We present a novel representation, evaluation measure, and supervised models for the task of identifying the multiword expressions (MWEs) in a sentence, resulting in a lexical semantic segmentation. Our approach generalizes a standard chunking representation to encode MWEs containing gaps, thereby enabling efficient sequence tagging algorithms for feature-rich discriminative models. Experiments on a new dataset of English web text offer the first linguistically-driven evaluation of MWE identification with truly heterogeneous expression types. Our statistical sequence model greatly outperforms a lookup-based segmentation procedure, achieving nearly 60% F1 for MWE identification.
@article{mwe,
title = {Discriminative lexical semantic segmentation with gaps: running the {MWE} gamut},
volume = {2},
journal = {Transactions of the Association for Computational Linguistics},
author = {Schneider, Nathan and Danchik, Emily and Dyer, Chris and Smith, Noah A.},
month = apr,
year = {2014},
pages = {193--206},
url = {http://www.transacl.org/wp-content/uploads/2014/04/51.pdf}
}
- There was a bug in the evaluation script affecting the Exact Match scores: cases where an MWE occurs within the gap of another MWE were not counted correctly. Here is the corrected version of table 3:

- The description of the link-based evaluation measure in section 3.2 overstates the relationship between this measure and the MUC criterion for coreference resolution. They are very similar but not identical: an example for which they give different results is explained in footnote 3 on p. 132 of my thesis.
- There was a bug in the evaluation script affecting the Exact Match scores: cases where an MWE occurs within the gap of another MWE were not counted correctly. Here is the corrected version of table 3:
- Dipanjan Das, Desai Chen, André F. T. Martins, Nathan Schneider, and Noah A. Smith (2014). Frame-semantic parsing.
- Archna Bhatia, Chu-Cheng Lin, Nathan Schneider, Yulia Tsvetkov, Fatima Talib Al-Raisi, Laleh Roostapour, Jordan Bender, Abhimanu Kumar, Lori Levin, Mandy Simons, and Chris Dyer (2014). Automatic classification of communicative functions of definiteness. COLING. [paper] [poster] Definiteness expresses a constellation of semantic, pragmatic, and discourse properties—the communicative functions—of an NP. We present a supervised classifier for English NPs that uses lexical, morphological, and syntactic features to predict an NP’s communicative function in terms of a language-universal classification scheme. Our classifiers establish strong baselines for future work in this neglected area of computational semantic analysis. In addition, analysis of the features and learned parameters in the model provides insight into the grammaticalization of definiteness in English, not all of which is obvious a priori. @inproceedings{definiteness, address = {Dublin, Ireland}, title = {Automatic Classification of Communicative Functions of Definiteness}, booktitle = {Proceedings of {COLING} 2014, the 25th International Conference on Computational Linguistics}, author = {Bhatia, Archna and Lin, {Chu-Cheng} and Schneider, Nathan and Tsvetkov, Yulia and Talib Al-Raisi, Fatima and Roostapour, Laleh and Bender, Jordan and Kumar, Abhimanu and Levin, Lori and Simons, Mandy and Dyer, Chris}, month = aug, year = {2014}, publisher = {Dublin City University and Association for Computational Linguistics}, pages = {1059--1070}, url = {http://www.aclweb.org/anthology/C14-1100} }
- Nathan Schneider, Spencer Onuffer, Nora Kazour, Emily Danchik, Michael T. Mordowanec, Henrietta Conrad, and Noah A. Smith (2014). Comprehensive annotation of multiword expressions in a social web corpus. LREC. [paper] Multiword expressions (MWEs) are quite frequent in languages such as English, but their diversity, the scarcity of individual MWE types, and contextual ambiguity have presented obstacles to corpus-based studies and NLP systems addressing them as a class. Here we advocate for a comprehensive annotation approach: proceeding sentence by sentence, our annotators manually group tokens into MWEs according to guidelines that cover a broad range of multiword phenomena. Under this scheme, we have fully annotated an English web corpus for multiword expressions, including those containing gaps. @inproceedings{mwecorpus, address = {Reykjav\'{i}k, Iceland}, title = {Comprehensive Annotation of Multiword Expressions in a Social Web Corpus}, booktitle = {Proceedings of the Ninth International Conference on Language Resources and Evaluation}, publisher = {{ELRA}}, author = {Schneider, Nathan and Onuffer, Spencer and Kazour, Nora and Danchik, Emily and Mordowanec, Michael T. and Conrad, Henrietta and Smith, Noah A.}, editor = {Calzolari, Nicoletta and Choukri, Khalid and Declerck, Thierry and Loftsson, Hrafn and Maegaard, Bente and Mariani, Joseph and Moreno, Asuncion and Odijk, Jan and Piperidis, Stelios}, month = may, year = {2014}, pages = {455--461}, url = {http://www.lrec-conf.org/proceedings/lrec2014/pdf/521_Paper.pdf} } [data]
- Yulia Tsvetkov, Nathan Schneider, Dirk Hovy, Archna Bhatia, Manaal Faruqui, and Chris Dyer (2014). Augmenting English adjective senses with supersenses. LREC. [paper] We develop a supersense taxonomy for adjectives, based on that of GermaNet, and apply it to English adjectives in WordNet using human annotation and supervised classification. Results show that accuracy for automatic adjective type classification is high, but synsets are considerably more difficult to classify, even for trained human annotators. We release the manually annotated data, the classifier, and the induced supersense labeling of 12,304 WordNet adjective synsets. @inproceedings{adjs, address = {Reykjav\'{i}k, Iceland}, title = {Augmenting {E}nglish Adjective Senses with Supersenses}, booktitle = {Proceedings of the Ninth International Conference on Language Resources and Evaluation}, publisher = {{ELRA}}, author = {Tsvetkov, Yulia and Schneider, Nathan and Hovy, Dirk and Bhatia, Archna and Faruqui, Manaal and Dyer, Chris}, editor = {Calzolari, Nicoletta and Choukri, Khalid and Declerck, Thierry and Loftsson, Hrafn and Maegaard, Bente and Mariani, Joseph and Moreno, Asuncion and Odijk, Jan and Piperidis, Stelios}, month = may, year = {2014}, pages = {4359--4365}, url = {http://www.lrec-conf.org/proceedings/lrec2014/pdf/1096_Paper.pdf} } [data] [software]
- Meghana Kshirsagar, Nathan Schneider, and Chris Dyer (2014). Leveraging heterogeneous data sources for relational semantic parsing. Workshop on Semantic Parsing. [extended abstract] [poster] A number of semantic annotation efforts have produced a variety of annotated corpora, capturing various aspects of semantic knowledge in different formalisms. Due to to the cost of these annotation efforts and the relatively small amount of semantically annotated corpora, we argue it is advantageous to be able to leverage as much annotated data as possible. This work presents a preliminary exploration of the opportunities and challenges of learning semantic parsers from heterogeneous semantic annotation sources. We primarily focus on two semantic resources, FrameNet and PropBank, with the goal of improving frame-semantic parsing. Our analysis of the two data sources highlights the benefits that can be reaped by combining information across them.
- Jeffrey Flanigan, Samuel Thomson, David Bamman, Jesse Dodge, Manaal Faruqui, Brendan O’Connor, Nathan Schneider, Swabha Swayamdipta, Chris Dyer, and Noah A. Smith (2014). Graph-based algorithms for semantic parsing. Workshop on Semantic Parsing.
- Michael T. Mordowanec, Nathan Schneider, Chris Dyer, and Noah A. Smith (2014). Simplified dependency annotations with GFL-Web. ACL demo. [paper] [poster] We present GFL-Web, a web-based interface for syntactic dependency annotation with the lightweight FUDG/GFL formalism. Syntactic attachments are specified in GFL notation and visualized as a graph. A one-day pilot of this workflow with 26 annotators established that even novices were, with a bit of training, able to rapidly annotate the syntax of English Twitter messages. The open-source tool is easily installed and configured; it is available at: https://github.com/Mordeaux/gfl_web @inproceedings{gflweb, address = {Baltimore, Maryland, USA}, title = {Simplified dependency annotations with {GFL-Web}}, booktitle = {Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations}, publisher = {Association for Computational Linguistics}, author = {Mordowanec, Michael T. and Schneider, Nathan and Dyer, Chris and Smith, Noah A.}, month = jun, year = {2014}, pages = {121--126}, url = {http://www.aclweb.org/anthology/P14-5021} } [software]
- Nathan Schneider, Brendan O’Connor, Naomi Saphra, David Bamman, Manaal Faruqui, Noah A. Smith, Chris Dyer, and Jason Baldridge (2013). A framework for (under)specifying dependency syntax without overloading annotators. Linguistic Annotation Workshop. [paper] [extended version] We introduce a framework for lightweight dependency syntax annotation. Our formalism builds upon the typical representation for unlabeled dependencies, permitting a simple notation and annotation workflow. Moreover, the formalism encourages annotators to underspecify parts of the syntax if doing so would streamline the annotation process. We demonstrate the efficacy of this annotation on three languages and develop algorithms to evaluate and compare underspecified annotations. @InProceedings{fudg, author = {Schneider, Nathan and O'Connor, Brendan and Saphra, Naomi and Bamman, David and Faruqui, Manaal and Smith, Noah A. and Dyer, Chris and Baldridge, Jason}, title = {A Framework for (Under)specifying Dependency Syntax without Overloading Annotators}, booktitle = {Proceedings of the 7th Linguistic Annotation Workshop & Interoperability with Discourse}, month = aug, year = {2013}, address = {Sofia, Bulgaria}, publisher = {Association for Computational Linguistics}, url = {http://www.aclweb.org/anthology/W13-2307} } [data and software]
- Laura Banarescu, Claire Bonial, Shu Cai, Madalina Georgescu, Kira Griffitt, Ulf Hermjakob, Kevin Knight, Philipp Koehn, Martha Palmer, and Nathan Schneider (2013). Abstract Meaning Representation for sembanking. Linguistic Annotation Workshop. [paper] [website] We describe Abstract Meaning Representation (AMR), a semantic representation language in which we are writing down the meanings of thousands of English sentences. We hope that a sembank of simple, whole-sentence semantic structures will spur new work in statistical natural language understanding and generation, like the Penn Treebank encouraged work on statistical parsing. This paper gives an overview of AMR and tools associated with it. @InProceedings{amr, author = {Banarescu, Laura and Bonial, Claire and Cai, Shu and Georgescu, Madalina and Griffitt, Kira and Hermjakob, Ulf and Knight, Kevin and Koehn, Philipp and Palmer, Martha and Schneider, Nathan}, title = {{A}bstract {M}eaning {R}epresentation for Sembanking}, booktitle = {Proceedings of the 7th Linguistic Annotation Workshop & Interoperability with Discourse}, month = aug, year = {2013}, address = {Sofia, Bulgaria}, publisher = {Association for Computational Linguistics}, url = {http://www.aclweb.org/anthology/W13-2322} }
- Nathan Schneider, Behrang Mohit, Chris Dyer, Kemal Oflazer, and Noah A. Smith (2013). Supersense tagging for Arabic: the MT-in-the-middle attack. NAACL-HLT. [paper] [slides] [video] We consider the task of tagging Arabic nouns with WordNet supersenses. Three approaches are evaluated. The first uses an expert-crafted but limited-coverage lexicon, Arabic WordNet, and heuristics. The second uses unsupervised sequence modeling. The third and most successful approach uses machine translation to translate the Arabic into English, which is automatically tagged with English supersenses, the results of which are then projected back into Arabic. Analysis shows gains and remaining obstacles in four Wikipedia topical domains. @InProceedings{arabic-sst-mt, author = {Schneider, Nathan and Mohit, Behrang and Dyer, Chris and Oflazer, Kemal and Smith, Noah A.}, title = {Supersense Tagging for {A}rabic: the {MT}-in-the-Middle Attack}, booktitle = {Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies}, month = jun, year = {2013}, address = {Atlanta, Georgia, USA}, publisher = {Association for Computational Linguistics}, pages = {661--667}, url = {http://www.aclweb.org/anthology/N13-1076} }
-
Olutobi Owoputi,
Brendan O’Connor,
Chris Dyer,
Kevin Gimpel, Nathan Schneider,
and Noah A. Smith (2013).
Improved part-of-speech tagging for online conversational text with word clusters.
NAACL-HLT.
[paper] [summary slide] [poster]
We consider the problem of part-of-speech tagging for informal, online conversational text.
We systematically evaluate the use of large-scale unsupervised word clustering and new lexical features
to improve tagging accuracy. With these features, our system achieves state-of-the-art tagging results on both
Twitter and IRC POS tagging tasks; Twitter tagging is improved from 90% to 93% accuracy (more than 3% absolute).
Qualitative analysis of these word clusters yields insights about NLP and linguistic phenomena in this genre.
Additionally, we contribute the first POS annotation guidelines for such text and release a new dataset of
English language tweets annotated using these guidelines. Tagging software, annotation guidelines, and large-scale
word clusters are available at: http://cs.cmu.edu/~ark/TweetNLP
This paper describes release 0.3 of the “CMU Twitter Part-of-Speech Tagger” and annotated data. @InProceedings{owoputi-twitter-pos, author = {Owoputi, Olutobi and O'Connor, Brendan and Dyer, Chris and Gimpel, Kevin and Schneider, Nathan and Smith, Noah A.}, title = {Improved Part-of-Speech Tagging for Online Conversational Text with Word Clusters}, booktitle = {Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies}, month = jun, year = {2013}, address = {Atlanta, Georgia, USA}, publisher = {Association for Computational Linguistics}, pages = {380--390}, url = {http://www.aclweb.org/anthology/N13-1039} } [data and software] - Yulia Tsvetkov, Naama Twitto, Nathan Schneider, Noam Ordan, Manaal Faruqui, Victor Chahuneau, Shuly Wintner, and Chris Dyer (2013). Identifying the L1 of non-native writers: the CMU-Haifa system. NLI Shared Task @BEA. [paper] [poster] We show that it is possible to learn to identify, with high accuracy, the native language of English test takers from the content of the essays they write. Our method uses standard text classification techniques based on multiclass logistic regression, combining individually weak indicators to predict the most probable native language from a set of 11 possibilities. We describe the various features used for classification, as well as the settings of the classifier that yielded the highest accuracy. @InProceedings{tsvetkov-l1id, author = {Yulia Tsvetkov and Naama Twitto and Nathan Schneider and Noam Ordan and Manaal Faruqui and Victor Chahuneau and Shuly Wintner and Chris Dyer}, title = {Identifying the {L1} of non-native writers: the {CMU}-{H}aifa system}, booktitle = {Proceedings of the Eighth Workshop on Innovative Use of {NLP} for Building Educational Applications}, month = jun, year = {2013}, address = {Atlanta, Georgia, USA}, publisher = {Association for Computational Linguistics}, pages = {279--287}, url = {http://www.aclweb.org/anthology/W13-1736} }
- Nathan Schneider, Chris Dyer, and Noah A. Smith (2013). Exploiting and expanding corpus resources for frame-semantic parsing. IFNW. [slides]
- Nathan Schneider, Behrang Mohit, Kemal Oflazer, and Noah A. Smith (2012). Coarse lexical semantic annotation with supersenses: an Arabic case study. ACL. [paper] “Lightweight” semantic annotation of text calls for a simple representation, ideally without requiring a semantic lexicon to achieve good coverage in the language and domain. In this paper, we repurpose WordNet’s supersense tags for annotation, developing specific guidelines for nominal expressions and applying them to Arabic Wikipedia articles in four topical domains. The resulting corpus has high coverage and was completed quickly with reasonable inter-annotator agreement. @InProceedings{arabic-sst-annotation, author = {Schneider, Nathan and Mohit, Behrang and Oflazer, Kemal and Smith, Noah A.}, title = {Coarse Lexical Semantic Annotation with Supersenses: An {A}rabic Case Study}, booktitle = {Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics}, month = jul, year = {2012}, address = {Jeju Island, Korea}, publisher = {Association for Computational Linguistics}, pages = {253--258}, url = {http://www.aclweb.org/anthology/P12-2050} } [data]
- Behrang Mohit, Nathan Schneider, Rishav Bhowmick, Kemal Oflazer, and Noah A. Smith (2012). Recall-oriented learning of named entities in Arabic Wikipedia. EACL. [paper] [supplement] We consider the problem of NER in Arabic Wikipedia, a semisupervised domain adaptation setting for which we have no labeled training data in the target domain. To facilitate evaluation, we obtain annotations for articles in four topical groups, allowing annotators to identify domain-specific entity types in addition to standard categories. Standard supervised learning on newswire text leads to poor target-domain recall. We train a sequence model and show that a simple modification to the online learner—a loss function encouraging it to “arrogantly” favor recall over precision—substantially improves recall and F1. We then adapt our model with self-training on unlabeled target-domain data; enforcing the same recall-oriented bias in the self-training stage yields marginal gains. @InProceedings{mohit-arabic-ner, author = {Mohit, Behrang and Schneider, Nathan and Bhowmick, Rishav and Oflazer, Kemal and Smith, Noah A.}, title = {Recall-Oriented Learning of Named Entities in {A}rabic {W}ikipedia}, booktitle = {Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics}, month = apr, year = {2012}, address = {Avignon, France}, publisher = {Association for Computational Linguistics}, pages = {162--173}, url = {http://www.aclweb.org/anthology/E12-1017} } [data and software]
- Kevin Gimpel, Nathan Schneider, Brendan O’Connor, Dipanjan Das, Daniel Mills, Jacob Eisenstein, Michael Heilman, Dani Yogatama, Jeffrey Flanigan, and Noah A. Smith (2011). Part-of-speech tagging for Twitter: annotation, features, and experiments. ACL-HLT. [paper] [slides] We address the problem of part-of-speech tagging for English data from the popular microblogging service Twitter. We develop a tagset, annotate data, develop features, and report tagging results nearing 90% accuracy. The data and tools have been made available to the research community with the goal of enabling richer text analysis of Twitter and related social media data sets. @inproceedings{gimpel-twitter-pos, author = {Gimpel, Kevin and Schneider, Nathan and O'Connor, Brendan and Das, Dipanjan and Mills, Daniel and Eisenstein, Jacob and Heilman, Michael and Yogatama, Dani and Flanigan, Jeffrey and Smith, Noah A.}, title = {Part-of-Speech Tagging for {T}witter: Annotation, Features, and Experiments}, booktitle = {Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies}, month = jun, year = {2011}, address = {Portland, Oregon, USA}, publisher = {Association for Computational Linguistics}, pages = {42--47}, url = {http://www.aclweb.org/anthology/P11-2008} } [data and software] [press]
- Desai Chen, Nathan Schneider, Dipanjan Das, and Noah A. Smith (2010). SEMAFOR: Frame argument resolution with log-linear models. Task 10: Linking Events and their Participants in Discourse @SemEval. [paper] [slides] This paper describes the SEMAFOR system’s performance in the SemEval 2010 task on linking events and their participants in discourse. Our entry is based upon SEMAFOR 1.0 (Das et al., 2010), a frame-semantic probabilistic parser built from log-linear models. The extended system models null instantiations, including non-local argument reference. Performance is evaluated on the task data with and without gold-standard overt arguments. In both settings, it fares the best of the submitted systems with respect to recall and F1. @inproceedings{chen-schneider-das-smith-10, author = {Desai Chen and Nathan Schneider and Dipanjan Das and Noah A. Smith}, title = {{SEMAFOR}: Frame Argument Resolution with Log-Linear Models}, booktitle = {Proceedings of the Fifth International Workshop on Semantic Evaluation (SemEval-2010)}, month = jul, year = {2010}, address = {Uppsala, Sweden}, publisher = {Association for Computational Linguistics}, pages = {264--267}, url = {http://www.aclweb.org/anthology/S10-1059} }
- Dipanjan Das, Nathan Schneider, Desai Chen, and Noah A. Smith (2010). Probabilistic frame-semantic parsing. NAACL-HLT. [paper] [slides] This paper contributes a formalization of frame-semantic parsing as a structure prediction problem and describes an implemented parser that transforms an English sentence into a frame-semantic representation. It finds words that evoke FrameNet frames, selects frames for them, and locates the arguments for each frame. The system uses two feature-based, discriminative probabilistic (log-linear) models, one with latent variables to permit disambiguation of new predicate words. The parser is demonstrated to significantly outperform previously published results. @inproceedings{das-schneider-chen-smith-10, author = {Dipanjan Das and Nathan Schneider and Desai Chen and Noah A. Smith}, title = {Probabilistic Frame-Semantic Parsing}, booktitle = {Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics}, month = jun, year = {2010}, address = {Los Angeles, California}, publisher = {Association for Computational Linguistics}, pages = {948--956}, url = {http://www.aclweb.org/anthology/N10-1138} } [software]
- Nathan Schneider (2010). English morphology in construction grammar. CSDL. [poster]
- Nathan Schneider (2010). Computational cognitive morphosemantics: modeling morphological compositionality in Hebrew verbs with Embodied Construction Grammar. BLS. [slides] [paper] This paper brings together the theoretical framework of construction grammar and studies of verbs in Modern Hebrew to furnish an analysis integrating the form and meaning components of morphological structure. In doing so, this work employs and extends Embodied Construction Grammar (ECG; Bergen and Chang 2005), a computational formalism developed to study grammar from a cognitive linguistic perspective. In developing a formal analysis of Hebrew verbs, I adapt ECG—until now a lexical/syntactic/semantic formalism—to account for the compositionality of morphological constructions, accommodating idiosyncrasy while encoding generalizations at multiple levels. Similar to syntactic constructions, morpheme constructions are related in an inheritance network, and can be productively composed to form words. With the expanded version of ECG, constructions can readily encode nonconcatenative root-and-pattern morphology and associated (compositional or noncompositional) semantics, cleanly integrated with syntactic constructions. This formal, cognitive study should pave the way for computational models of morphological learning and processing in Hebrew and other languages.
Tutorials
- Nathan Schneider, Jeffrey Flanigan, and Tim O’Gorman (2015). The logic of AMR: practical, unified, graph-based sentence semantics for NLP. NAACL-HLT tutorial. [abstract] [materials] [video] The Abstract Meaning Representation formalism is rapidly emerging as an important practical form of structured sentence semantics which, thanks to the availability of large-scale annotated corpora, has potential as a convergence point for NLP research. This tutorial unmasks the design philosophy, data creation process, and existing algorithms for AMR semantics. It is intended for anyone interested in working with AMR data, including parsing text into AMRs, generating text from AMRs, and applying AMRs to tasks such as machine translation and summarization. The goals of this tutorial are twofold. First, it will describe the nature and design principles behind the representation, and demonstrate that it can be practical for annotation. In Part I: The AMR Formalism, participants will be coached in the basics of annotation so that, when working with AMR data in the future, they will appreciate the benefits and limitations of the process by which it was created. Second, the tutorial will survey the state of the art for computation with AMRs. Part II: Algorithms and Applications will focus on the task of parsing English text into AMR graphs, which requires algorithms for alignment, for structured prediction, and for statistical learning. The tutorial will also address graph grammar formalisms that have been recently developed, and future applications such as AMR-based machine translation and summarization. @InProceedings{amr-tutorial, author = {Schneider, Nathan and Flanigan, Jeffrey and O'Gorman, Tim}, title = {The Logic of {AMR}: Practical, Unified, Graph-Based Sentence Semantics for {NLP}}, booktitle = {Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Tutorial Abstracts}, month = {May--June}, year = {2015}, address = {Denver, Colorado, USA}, publisher = {Association for Computational Linguistics}, pages = {4--5}, url = {http://www.aclweb.org/anthology/N15-4003} }
- Collin Baker, Nathan Schneider, Miriam R. L. Petruck, and Michael Ellsworth (2015). Getting the roles right: using FrameNet in NLP. NAACL-HLT tutorial. [abstract] [video] The FrameNet lexical database (Fillmore & Baker 2010, Ruppenhofer et al. 2006, http://framenet.icsi.berkeley.edu), covers roughly 13,000 lexical units (word senses) for the core Engish lexicon, associating them with roughly 1,200 fully defined semantic frames; these frames and their roles cover the majority of event types in everyday, non-specialist text, and they are documented with 200,000 manually annotated examples. This tutorial will teach attendees what they need to know to start using the FrameNet lexical database as part of an NLP system. We will cover the basics of Frame Semantics, explain how the database was created, introduce the Python API and the state of the art in automatic frame semantic role labeling systems; and we will discuss FrameNet collaboration with commercial partners. Time permitting, we will present new research on frames and annotation of locative relations, as well as corresponding metaphorical uses, along with information about how frame semantic roles can aid the interpretation of metaphors. @InProceedings{fn-tutorial, author = {Baker, Collin and Schneider, Nathan and Petruck, Miriam R. L. and Ellsworth, Michael}, title = {Getting the Roles Right: Using {FrameNet} in {NLP}}, booktitle = {Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Tutorial Abstracts}, month = {May--June}, year = {2015}, address = {Denver, Colorado, USA}, publisher = {Association for Computational Linguistics}, pages = {10--12}, url = {http://www.aclweb.org/anthology/N15-4006} }
Reviews & Position Papers
- Nathan Schneider (2015). What I’ve learned about annotating informal text (and why you shouldn’t take my word for it). Linguistic Annotation Workshop. [paper] In conjunction with this year’s LAW theme, “Syntactic Annotation of Non-canonical Language” (NCL), I have been asked to weigh in on several important questions faced by anyone wishing to create annotated resources of NCLs. My experience with syntactic annotation of non-canonical language falls under an effort undertaken at Carnegie Mellon University with the aim of building an NLP pipeline for syntactic analysis of Twitter text. We designed a linguistically-grounded annotation scheme, applied it to tweets, and then trained statistical analyzers—first for part-of-speech (POS) tags (Gimpel et al., 2011; Owoputi et al., 2012), then for parses (Schneider et al., 2013; Kong et al., 2014). I will review some of the salient points from this work in addressing the broader questions about annotation methodology. @inproceedings{law2015-opinion, title = {What I've learned about annotating informal text (and why you shouldn't take my word for it)}, booktitle = {Proceedings of the 9th Linguistic Annotation Workshop}, author = {Schneider, Nathan}, month = jun, year = {2015}, address = {Denver, Colorado, USA}, publisher = {Association for Computational Linguistics}, pages = {152--157}, url = {http://www.aclweb.org/anthology/W15-1618} }
- Nathan Schneider and Reut Tsarfaty (June 2013). Design Patterns in Fluid Construction Grammar, Luc Steels (editor). Computational Linguistics 39(2). [paper] @article{schneider-dpfcg-13, title = {{\em Design {P}atterns in {F}luid {C}onstruction {G}rammar}, {Luc Steels} (editor)}, volume = {39}, number = {2}, journal = {Computational Linguistics}, author = {Schneider, Nathan and Tsarfaty, Reut}, month = jun, year = {2013}, pages = {447--453} } [publisher link]
Reports & Presentations
- Nathan Schneider and Omri Abend (31 January 2016). Towards a dataset for evaluating multiword predicate interpretation in context. PARSEME STSM Report. [paper] Many multiword expressions (in the sense of Baldwin & Kim, 2010) are verbal predicates taking one or more arguments—including light verb constructions, other verb-noun constructions, verb-particle constructions, and prepositional verbs. We frame a lexical interpretation task for such multiword predicates (MWPs): given a sentence containing an MWP, the task is to predict other predicates (single or multiword) that are entailed. Preliminary steps have been taken toward developing an evaluation dataset via crowdsourcing.
- Olutobi Owoputi, Brendan O’Connor, Chris Dyer, Kevin Gimpel, and Nathan Schneider (September 2012). Part-of-speech tagging for Twitter: word clusters and other advances. Technical Report CMU-ML-12-107. [paper] We present improvements to a Twitter part-of-speech tagger, making use of several new features and large- scale word clustering. With these changes, the tagging accuracy increased from 89.2% to 92.8% and the tagging speed is 40 times faster. In addition, we expanded our Twitter tokenizer to support a broader range of Unicode characters, emoticons, and URLs. Finally, we annotate and evaluate on a new tweet dataset, DailyTweet547, that is more statistically representative of English-language Twitter as a whole. The new tagger is released as TweetNLP version 0.3, along with the new annotated data and large-scale word clusters at http://cs.cmu.edu/~ark/TweetNLP. @techreport{owoputi-twitter-pos-12-tr, author = {Olutobi Owoputi and Brendan O'Connor and Chris Dyer and Kevin Gimpel and Nathan Schneider}, institution = {Carnegie Mellon University}, address = {Pittsburgh, Pennsylvania}, type = {Technical Report}, number = {CMU-ML-12-107}, title = {Part-of-Speech Tagging for {T}witter: Word Clusters and Other Advances}, year = {2012}, month = sep, url = {http://cs.cmu.edu/~ark/TweetNLP/owoputi+etal.tr12.pdf} } [data and software]
- Nathan Schneider (5 October 2011). Casting a wider ’Net: NLP for the Social Web. Invited talk, CMU Qatar Computer Science. [slides] Natural language text dominates the information available on the Web. Yet the language of online expression often differs substantially, in both style and substance, from the language found in more traditional sources such as news. Making natural language processing techniques robust to this sort of variation is thus important for applications to behave intelligently when presented with Web text. This talk presents new research applying two sequence prediction tasks—part-of-speech tagging and named entity detection—to text from online social media platforms (Twitter and Wikipedia). For both tasks, we adapt standard forms of annotation to better suit the linguistic and topical characteristics of the data. We also propose techniques to elicit more accurate statistical taggers, including linguistic features inspired by the domain (for part-of-speech tagging of Twitter messages) as well as modifications to the learning algorithm (for named entity detection in Arabic Wikipedia).
- Nathan Schneider, Rebecca Hwa, Philip Gianfortoni, Dipanjan Das, Michael Heilman, Alan W. Black, Frederick L. Crabbe, and Noah A. Smith (July 2010). Visualizing topical quotations over time to understand news discourse. Technical Report CMU-LTI-10-013. [paper] We present the Pictor browser, a visualization designed to facilitate the analysis of quotations about user-specified topics in large collections of news text. Pictor focuses on quotations because they are a major vehicle of communication in the news genre. It extracts quotes from articles that match a user’s text query, and groups these quotes into “threads” that illustrate the development of subtopics over time. It allows users to rapidly explore the space of relevant quotes by viewing their content and speakers, to examine the contexts in which quotes appear, and to tune how threads are constructed. We offer two case studies demonstrating how Pictor can support a richer understanding of news events. @techreport{das-schneider-chen-smith-10-tr, author = {Nathan Schneider and Rebecca Hwa and Philip Gianfortoni and Dipanjan Das and Michael Heilman and Alan W. Black and Frederick L. Crabbe and Noah A. Smith}, institution = {Carnegie Mellon University}, address = {Pittsburgh, Pennsylvania}, type = {Technical Report}, number = {CMU-LTI-10-013}, title = {Visualizing Topical Quotations Over Time to Understand News Discourse}, year = {2010}, month = jul, url = {http://www.cs.cmu.edu/~nasmith/papers/schneider+etal.tr10.pdf} }
- Dipanjan Das, Nathan Schneider, Desai Chen, and Noah A. Smith (April 2010). SEMAFOR 1.0: A probabilistic frame-semantic parser. Technical Report CMU-LTI-10-001. [paper] An elaboration on (Das et al., 2010), this report formalizes frame-semantic parsing as a structure prediction problem and describes an implemented parser that transforms an English sentence into a frame-semantic representation. SEMAFOR 1.0 finds words that evoke FrameNet frames, selects frames for them, and locates the arguments for each frame. The system uses two feature-based, discriminative probabilistic (log-linear) models, one with latent variables to permit disambiguation of new predicate words. The parser is demonstrated to significantly outperform previously published results and is released for public use. @techreport{das-schneider-chen-smith-10-tr, author = {Dipanjan Das and Nathan Schneider and Desai Chen and Noah A. Smith}, institution = {Carnegie Mellon University}, address = {Pittsburgh, Pennsylvania}, type = {Technical Report}, number = {CMU-LTI-10-001}, title = {{SEMAFOR} 1.0: A Probabilistic Frame-Semantic Parser}, year = {2010}, month = apr, url = {http://cs.cmu.edu/~ark/SEMAFOR/das+schneider+chen+smith.tr10.pdf} } [software]
- Reza Bosagh Zadeh and Nathan Schneider (December 2008). Unsupervised approaches to sequence tagging, morphology induction, and lexical resource acquisition. LS2 course literature review. [paper] [slides] We consider unsupervised approaches to three types of problems involving the prediction of natural language information at or below the level of words: sequence labeling (including part-of-speech tagging); decomposition (morphological analysis and segmentation); and lexical resource acquisition (building dictionaries to encode linguistic knowledge about words within and across languages). We highlight the strengths and weaknesses of these approaches, including the extent of labeled data/resources assumed as input, the robustness of modeling techniques to linguistic variation, and the semantic richness of the output relative to the input.
Research
Overview
My research interests are in the intersection of linguistics, cognitive science, and computer science/artificial intelligence. Fundamentally, I want to be able to describe and simulate human and artificial language learning, understanding, and use.
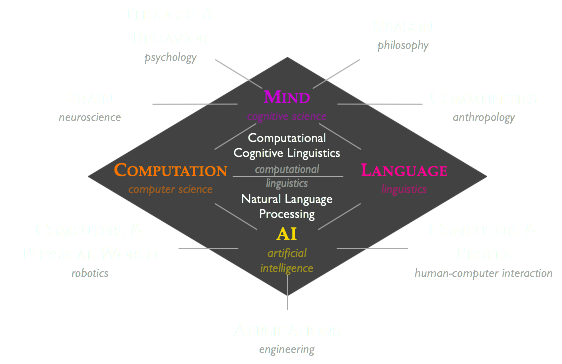
Reseach goals:
- understanding how languages convey meaning
- using computers to model, analyze, and reason about human language
- designing computer interfaces to exploit aspects of human cognition and artificial intelligence, including language processing
Specific problems of interest include:
- Statistical NLP: morphological, syntactic, and semantic parsing; machine translation; grammar learning; figurative language processing
- Cognitive linguistics: Construction Grammar; frame semantics; metaphor and metonymy; conceptual blending and mental spaces; usage-based theories of language learning
- Technology for linguistics: Use of technology to assist linguistic discovery and language revitalization
- Human-computer interaction: NLP-enabled user interfaces and information visualization
Frame-Semantic Parsing
The goal of this project was to build models to predict a sentence's frame-semantic structure. Predicting a frame-semantic parse involves finding and disambiguating frame-evoking expressions and matching roles of the evoked frames to arguments in the sentence. We have implemented a probabilistic frame parser for English which outperforms the previous state of the art.
- Probabilistic frame-semantic parsing (Das et al., NAACL 2010)
- Exploiting and expanding corpus resources for frame-semantic parsing (Schneider et al., IFNW 2013)
- Frame-semantic parsing (Das et al., CL 2014)
Arabic NLP
The AQMAR project (a collaboration with CMU's Qatar campus) aims to advance the state of the art in NLP for Arabic text. We will develop tools for linguistic structure analysis, especially named entity recognition (NER) and semantic tagging, for use in the NLP community, with emphasis on domains other than news (namely, topics found in Arabic Wikipedia).
- Recall-oriented learning of named entities in Arabic Wikipedia (Mohit et al., EACL 2012)
- Coarse lexical semantic annotation with supersenses: an Arabic case study (Schneider et al., ACL 2012)
- Supersense tagging for Arabic: the MT-in-the-middle attack (Schneider et al., NAACL-HLT 2013)
Exploring News Text
In 2008–2010 I worked on the RAVINE project, an effort combining NLP and information visualization technologies to build an interface facilitating efficient exploration and analysis of content from a large database of news articles. Our system scans articles to extract quotations (and their speakers) for display in an interactive graph. I have been primarily involved in designing the interface and in organizing a user study to evaluate its effectiveness.
Hebrew Morphology
Hebrew verbs use a root-and-pattern system, where a three-consonant root is lexicalized in one or more of seven verbal paradigms. Each verb, then, is a pairing of a root, a paradigm, and a meaning. An inflected verb's form is quite predictable, the meaning less so; many verbs have idiosyncratic meanings, but there are some regularities and tendencies which need to be accounted for, e.g. certain frequent alternations between paradigms for a common root. My analysis addresses the following questions:
- What are the forms and meanings of the morphological components of verbs—roots, paradigms, stems, and inflectional affixes?
- How do the forms and meanings of these constructions combine to yield actual verbs in sentences?
- How can these constructions be formalized in a structured representation that can be used for computational analysis?
I argue that construction grammar is an appropriate theoretical framework capable of accounting for the complexities of such a system. In particular, I use the Embodied Construction Grammar formalism to represent the necessary constructions in a manner suitable for automated analysis and simulation. Moreover, I argue that many features of the system are consistent with the notion of language as a best-fit cognitive phenomenon.
As part of an honors thesis under the supervision of Jerry Feldman, I designed a morphological extension to the Embodied Construction Grammar formalism and implemented this extension in the ECG parser.
- Computational Cognitive Morphosemantics: Modeling Morphological Compositionality in Hebrew Verbs with Embodied Construction Grammar (Schneider, BLS 2010)
- SLUgS Symposium abstract and slides
Other projects
Picurís Tagger
As a machine learning course project, in Fall 2007 I worked with fellow student Will Chang to develop a statistical model that would aid linguistic analysis of texts in Picurís, a Northern Tiwa language of New Mexico. A database of 28 stories in the language was compiled, and students in a recent linguistics course began the painstaking process of identifying the meanings of morphemes (meaning-bearing word fragments) in the texts.
Our model is a Hidden Markov Model over syllables; it predicts (a) the grouping of syllables within each word into morphemes (segmentation), and (b) a tag for each morpheme indicating its category/"part of speech" (classification). Trained with the EM algorithm, the model makes reasonable predictions with just a few labeled examples.
Metonymy Classification
For a course project in Spring 2007 I worked with Srini Narayanan on the problem of identifying whether a given verb was being used metonymically or not. I developed and tested a classifier for metonymic vs. literal sentences. Further work is needed in determining the semantic categories for a particular verb’s literal arguments.
Software
NLP Tools
Developer Tutorials
- Pythonathan: miscellaneous Python development tips
- String & Regular Expression Language Reference (Python, Java, Javascript, PHP, Ruby)
- Python 2.7 Format String Reference Guide
- Unix Text Processing Command Reference
- Git Command Overview
- ducttape: A Crash Course (in progress)
Education
Teaching
In Spring 2016 I am co-teaching INFR09028: Foundations in Natural Language Processing (FNLP), which introduces 3rd-year Edinburgh Informatics undergraduates to statistical NLP. Sharon Goldwater is the other instructor.
Graduate Coursework
During my Ph.D. at Carnegie Mellon University, I completed the following courses:
- Language & Statistics II (Noah Smith, Fall 2008)
- Grammar Formalisms (Lori Levin, Spring 2009)
- Information Extraction (William Cohen, Fall 2009)
- Reading the Web (Tom Mitchell, Fall 2009)
- Advanced NLP Seminar (Noah Smith, Spring 2009, Spring 2010, Spring 2011)
- NLP Lab (Spring 2009)
- Introduction to Computer Science Education (Leigh Ann Sudol, Jan.–Feb. 2010)
- Alternative Syntactic Theories: Construction Grammar (University of Pittsburgh, Yasuhiro Shirai, Fall 2008)
I served as the TA for:
- Advanced NLP Seminar (Noah Smith, Spring 2010)
- Natural Language Processing (Noah Smith, Spring 2011)
Undergraduate Coursework
In 2008 I graduated from the University of California, Berkeley with a double major in Computer Science and Linguistics. Courses included:
Computer Science
- Statistical Natural Language Processing
- Statistical Learning Theory: Graphical Models
- Practical Machine Learning
- Artificial Intelligence
- Algorithms
- Programming Languages and Compilers
- The Neural Basis of Thought and Language
Linguistics
- The Mind and Language
- Advanced Cognitive Linguistics
- Modern Hebrew Linguistics
- Syntax and Semanatics
- Comparative and Historical Linguistics
- Phonology and Morphology
- Phonetics
- The Neural Basis of Thought and Language
- Neural Theory of Language Seminar
Languages
- עיברית מודרנית (Modern Hebrew) – 4 semesters' worth
- français (French) – 1 semester
- العربِيّة (Arabic) – 1 semester
Other
- Linear Algebra and Differential Equations
- Constitutional Law of the United States: Civil Rights and Civil Liberties
High School
I attended Sycamore High School in Cincinnati, Ohio, where I studied computer science for four years, Modern Hebrew for three, and participated in the orchestra (violin), spring musicals (stage crew), academic quiz team, world affairs council, and Scrabble Club.
Potpourri
Trivia
- It is a little-known fact that my surname means daddy longlegs in German.
- Among my odder extraprofessional achievements are authoring a Wikipedia article (in Aug. 2004) and an Urban Dictionary entry (in Jul. 2013), violining my way onto a Delicious Pastries album, and inspiring a simple yet delicious cookie recipe.
Activities
Academic
Programming
My programming languages of choice are Python and Java; I've also used C, C++, C#, and Scheme. For the web I use JavaScript and PHP.
Extracurricular
I play violin in the All University Orchestra. I also enjoy table tennis.
As an undergraduate, I was involved with several student groups: the Cal Berkeley Democrats & Smart Ass, the Roosevelt Institution (now Roosevelt Institute Campus Network), the Cal Scrabble Club, and SLUgS.
Typography
My favorite fonts include: Zapf Humanist/Optima, Segoe UI, Perspective Sans, Georgia, and Lucida Bright.
Old resources for Windows XP: How to type in Hebrew on Windows, IPA keyboard layout for Windows
Random Unicode character:
Firefox Extensions
I have listed what to me are indispensible enhancements to the Firefox browsing experience, including:
- Adblock Plus
- Hide ads on web pages
- FireGestures
- Enables simple mouse movements for common browser actions
- Firebug
- Invaluable tool for web designers; includes a DOM browser, style information, and a JavaScript console
- Zotero
- This citation manager is priceless (good thing it's free!)—it imports citation information from online catalogs and electronic journals, stores snapshots of web pages, organizes notes and other metadata, and generates bibliographies/exports to BibTeX. I contributed a script which makes papers on the ACL Anthology visible to Zotero.
Links
- NACLO
- LanguageLog
- DailyKos
- NPR Legal Affairs stories
- Slashdot
- Planet Mozilla
- Piled Higher and Deeper, xkcd, Dinosaur Comics, Jim Borgman
- Milon Morfix מילון מורפיקס (Hebrew-English/English-Hebrew dictionary)