|
 |
 |
|
|
|
|
|
|
|
|
|
|
|
FACS (FPGA Accelerated Multiprocessor Cache Simulator) Group Members
Project Description Current architectural-level full-system software-based simulators (e.g. Virtutech Simics) are limited in throughput, especially when simulating multiprocessor systems. The slowdown becomes even higher when attaching additional modules to the simulator, such as cache simulators. Recent research in the field of hybrid simulation has greatly accelerated simulation using FPGAs (e.g. Protoflex ). This corresponds to arrow 1 in figure 1. However, attaching software-based modules (e.g. cache simulators) to FPGA-accelerated simulators greatly slows down the over-all simulation speed. The goal of this project is to develop a functional simulator of a multiprocessor cache using FPGAs, which corresponds to arrow 2 in figure 1. Our ultimate goal is to integrate our cache module with Protoflex on a BEE2 board . We will evaluate our success based on the speedup we get when compared to a purely software-based simulation. Project Poster - The project poster can be found here . 
Project Proposal - The full project proposal can be found here . Project Milestone Report - The project milestone report can be found here . Final Project Report - The final project report can be found here . Results Our current configuration simulates a piranha-based cache model for a 16-cpu multiprocessor. Each processor has two 64KByte 2-way set associative L1 caches for instruction and data. All 16 cpus share a common 16MByte 8-way set associative L2 cache. L1 & L2 cachelines are set to 64 bytes. For each L1 cache (both instruction and data) we maintain 5 counters that are stored in an single on-chip memory for all L1 caches. Enclosed in parentheses is the actual hardware counter number that stores each statistic.
To verify the correct behavior of our design we fed the same sequence of references to our hardware cache model and observed the HW statistics counters using Chipscope. Chipscope is a tool that allows real-time monitoring of FPGA signals. Below is a snapshot of Chipscope that shows the references being fed to our cache model as well as some of the response signals (Read, Hit, Upgrade): 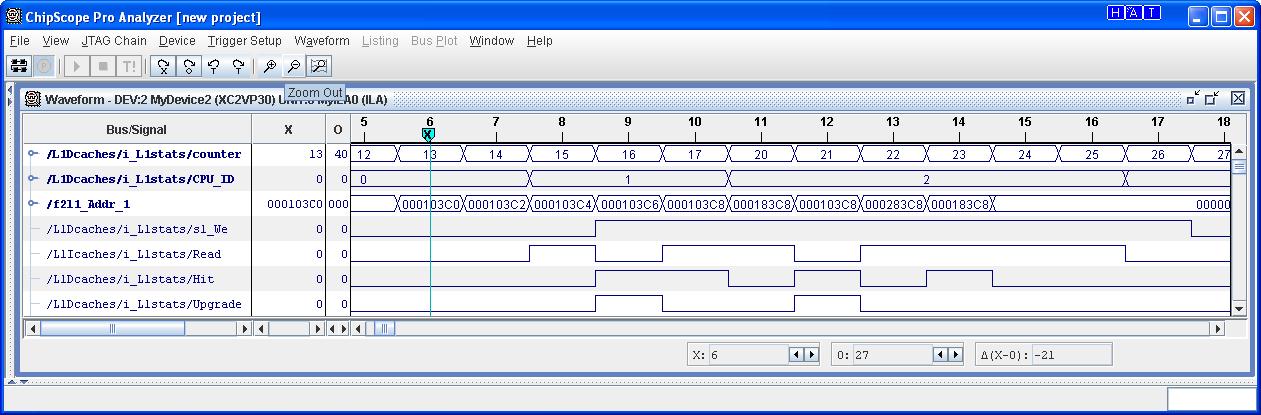
The next snapshot shows the gathered statistics for the L1 cache of CPU 1 and CPU 2, which match the expected results shown above. The first digit of the IdxR signal indicates the cache number, while the second digit indicates the which counter is being read. The DoutR signal is the specific counter value, which is delayed by 1 cycle with respect to IdxR. This delay happens because when reading a memory the data that is read corresponds to the address provided in the previous cycle. As an example the value DoutR value 4 belongs to the IdxR value 22, which corresponds to the Read Misses (HW counter 2) of CPU 2. 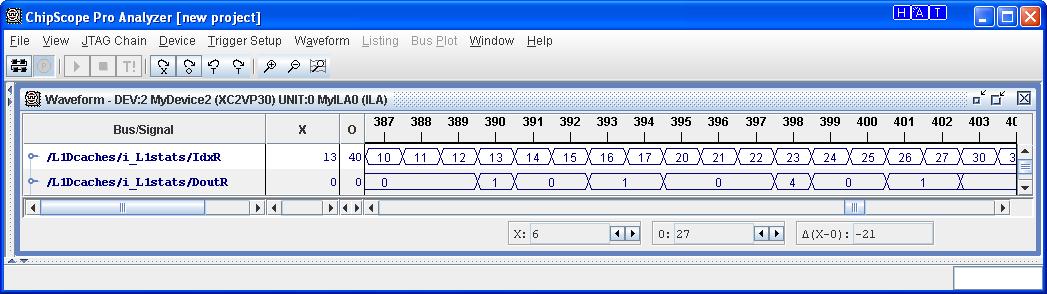
Obviously more complicated test cases where used to thorougly verify the correct behavior of our cache model. Below is a snapshot of the results of a sequence of 200 memory references that involve all 16 CPUs. The X axis corresponds to all of the available L1 statistics and the Y axis corresponds to the value of each statistics counter. (The statistics memory is continuously scanned which explains the repetitive nature of the graph). 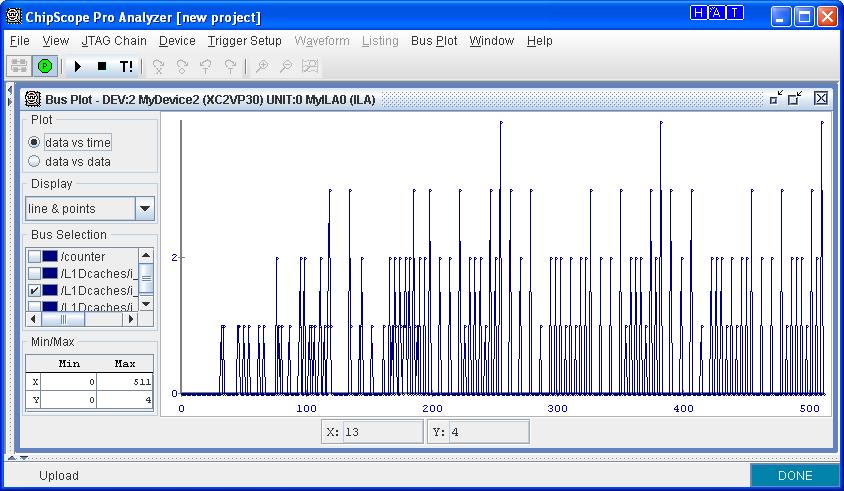
|
