Brian Ziebart |

|
I have moved to the Univ. of Illinois-Chicago. Please visit my new homepage.
Brian Ziebart |
|
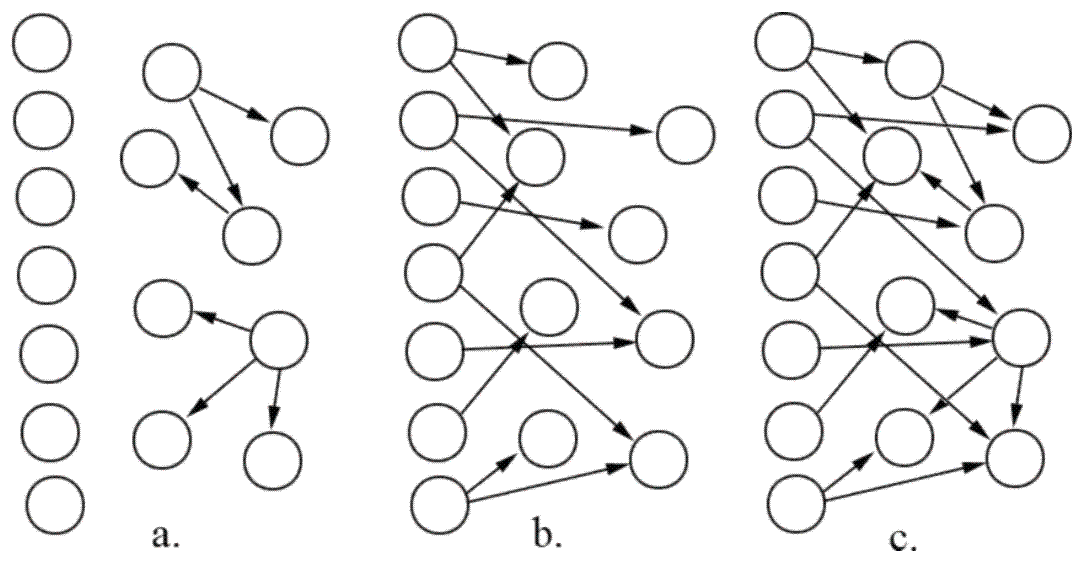
| In structure learning, the edges of a Bayesian network relating variables are learned from data. we present polynomial inference algorithms (MAP structure estimation and Bayesian model averaging) for selectively conditioned forests (c) -- the combination of tree structures (a) and ordered variable sets (b), enabling generalized naïve Bayes classifier learning in our UAI 2007 paper on selectively conditioned forests. |
|

 |
Probabilistic Pointing Target Prediction via Inverse Optimal
Control
Brian D. Ziebart, Anind K. Dey, and J. Andrew Bagnell International Conference on Intelligent User Interfaces (IUI 2012) [abstract] [pdf] [bibtex]
Abstract
Numerous interaction techniques have been developed that make "virtual" pointing at targets in graphical user interfaces easier than analogous physical pointing tasks by invoking target-based interface modifications. These pointing facilitation techniques crucially depend on methods for estimating the relevance of potential targets. Unfortunately, many of the simple methods employed to date are inaccurate in common settings with many selectable targets in close proximity. In this paper, we bring recent advances in statistical machine learning to bear on this underlying target relevance estimation problem. By framing past target-driven pointing trajectories as approximate solutions to well-studied control problems, we learn the probabilistic dynamics of pointing trajectories that enable more accurate predictions of intended targets.
Bibtex Best Paper Award Nominee
@inproceedings{ziebart2012probabilistic,
author = {Brian D. Ziebart and Anind K. Dey and J. Andrew Bagnell},
title = {Probabilistic Pointing Target Prediction via Inverse Optimal
Control},
year = {2012},
booktitle = {Proc. of the International Conference on Intelligent User
Interfaces}
}
|
|
 |
Factorized Decision Forecasting via Combining Value-based and
Reward-based Estimation
Brian D. Ziebart Allerton Conference on Communication, Control and Computing (Allerton 2011) [abstract] [pdf] [bibtex]
Abstract
A powerful recent perspective for predicting sequential decisions learns the parameters of decision problems that produce observed behavior as (near) optimal solutions. Under this perspective, behavior is explained in terms of utilities, which can often be defined as functions of state and action features to enable generalization across decision tasks. Two approaches have been proposed from this perspective: estimate a feature-based reward function and recursively compute values from it, or directly estimate a feature-based value function. In this work, we investigate the combination of these two approaches into a single learning task using directed information theory and the principle of maximum entropy. This enables uncovering which type of estimate is most appropriate -- in terms of predictive accuracy and/or computational benefit -- for different portions of the decision space.
Bibtex @inproceedings{ziebart2011process,
author = {Brian D. Ziebart},
title = {Factorized Decision Forecasting via Combining Value-based
and Reward-based Estimation},
year = {2011},
booktitle = {Proc. of the Allerton Conference on Communications,
Control and Computing}
}
|
|
 |
Process-Conditioned Investing with Incomplete Information
using Maximum Causal Entropy
Brian D. Ziebart International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering (MaxEnt 2011) [abstract] [pdf] [bibtex]
Abstract
Investing to optimally maximize the growth rate of wealth based on sequences of event outcomes has many information-theoretic interpretations. Namely, the mutual information characterizes the benefit of additional side information being available when making investment decisions in settings where the probabilistic relationships between side information and event outcomes are known. Additionally, the relative variant of the principle of maximum entropy provides the optimal investment allocation in the more general setting where the relationships between side information and event outcomes are only partially known. In this paper, we build upon recent work characterizing the growth rates of investment in settings with inter-dependent side information and event outcome sequences. We consider the extension to settings with inter-dependent event outcomes and side information where the probabilistic relationships between side information and event outcomes are only partially known. We introduce the principle of minimum relative causal entropy to obtain the optimal worst-case investment allocations for this setting. We present efficient algorithms for obtaining these investment allocations using convex optimization techniques and dynamic programming that illustrates a close connection to optimal control theory.
Bibtex @inproceedings{ziebart2011process,
author = {Brian D. Ziebart},
title = {Process-Conditioned Investing with Incomplete Information
using Maximum Causal Entropy},
year = {2011},
booktitle = {Proc. of the International Workshop on Bayesian Inference and
Maximum Entropy Methods in Science and Engineering}
}
|
|
 |
Computational Rationalization: The Inverse Equilibrium
Problem
Kevin Waugh, Brian D. Ziebart, and J. Andrew Bagnell International Conference on Machine Learning (ICML 2011). [abstract] [pdf] [bibtex] Best Paper Award (An earlier version appeared in Workshop on Decision Making with Multiple Imperfect Decision Makers at NIPS 2010.)
Abstract
Modeling the purposeful behavior of imperfect agents from a small number of observations is a challenging task. When restricted to the single-agent decision-theoretic setting, inverse optimal control techniques assume that observed behavior is an approximately optimal solution to an unknown decision problem. These techniques learn a utility function that explains the example behavior and can then be used to accurately predict or imitate future behavior in similar observed or unobserved situations. In this work, we consider similar tasks in competitive and cooperative multi-agent domains. Here, unlike single-agent settings, a player cannot myopically maximize its reward -- it must speculate on how the other agents may act to influence the game's outcome. Employing the game-theoretic notion of regret and the principle of maximum entropy, we introduce a technique for predicting and generalizing behavior, as well as recovering a reward function in these domains.
Bibtex @inproceedings{waugh2011computational,
author = {Kevin Waugh and Brian D. Ziebart and J. Andrew Bagnell},
title = {Computational Rationalization: The Inverse Equilibrium Problem},
year = {2011},
booktitle = {Proc. of the International Conference on Machine Learning}
}
|
|
 |
Maximum Causal Entropy Correlated Equilibria for
Markov Games
Brian D. Ziebart, J. Andrew Bagnell, and Anind K. Dey International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2011). [abstract] [pdf] [bibtex] (An earlier version appeared in the Interactive Decision Theory and Game Theory Workshop at AAAI 2010.)
Abstract
Motivated by a machine learning perspective -- that game-theoretic equilibria constraints should serve as guidelines for predicting agents' strategies, we introduce maximum causal entropy correlated equilibria (MCECE), a novel solution concept for general-sum Markov games. In line with this perspective, a MCECE strategy profile is a uniquely-defined joint probability distribution over actions for each game state that minimizes the worst-case prediction of agents' actions under log-loss. Equivalently, it maximizes the worst-case growth rate for gambling on the sequences of agents' joint actions under uniform odds. We present a convex optimization technique for obtaining MCECE strategy profiles that resembles value iteration in finite-horizon games. We assess the predictive benefits of our approach by predicting the strategies generated by previously proposed correlated equilibria solution concepts, and compare against those previous approaches on that same prediction task.
Bibtex @inproceedings{ziebart2011maximum,
author = {Brian D. Ziebart and J. Andrew Bagnell and Anind K. Dey},
title = {Maximum Causal Entropy Correlated Equilibria for {M}arkov Games},
year = {2011},
booktitle = {Proc. of the International Conference on Autonomous Agents
and Multiagent Systems}
}
|
|
 |
Learning Patterns of Pick-ups and Drop-offs to Support Busy
Family Coordination
Scott Davidoff, Brian D. Ziebart, John Zimmerman, and Anind K. Dey SIG CHI Conference on Human Factors in Computing Systems (CHI 2011). [abstract] [pdf] [bibtex]
Abstract
Part of being a parent is taking responsibility for arranging and supplying transportation of children between various events. Dual-income parents frequently develop routines to help manage transportation with a minimal amount of attention. On days when families deviate from their routines, effective logistics can often depend on knowledge of the routine location, availability and intentions of other family members. Since most families rarely document their routine activities, making that needed information unavailable, coordination breakdowns are much more likely to occur. To address this problem we demonstrate the feasibility of learning family routines using mobile phone GPS. We describe how we (1) detect pick-ups and drop- offs; (2) predict which parent will perform a future pick-up or drop-off; and (3) infer if a child will be left at an activity. We discuss how these routine models give digital calendars, reminder and location systems new capabilities to help prevent breakdowns, and improve family life.
Bibtex @inproceedings{davidoff2011learning,
author = {Scott Davidoff and Brian D. Ziebart and John Zimmerman and
Anind K. Dey},
title = {Learning Patterns of Pick-ups and Drop-offs to Support Busy
Family Coordination},
year = {2011},
booktitle = {Proc. of the SIG CHI Conference on Human Factors in Computing
Systems}
}
|
|
 |
Modeling Purposeful Adaptive Behavior with
the Principle of Maximum Causal Entropy
Brian D. Ziebart PhD Thesis. Department of Machine Learning. December 2010. [abstract] [pdf] [bibtex] School of Computer Science Distinguished Dissertation Award, Honorable Mention
Abstract
Predicting human behavior from a small amount of training examples is a challenging machine learning problem. In this thesis, we introduce the principle of maximum causal entropy, a general technique for applying information theory to decision-theoretic, game-theoretic, and control settings where relevant information is sequentially revealed over time. This approach guarantees decision-theoretic performance by matching purposeful measures of behavior (Abbeel & Ng, 2004), and/or enforces game-theoretic rationality constraints (Aumann, 1974), while otherwise being as uncertain as possible, which minimizes worst-case predictive log-loss (Grunwald & Dawid, 2003). We derive probabilistic models for decision, control, and multi-player game settings using this approach. We then develop corresponding algorithms for efficient inference that include relaxations of the Bellman equation (Bellman, 1957), and simple learning algorithms based on convex optimization. We apply the models and algorithms to a number of behavior prediction tasks. Specifically, we present empirical evaluations of the approach in the domains of vehicle route preference modeling using over 100,000 miles of collected taxi driving data, pedestrian motion modeling from weeks of indoor movement data, and robust prediction of game play in stochastic multi-player games.
Bibtex @phdthesis{ziebart2010modelingB},
author = {Brian D. Ziebart},
title = {Modeling Purposeful Adaptive Behavior with the Principle of
Maximum Causal Entropy},
year = {2010},
month = {Dec},
school = {Machine Learning Department, Carnegie Mellon University}
}
|
|
 |
Modeling Interaction via the Principle of Maximum Causal Entropy
Brian D. Ziebart, J. Andrew Bagnell, and Anind K. Dey International Conference on Machine Learning (ICML 2010). [abstract] [pdf] [bibtex] Best Student Paper Award, Runner-Up (An earlier version appeared in Workshop on Probabilistic Approaches for Robotics and Control at NIPS 2009.)
Abstract
The principle of maximum entropy provides a powerful framework for statistical models of joint, conditional, and marginal distributions. However, there are many important distributions with elements of interaction and feedback where its applicability has not been established. This work presents the principle of maximum causal entropy -- an approach based on causally conditioned probabilities that can appropriately model the availability and influence of sequentially revealed side information. Using this principle, we derive Maximum Causal Entropy Influence Diagrams, a new probabilistic graphical framework for modeling decision making in settings with latent information, sequential interaction, and feedback. We describe the theoretical advantages of this model and demonstrate its applicability for statistically framing inverse optimal control and decision prediction tasks.
Bibtex
@inproceedings{ziebart2010modeling,
author = {Brian D. Ziebart and J. Andrew Bagnell and Anind K. Dey},
title = {Modeling Interaction via the Principle of Maximum Causal Entropy},
year = {2010},
booktitle = {Proc. of the International Conference on Machine Learning},
pages = {1255--1262}
}
|
|
 |
Planning-based Prediction for Pedestrians Brian D. Ziebart, Nathan Ratliff, Garratt Gallagher, Christoph Mertz, Kevin Peterson, J. Andrew Bagnell, Martial Hebert, A K. Dey, Siddhartha Srinivasa International Conference on Intelligent Robots and Systems (IROS 2009). [abstract] [pdf] [bibtex]
Abstract
We present a novel approach for determining robot movements that efficiently accomplish the robot's tasks while not hindering the movements of people within the environment. Our approach models the goal-directed trajectories of pedestrians using maximum entropy inverse optimal control. The advantage of this modeling approach is the generality of its learned cost function to changes in the environment and to entirely different environments. We employ the predictions of this model of pedestrian trajectories in a novel incremental planner and quantitatively show the improvement in hindrance- sensitive robot trajectory planning provided by our approach.
Bibtex @inproceedings{bziebart2009planning,
author = {Brian D. Ziebart and Nathan Ratliff and Garratt Gallagher and
Christoph Mertz and Kevin Peterson and J. Andrew Bagnell and
Martial Hebert and Anind K. Dey and Siddhartha Srinivasa},
title = {Planning-based Prediction for Pedestrians},
year = {2009},
booktitle = {Proc. of the International Conference on Intelligent Robotsi
and Systems}
}
|
|

|
Inverse Optimal Heuristic Control for Imitation Learning Nathan Ratliff, Brian D. Ziebart, Kevin Peterson, J. Andrew Bagnell, Martial Hebert, Anind K. Dey, Siddhartha Srinivasa Artificial Intelligence and Statistics (AISTATS 2009). [abstract] [pdf] [bibtex]
Abstract
One common approach to imitation learning is behavioral cloning (BC), which employs straight- forward supervised learning (i.e., classification) to directly map observations to controls. A second approach is inverse optimal control (IOC), which formalizes the problem of learning sequential decision-making behavior over long horizons as a problem of recovering a utility function that explains observed behavior. This paper presents inverse optimal heuristic control (IOHC), a novel approach to imitation learning that capitalizes on the strengths of both paradigms. It employs long-horizon IOC-style modeling in a low-dimensional space where inference remains tractable, while incorporating an additional descriptive set of BC-style features to guide a higher-dimensional overall action selection. We provide experimental results demonstrating the capabilities of our model on a simple illustrative problem as well as on two real world problems: turn-prediction for taxi drivers, and pedestrian prediction within an office environment.
Bibtex @inproceedings{ratliff2009inverse,
author = {Nathan Ratliff and Brian Ziebart and Kevin Peterson and
J. Andrew Bagnell and Martial Hebert and Anind K. Dey and
Siddhartha Srinivasa},
title = {Inverse Optimal Heuristic Control for Imitation Learning},
year = {2009},
booktitle = {Proc. AISTATS},
pages = {424--431}
}
|
|

|
Human Behavior Modeling with Maximum Entropy Inverse Optimal
Control Brian D. Ziebart, Andrew Maas, J. Andrew Bagnell, Anind K. Dey AAAI Spring Symposium on Human Behavior Modeling. 2009. [pdf] |
|

|
Navigate Like a Cabbie: Probabilistic Reasoning from Observed
Context-Aware Behavior Brian D. Ziebart, Andrew Maas, Anind K. Dey, and J. Andrew Bagnell. International Conference on Ubiquitous Computing (Ubicomp 2008). [abstract] [pdf] [bibtex]
Abstract
We present PROCAB, an efficient method for Probabilistically Reasoning from Observed Context-Aware Behavior. It models the context-dependent utilities and underlying reasons that people take different actions. The model generalizes to unseen situations and scales to incorporate rich contextual information. We train our model using the route preferences of 25 taxi drivers demonstrated in over 100,000 miles of collected data, and demonstrate the performance of our model by inferring: (1) decision at next intersection, (2) route to known destination, and (3) destination given partially traveled route.
Bibtex
@inproceedings{bziebart2008navigate,
author = {Brian D. Ziebart and Andrew Maas
and J. Andrew Bagnell and Anind K. Dey},
title = {Navigate Like a Cabbie: Probabilistic Reasoning from
Observed Context-Aware Behavior},
year = {2008},
booktitle = {Proc. Ubicomp},
pages = {322--331}
}
|
|

|
Fast Planning for Dynamic Preferences Brian D. Ziebart, Anind K. Dey, and J. Andrew Bagnell. International Conference on Automated Planning and Scheduling (ICAPS 2008). [abstract] [pdf] [bibtex]
Abstract
We present an algorithm that quickly finds optimal plans for unforeseen agent preferences within graph-based planning domains where actions have deterministic outcomes and action costs are linearly parameterized by preference parameters. We focus on vehicle route planning for drivers with personal trade-offs for different types of roads, and specifically on settings where these preferences are not known until planning time. We employ novel bounds (based on the triangle inequality and on the the concavity of the optimal plan cost in the space of preferences) to enable the reuse of previously computed optimal plans that are similar to the new plan preferences. The resulting lower bounds are employed to guide the search for the optimal plan up to 60 times more efficiently than previous methods.
Bibtex
@inproceedings{ziebart2008fast,
author = {Brian D. Ziebart and J. Andrew Bagnell and Anind K. Dey},
title = {Fast Planning for Dynamic Preferences},
year = {2008},
booktitle = {Proc. of International Conference on Auomated Planning
and Scheduling},
pages = {412--419}
}
|
|
 |
Maximum Entropy Inverse Reinforcement Learning Brian D. Ziebart, Andrew Maas, J. Andrew Bagnell, and Anind K. Dey. AAAI Conference on Artificial Intelligence (AAAI 2008). [abstract] [pdf] [bibtex] (An earlier version appeared in Workshop on Robotic Challenges for Machine Learning at NIPS 2007.)
Abstract
Recent research has shown the benefit of framing problems of imitation learning as solutions to Markov Decision Problems. This approach reduces learning to the problem of recovering a utility function that makes the behavior induced by a near-optimal policy closely mimic demonstrated behavior. In this work, we develop a probabilistic approach based on the principle of maximum entropy. Our approach provides a well-defined, globally normalized distribution over decision sequences, while providing the same performance guarantees as existing methods. We develop our technique in the context of modeling real-world navigation and driving behaviors where collected data is inherently noisy and imperfect. Our probabilistic approach enables modeling of route preferences as well as a powerful new approach to inferring destinations and routes based on partial trajectories.
Bibtex
@inproceedings{ziebart2008maximum,
author = {Brian D. Ziebart and Andrew Maas
and J. Andrew Bagnell and Anind K. Dey},
title = {Maximum Entropy Inverse Reinforcement Learning},
year = {2008},
booktitle = {Proc. AAAI},
pages = {1433--1438}
}
|
|
 |
Learning Selectively Conditioned Forest Structures with
Applications to DBNs and Classification Brian D. Ziebart, Anind K. Dey, and J. Andrew Bagnell. Uncertainty in Artificial Intelligence (UAI 2007). [abstract] [pdf] [bibtex]
Abstract
Dealing with uncertainty in Bayesian Network structures using maximum a posteriori (MAP) estimation or Bayesian Model Averaging (BMA) is often intractable due to the superexponential number of possible directed, acyclic graphs. When the prior is decomposable, two classes of graphs where efficient learning can take place are tree-structures, and fixed-orderings with limited in-degree. We show how MAP estimates and BMA for selectively conditioned forests (SCF), a combination of these two classes, can be computed efficiently for ordered sets of variables. We apply SCFs to temporal data to learn Dynamic Bayesian Networks having an intra-timestep forest and inter-timestep limited in-degree structure, improving model accuracy over DBNs without the combination of structures. We also apply SCFs to Bayes Net classification to learn selective forest-augmented Naive Bayes classifiers. We argue that the built-in feature selection of selective augmented Bayes classifiers makes them preferable to similar non-selective classifiers based on empirical evidence.
Bibtex
@inproceedings{bziebart2007learning,
author = {Brian D. Ziebart and Anind K. Dey and J. Andrew Bagnell},
title = {Learning Selectively Conditioned Forest Structures with
Applications to DBNs and Classification},
year = {2007},
booktitle = {Proc. UAI},
pages = {458--465}
}
|
|
 |
Learning
Automation Policies for Pervasive Computing Environments
Brian D. Ziebart, Dan Roth, Roy H. Campbell, and Anind K. Dey. IEEE International Conference on Autonomic Computing (ICAC 2005). [abstract] [pdf] [bibtex]
Abstract
If current trends in cellular phone technology, personal digital assistants, and wireless networking are indicative of the future, we can expect our environments to contain an abundance of networked computational devices and resources. We envision these devices acting in an orchestrated manner to meet users' needs, pushing the level of interaction away from particular devices and towards interactions with the environment as a whole. Computation will be based not only on input explicitly provided by the user, but also on contextual information passively collected by networked sensing devices. Configuring the desired responses to different situations will need to be easy for users. However, we anticipate that the triggering situations for many desired automation policies will be complex, unforeseen functions of low-level contextual information. This is problematic since users, though easily able to perceive triggering situations, will not be able to define them as functions of the devices' available contextual information, even when such a function (or a close approximation) does exist. In this paper, we present an alternative approach for specifying the automation rules of a pervasive computing environment using machine learning techniques. Using this approach, users generate training data for an automation policy through demonstration, and, after training is completed, a learned function is employed for future automation. This approach enables users to automate the environment based on changes in the environment that are complex, unforeseen combinations of contextual information. We developed our learning service within Gaia, our pervasive computing system, and deployed it within our prototype pervasive computing environment. Using the system, we were able to have users demonstrate how sound and lighting controls should adjust to different applications used within the environment, the users present, and the locations of those users and then automate those demonstrated preferences.
Bibtex
@inproceedings{bziebart2005learning,
author = {Brian D. Ziebart and Dan Roth and Roy H. Campbell and
Anind K. Dey},
title = {Learning Automation Policies for Pervasive Computing Environments},
year = {2005},
booktitle = {Proc. of the International Conference on Autonomic Computing}
}
|
|

|
Towards a Pervasive Computing Benchmark Anand Ranganathan, Jalal Al-Muhtadi, Jacob Biehl, Brian Ziebart, Roy H. Campbell, and Brian Bailey. PerWare '05 Workshop on Support for Pervasive Computing at PerCom 2005. [pdf] |
|

|
System Support for Rapid Ubiquitous Computing Application
Development and Evaluation Manuel Roman, Jalal Al-Muhtadi, Brian Ziebart, and Roy H. Campbell. Systems Support for Ubiquitous Computing Workshop, at UbiComp 2003. [pdf] |
|

|
Dynamic Application Composition: Customizing the Behavior of an
Active Space Manuel Roman, Brian Ziebart, and Roy H. Campbell. IEEE International Conference on Pervasive Computing and Communications (PerCom 2003). [pdf] |