Based on the theoretical considerations of
Section 2.1, we know that the crucial element of the
algorithm is converging on a good approximation of the optimal
importance function. In what follows, we first give the optimal
importance function for calculating
Pr(![]() =
= ![]() ) and
then discuss how to use the structural advantages of Bayesian
networks to approximate this function. In the sequel, we will use
the symbol
) and
then discuss how to use the structural advantages of Bayesian
networks to approximate this function. In the sequel, we will use
the symbol ![]() to denote the importance sampling function and
to denote the importance sampling function and
![]() to denote the optimal importance sampling function.
to denote the optimal importance sampling function.
Since
Pr(![]() \
\![]() ,
,![]() =
= ![]() ) > 0, from
Corollary 1 we have
) > 0, from
Corollary 1 we have
 = Pr(
= Pr(
Although we know the mathematical expression for the optimal importance sampling function, it is difficult to obtain this function exactly. In our algorithm, we use the following importance sampling function
This function partially considers the effect of all the evidence on every node during the sampling process. When the network structure is the same as that of the network which has absorbed the evidence, this function is the optimal importance sampling function. It is easy to learn and, as our experimental results show, it is a good approximation to the optimal importance sampling function. Theoretically, when the posterior structure of the model changes drastically as the result of observed evidence, this importance sampling function may perform poorly. We have tried to find practical networks where this would happen, but to the day have not encountered a drastic example of this effect.
From Section 2.2, we know that the score sums
corresponding to
{xi,pa(Xi),![]() } can yield an unbiased
estimator of
Pr(xi,pa(Xi),
} can yield an unbiased
estimator of
Pr(xi,pa(Xi),![]() ). According to the
definition of conditional probability, we can get an estimator of
Pr
). According to the
definition of conditional probability, we can get an estimator of
Pr![]() (xi|pa(Xi),
(xi|pa(Xi),![]() ). This can be achieved by
maintaining an updating table for every node, the structure of
which mimicks the structure of the CPT. Such tables allow us to
decompose the above importance function into components that can
be learned individually. We will call these tables the importance conditional probability tables (ICPT).
). This can be achieved by
maintaining an updating table for every node, the structure of
which mimicks the structure of the CPT. Such tables allow us to
decompose the above importance function into components that can
be learned individually. We will call these tables the importance conditional probability tables (ICPT).
Proof: Suppose we have set the values of all the parents of node
Xi to
pa(Xi). Node Xi is dependent on evidence ![]() given
pa(Xi) only when Xi is d-connecting with
given
pa(Xi) only when Xi is d-connecting with ![]() given
pa(Xi) [Pearl1988]. According to the definition
of d-connectivity, this happens only when there exists a member
of Xi's descendants that belongs to the set of evidence nodes
given
pa(Xi) [Pearl1988]. According to the definition
of d-connectivity, this happens only when there exists a member
of Xi's descendants that belongs to the set of evidence nodes
![]() . In other words
Xi
. In other words
Xi![]() Anc(
Anc(![]() ).
). ![]()
Theorem 2 is very important for the AIS-BN algorithm. It states essentially that the ICPT tables of those nodes that are not ancestors of the evidence nodes are equal to the CPT tables throughout the learning process. We only need to learn the ICPT tables for the ancestors of the evidence nodes. Very often this can lead to significant savings in computation. If, for example, all evidence nodes are root nodes, we have our ICPT tables for every node already and the AIS-BN algorithm becomes identical to the likelihood weighting algorithm. Without evidence, the AIS-BN algorithm becomes identical to the probabilistic logic sampling algorithm.
It is worth pointing out that for some Xi,
Pr(Xi| Pa(Xi),![]() ) (i.e., the ICPT table for
Xi), can be easily calculated using exact methods. For example,
when Xi is the only parent of an evidence node Ej and Ej
is the only child of Xi, the posterior probability distribution
of Xi is straightforward to compute exactly. Since the focus of
the current paper is on sampling, the test results reported in
this paper do not include this improvement of the AIS-BN
algorithm.
) (i.e., the ICPT table for
Xi), can be easily calculated using exact methods. For example,
when Xi is the only parent of an evidence node Ej and Ej
is the only child of Xi, the posterior probability distribution
of Xi is straightforward to compute exactly. Since the focus of
the current paper is on sampling, the test results reported in
this paper do not include this improvement of the AIS-BN
algorithm.
Figure 3 lists an algorithm that implements Step 7
of the basic AIS-BN algorithm listed in Figure 2. When
we estimate
Pr![]() (xi|pa(Xi),
(xi|pa(Xi),![]() ), we only use
the samples obtained at the current stage. One reason for this is
that the information obtained in previous stages has been absorbed
by
Prk(
), we only use
the samples obtained at the current stage. One reason for this is
that the information obtained in previous stages has been absorbed
by
Prk(![]() \
\![]() ). The other reason is that
in principle, each successive iteration is more accurate than the
previous one and the importance function is closer to the optimal
importance function. Thus, the samples generated by
Prk + 1(
). The other reason is that
in principle, each successive iteration is more accurate than the
previous one and the importance function is closer to the optimal
importance function. Thus, the samples generated by
Prk + 1(![]() \
\![]() ) are better than those
generated by
Prk(
) are better than those
generated by
Prk(![]() \
\![]() ).
Pr
).
Pr![]() (Xi|pa(Xi),
(Xi|pa(Xi),![]() ) - Prk(Xi|pa(Xi),
) - Prk(Xi|pa(Xi),![]() ) corresponds to the vector of first partial derivatives in the
direction of the maximum decrease in the error.
) corresponds to the vector of first partial derivatives in the
direction of the maximum decrease in the error. ![]() (k) is a
positive function that determines the learning rate. When
(k) is a
positive function that determines the learning rate. When
![]() (k) = 0 (lower bound), we do not update our importance
function. When
(k) = 0 (lower bound), we do not update our importance
function. When ![]() (k) = 1 (upper bound), at each stage we discard
the old function. The convergence speed is directly related to
(k) = 1 (upper bound), at each stage we discard
the old function. The convergence speed is directly related to
![]() (k). If it is small, the convergence will be very slow due
to the large number of updating steps needed to reach a local
minimum. On the other hand, if it is large, convergence rate will
be initially very fast, but the algorithm will eventually start to
oscillate and thus may not reach a minimum. There are many papers
in the field of neural network learning that discuss how to choose
the learning rate and let estimated importance function converge
quickly to the destination function. Any method that can improve
learning rate should be applicable to this algorithm. Currently,
we use the following function proposed by Ritter et al.
[1991]
(k). If it is small, the convergence will be very slow due
to the large number of updating steps needed to reach a local
minimum. On the other hand, if it is large, convergence rate will
be initially very fast, but the algorithm will eventually start to
oscillate and thus may not reach a minimum. There are many papers
in the field of neural network learning that discuss how to choose
the learning rate and let estimated importance function converge
quickly to the destination function. Any method that can improve
learning rate should be applicable to this algorithm. Currently,
we use the following function proposed by Ritter et al.
[1991]
![\fbox{
\parbox{5.3in}{
\renewedcommand{baselinestretch}{1.0}
\begin{minipage}[t]...
...i),{\bf e})\right)
\end{eqnarray*}\end{enumerate}{\bf end for}
\end{minipage}}}](img86.gif)
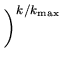 ,
,