In the following discussion, all random variables used are
multiple-valued, discrete variables. Capital letters, such as A,
B, or C, denote random variables. Bold capital letters, such
as ![]() ,
, ![]() , or
, or ![]() , denote sets of variables.
Bold capital letter
, denote sets of variables.
Bold capital letter ![]() will usually be used to denote the
set of evidence variables. Lower case letters a, b, c denote
particular instantiations of variables A, B, and C
respectively. Bold lower case letters, such as
will usually be used to denote the
set of evidence variables. Lower case letters a, b, c denote
particular instantiations of variables A, B, and C
respectively. Bold lower case letters, such as ![]() ,
, ![]() ,
, ![]() , denote particular instantiations of sets
, denote particular instantiations of sets ![]() ,
, ![]() , and
, and ![]() respectively. Bold lower case letter
respectively. Bold lower case letter
![]() , in particular, will be used to denote the observations,
i.e., instantiations of the set of evidence variables
, in particular, will be used to denote the observations,
i.e., instantiations of the set of evidence variables ![]() .
Anc(A) denotes the set of ancestors of node A.
Pa(A)
denotes the set of parents (direct ancestors) of node A.
pa(A) denotes a particular instantiation of
Pa(A).
\ denotes set difference.
.
Anc(A) denotes the set of ancestors of node A.
Pa(A)
denotes the set of parents (direct ancestors) of node A.
pa(A) denotes a particular instantiation of
Pa(A).
\ denotes set difference.
![]() Pa(A)
Pa(A)![]() denotes that we
use the extended vertical bar to indicate substitution of
e for
E in
A.
denotes that we
use the extended vertical bar to indicate substitution of
e for
E in
A.
We know that the joint probability distribution over all variables
of a Bayesian network model,
Pr(![]() ), is the product of
the probability distributions over each of the nodes conditional
on their parents, i.e.,
), is the product of
the probability distributions over each of the nodes conditional
on their parents, i.e.,
While there has been previous work on importance sampling-based algorithms for Bayesian networks, we will postpone the discussion of this work until the next section. Here we will present a generic stochastic sampling algorithm that will help us in both reviewing the prior work and in presenting our algorithm.
The posterior probability
Pr(![]() |
|![]() ) can be obtained
by first computing
Pr(
) can be obtained
by first computing
Pr(![]() ,
,![]() ) and
Pr(
) and
Pr(![]() )
and then combining these based on the definition of conditional
probability
)
and then combining these based on the definition of conditional
probability
Figure 1 presents a generic stochastic sampling
algorithm that captures most of the existing sampling algorithms.
Without the loss of generality, we restrict ourselves in our
description to so-called forward sampling, i.e., generation
of samples in the topological order of the nodes in the network.
The forward sampling order is accomplished by the initialization
performed in Step 1, where parents of each node are placed before
the node itself. In forward sampling, Step 8 of the algorithm, the
actual generation of samples, works as follows. (i) each
evidence node is instantiated to its observed state and is further
omitted from sample generation; (ii) each root node is
randomly instantiated to one of its possible states, according to
the importance prior probability of this node, which can be
derived from
Prk(![]() \
\![]() ); (iii) each
node whose parents are instantiated is randomly instantiated to
one of its possible states, according to the importance
conditional probability distribution of this node given the values
of the parents, which can also be derived from
Prk(
); (iii) each
node whose parents are instantiated is randomly instantiated to
one of its possible states, according to the importance
conditional probability distribution of this node given the values
of the parents, which can also be derived from
Prk(![]() \
\![]() ); (iv) this procedure is followed until
all nodes are instantiated. A complete instantiation
); (iv) this procedure is followed until
all nodes are instantiated. A complete instantiation ![]() of the network based on this method is one sample of the joint
importance probability distribution
Prk(
of the network based on this method is one sample of the joint
importance probability distribution
Prk(![]() \
\![]() ) over all variables of the network. The scoring of Step 10
amounts to calculating
Pr(
) over all variables of the network. The scoring of Step 10
amounts to calculating
Pr(![]() ,
,![]() )/Prk(
)/Prk(![]() ), as required by Equation 2. The ratio
between the total score sum and the number of samples is an
unbiased estimator of
Pr(
), as required by Equation 2. The ratio
between the total score sum and the number of samples is an
unbiased estimator of
Pr(![]() ). In Step 10, if we also
count the score sum under the condition
). In Step 10, if we also
count the score sum under the condition
![]() =
= ![]() , i.e.,
that some unobserved variables
, i.e.,
that some unobserved variables ![]() have the values
have the values ![]() , the ratio between this score sum and the number of samples is
an unbiased estimator of
Pr(
, the ratio between this score sum and the number of samples is
an unbiased estimator of
Pr(![]() ,
,![]() ).
).
Most existing algorithms focus on the posterior probability
distributions of individual nodes. As we mentioned above, for the
sake of efficiency they count the score sum corresponding to
Pr(A = a,![]() ),
A
),
A ![]()
![]() \
\![]() , and record
it in an score array for node A. Each entry of this array
corresponds to a specified state of A. This method introduces
additional variance, as opposed to using the importance function
derived from
Prk(
, and record
it in an score array for node A. Each entry of this array
corresponds to a specified state of A. This method introduces
additional variance, as opposed to using the importance function
derived from
Prk(![]() \
\![]() ) to sample
Pr(A = a,
) to sample
Pr(A = a,![]() ), A
), A
![]()
![]() \
\![]() ,
directly.
,
directly.
![\fbox{
\parbox{5.3in}{
\renewedcommand{baselinestretch}{1.0}
\begin{minipage}[t]...
...item
Normalize the score arrays for every node.
\end{enumerate}\end{minipage}}}](img61.gif)
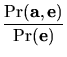 .
.