
Design practical AIs that can help users in complex tasks, where users are not oracle, and not static.
Recent Publications
2026



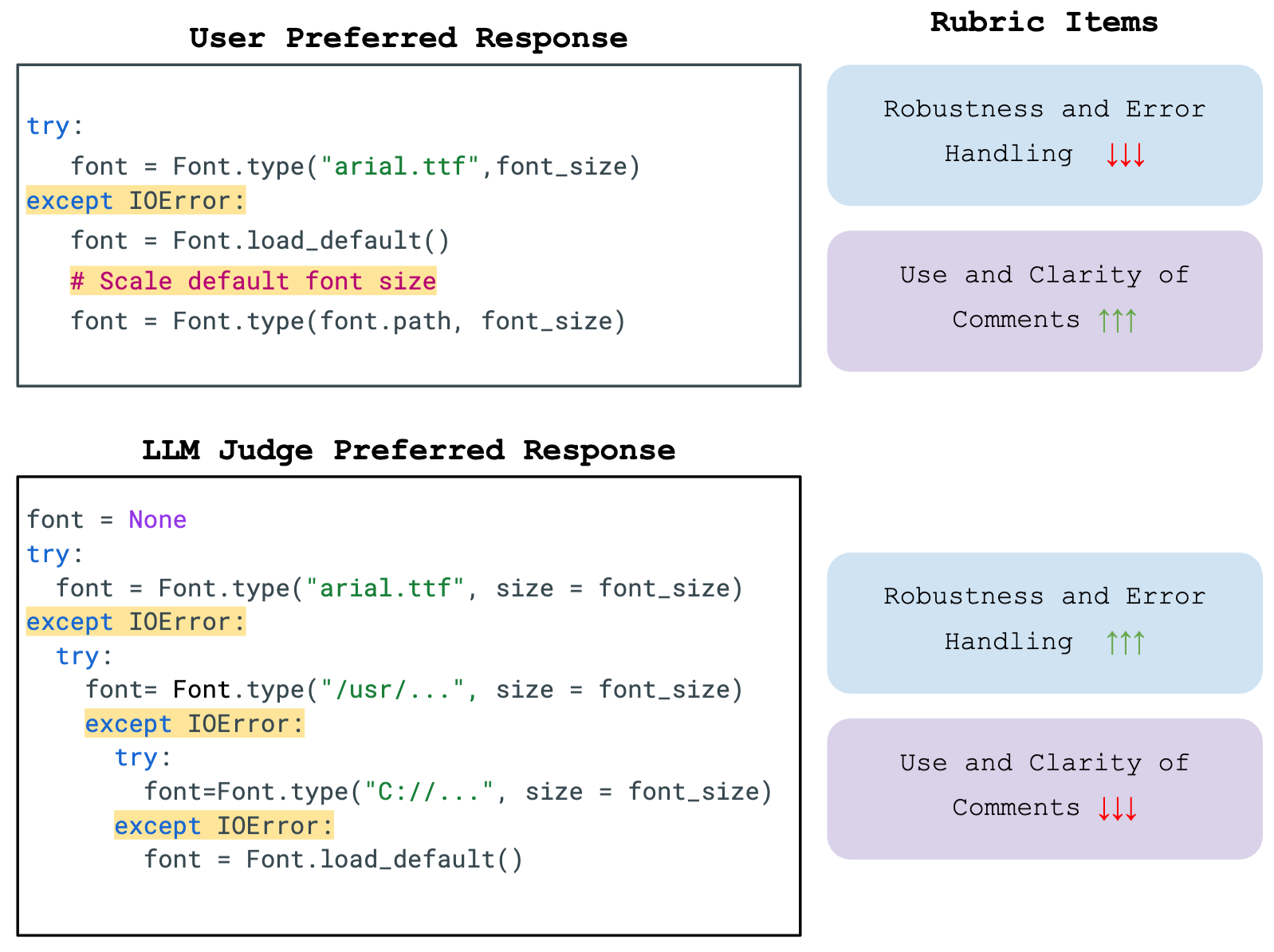









2025










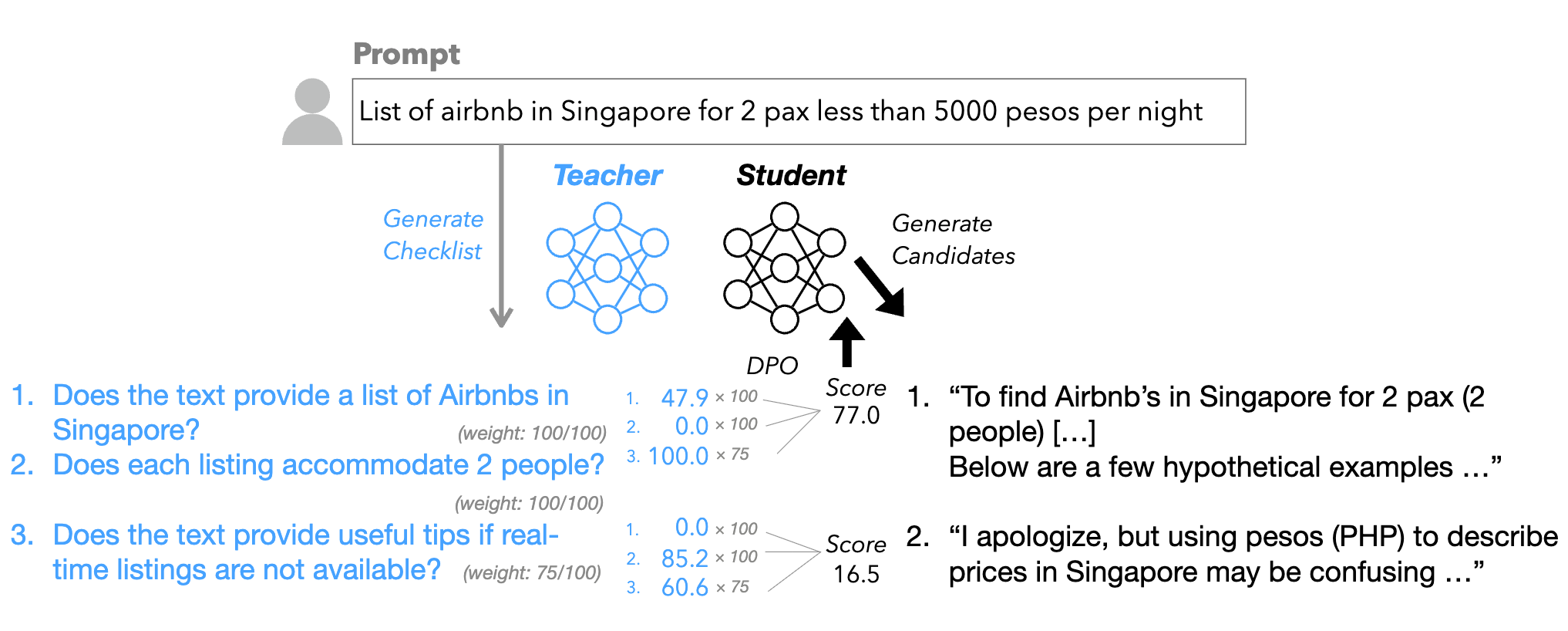

2024



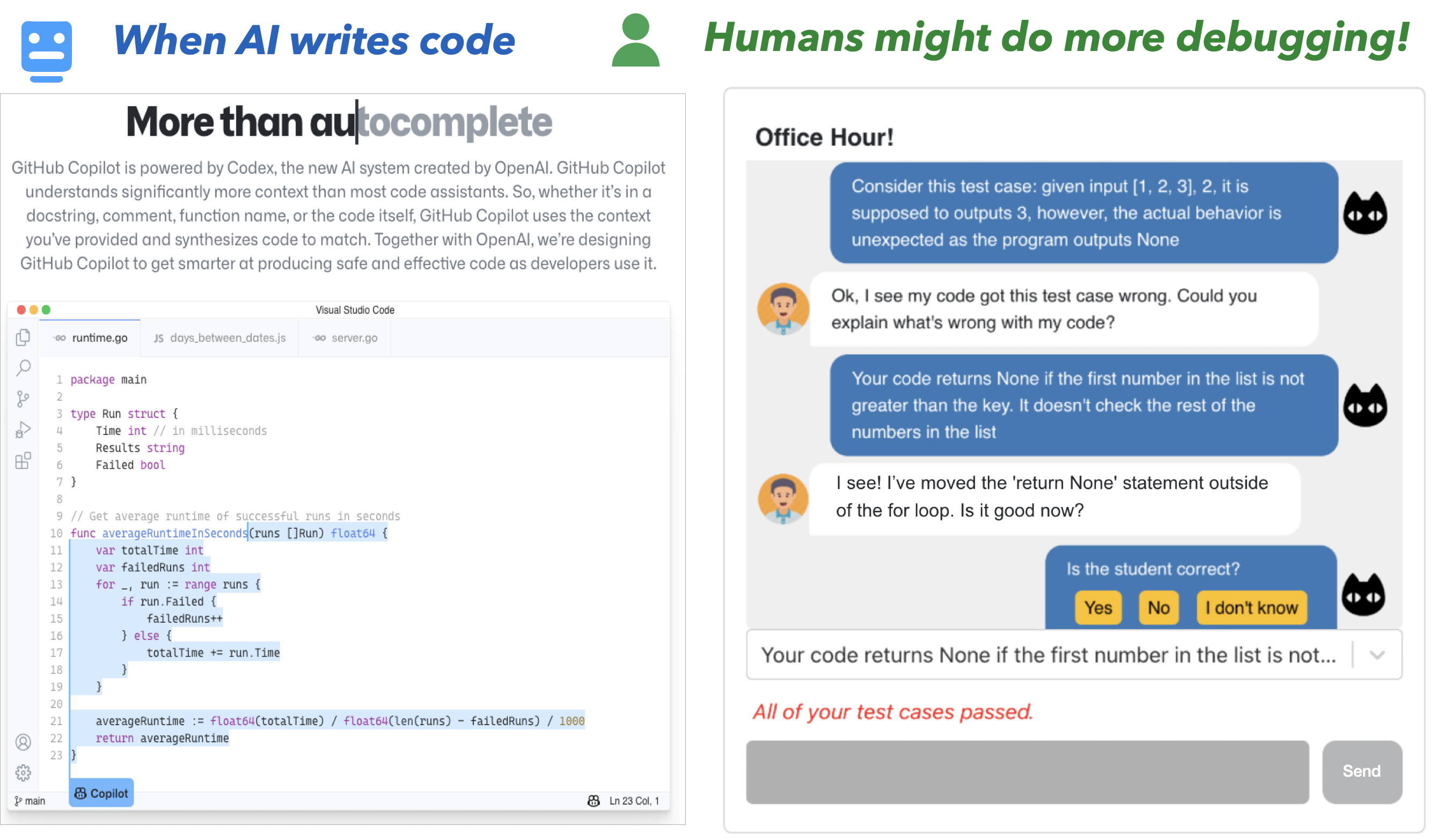












2023












Current Members




Xinran Zhao
(PhD)
Information Seeking for Complex Tasks

Jessie Mindel
(PhD)
Simulated Agents and Collective Sensemaking

Zheyuan Zhang
(PhD)
Human-Agent Interaction

Eunsu Kim
(PhD)
AI Contributions to Human Tasks.

Keyu He
(Master)
Eval of Human Prompt Ability

Callum Zhao
(Master)
Build Effective Agentic Skills

Yuan Tian
(Visit)
AI for Data Analysis
Alumni
Cheng Qian
(Visit)
LLM hullucination. Now PhD student at UIUC.
Cassandra Shi
(Undergrad)
Requirement-driven LLMs. Now PhD at NYU-Shanghai.
Shaan Lehal
(Undergrad)
LLM sensemaking copilot
Yashika Batra
(Undergrad)
LLM sensemaking copilot
Alina Chen
(Undergrad)
LLM sensemaking copilot
Samriddhi Bhardwaj
(Undergrad)
LLM sensemaking copilot
Alex Cheung
(Undergrad)
LLM sensemaking copilot
Raoyi (Cathy) Huang
(Master)
NLP dataset characterization. Now PhD student at Cornell.
Yiyang (Diana) Wang
(Master)
End-User Prompt Disambiguation. Now PhD student at Georgia Tech.
Yilin Zhang
(Master)
Code Retrieval with AST. Now software engineer at Google.
Atharva Naik
(Master)
LLM in CS education. Now PhD student at CMU.
Jushaan Kalra
(Master)
Multi-domain Retrieval. Now software engineer at Snowflake.
Yuanchen (Sophie) Bai
(Master)
NLP dataset characterization