
|
Bundle adjustment jointly optimizes camera intrinsics and extrinsics and 3D point triangulation to reconstruct a static scene. The triangulation constraint, however, is invalid for moving points captured in multiple unsynchronized videos and bundle adjustment is not designed to estimate the temporal alignment between cameras. We present a spatiotemporal bundle adjustment framework that jointly optimizes four coupled sub-problems: estimating camera intrinsics and extrinsics, triangulating 3D static points, as well as subframe temporal alignment between cameras and estimating 3D trajectories of dynamic points. Key to our joint optimization is the careful integration of physics-based motion priors within the reconstruction pipeline, validated on a large motion capture corpus of human subjects. We devise an incremental reconstruction and alignment algorithm to strictly enforce the motion prior during the spatiotemporal bundle adjustment. This algorithm is further made more efficient by a divide and conquer scheme with little loss in accuracy. We apply this algorithm to reconstruct 3D motion trajectories of human bodies in a dynamic event captured by uncalibrated and unsynchronized video streams in the wild. To make the reconstruction visually more interpretable, we fit a statistical human body model to the video streams. This fitting is constrained by the same motion prior, the 3D trajectory of the dynamic points, and other semantic cues extracted from the images. Because the videos are aligned with sub-frame precision, we reconstruct 3D motion at much higher temporal resolution than the input videos. |
Publications
"Spatiotemporal Bundle Adjustment for Dynamic 3D Reconstruction"
Minh Vo, Srinivasa Narasimhan, and Yaser Sheikh
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016.
[PDF][Poster]
"Spatiotemporal Bundle Adjustment for Dynamic 3D Human Reconstruction in the Wild"
Minh Vo, Srinivasa Narasimhan, and Yaser Sheikh
IEEE TPAMI (under review).
[PDF]
|
Full Results [download]
|
Physics-based Motion Prior
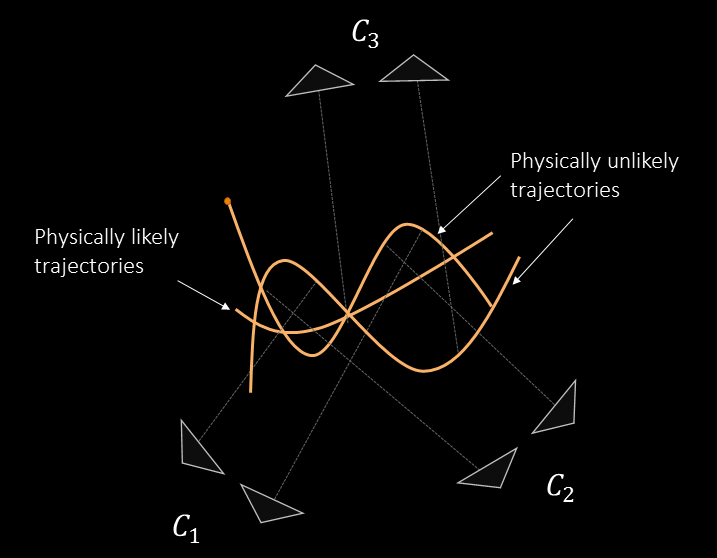 |
Among the infinitely many 3D trajectories hit by rays from different video cameras (and hence, perfectly satisfy the geometry constraint), only the true 3D trajectory correctly temporally alligns all the cameras. This motivates us to find a motion prior that ideally estimates a trajectory corresponding to the correct temporal alignment.
|
 |
Our physics-based motion prior is compact. It can model complex 3D trajectories and faciliate accurate temporal alignment of multiple cameras.
|
|
Acknowledgements
This research is supported by the NSF CNS-1446601, the ONR N00014-14-1-0595, and the Heinz Endowments "Plattform Pittsburgh", and a Qualcomm Innovation Fellowship. |