
Xiaolong Wang*, Allan Jabri* and Alexei A. Efros.
Learning Correspondence from the Cycle-consistency of Time.
Conference on Computer Vision and Pattern Recognition (CVPR), 2019.(Oral Presentation.)
(*indicates equal contributions.)
[arXiv] [BibTeX] [code]

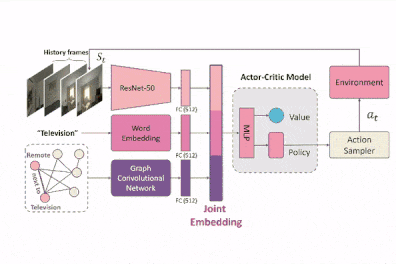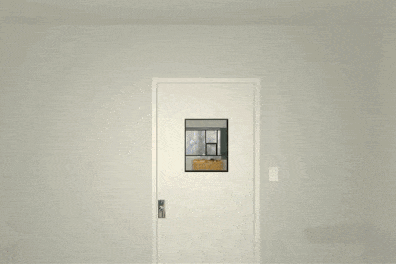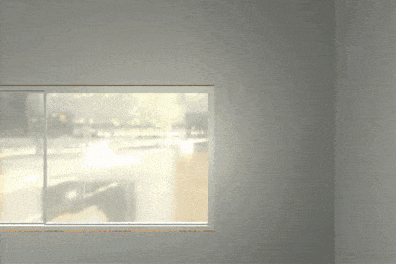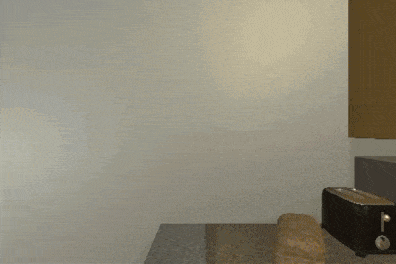


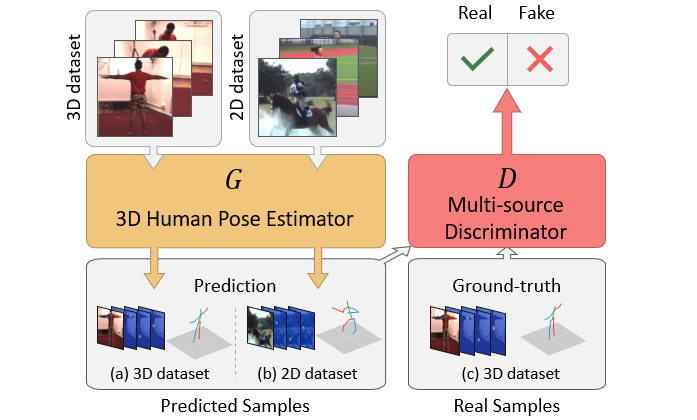
Tian Ye, Xiaolong Wang, James Davidson, and Abhinav Gupta.
Interpretable Intuitive Physics Model.
European Conference on Computer Vision (ECCV), 2018.


Xiaolong Wang, Kaiming He, and Abhinav Gupta.
Transitive Invariance for Self-supervised Visual Representation Learning.
International Conference on Computer Vision (ICCV), 2017


Xiaolong Wang*, Rohit Girdhar*, and Abhinav Gupta.
Binge Watching: Scaling Affordance Learning from Sitcoms.
Conference on Computer Vision and Pattern Recognition (CVPR), 2017 (spotlight presentation) (*indicates equal contributions.)


Xiaolong Wang and Abhinav Gupta.
Generative Image Modeling using Style and Structure Adversarial Networks.
European Conference on Computer Vision (ECCV), 2016



Xiaolong Wang and Abhinav Gupta.
Unsupervised Learning of Visual Representations using Videos.
International Conference on Computer Vision (ICCV), 2015

Xiaolong Wang, David F. Fouhey, and Abhinav Gupta.
Designing Deep Networks for Surface Normal Estimation.
Conference on Computer Vision and Pattern Recognition (CVPR), 2015.

David F. Fouhey, Xiaolong Wang, and Abhinav Gupta.
In Defense of the Direct Perception of Affordances.
arXiv, 2015.

Xiaolong Wang, Liliang Zhang, Liang Lin, Zhujin Liang, and Wangmeng Zuo.
Deep Joint Task Learning for Generic Object Extraction.
Advances in Neural Information Processing Systems (NIPS), 2014.
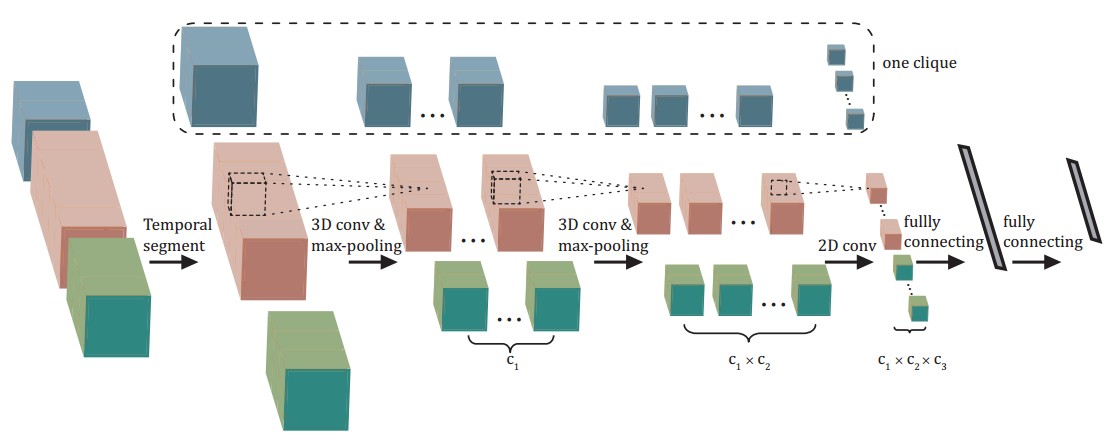
Keze Wang, Xiaolong Wang, and Liang Lin.
Deep Structured Models for 3D Human Activity Recognition.
ACM International Conference on Multimedia (MM), 2014. (full paper, oral presentation)

Zhujin Liang, Xiaolong Wang, Rui Huang, and Liang Lin.
An Expressive Deep Model for Parsing Human Action from a Single Image.
International Conference on Multimedia and Expo (ICME), 2014. (oral presentation, Best Student Paper Award)

Xiaolong Wang, Liang Lin, and Lichao Huang, Shuicheng Yan.
Incorporating Structural Alternatives and Sharing into Hierarchy for Multiclass Object Recognition and Detection.
Conference on Computer Vision and Pattern Recognition (CVPR), 2013.
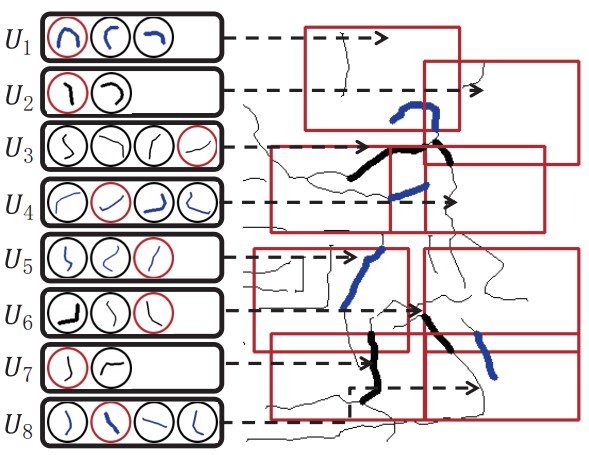
Xiaolong Wang and Liang Lin.
Dynamical And-Or Graph Learning for Object Shape Modeling and Detection.
Advances in Neural Information Processing Systems (NIPS), 2012.
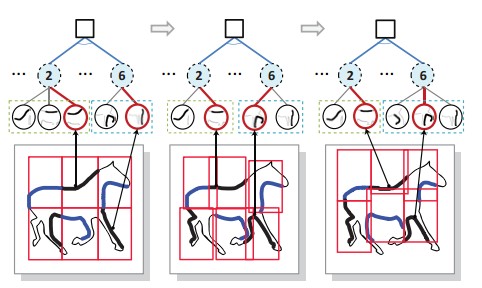
Liang Lin, Xiaolong Wang, Wei Yang, and Jian-Huang Lai.
Learning Contour-Fragment-based Shape Model with And-Or Tree Representation.
Conference on Computer Vision and Pattern Recognition (CVPR), 2012.

Wei Yang, Xiaolong Wang, Liang Lin, Chengying Gao.
Interactive CT image segmentation with online discriminative learning.
International Conference on Image Processing (ICIP), 2011.