
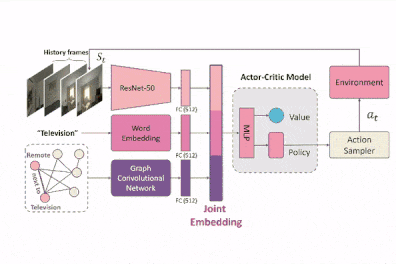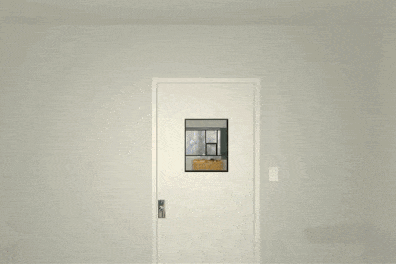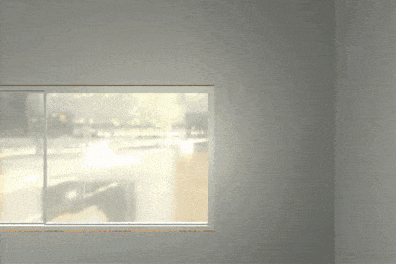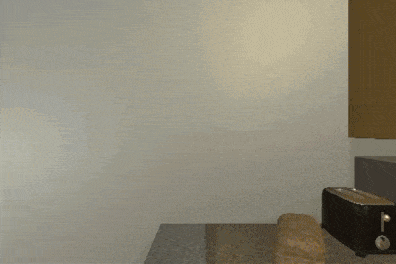

Tian Ye, Xiaolong Wang, James Davidson, and Abhinav Gupta.
Interpretable Intuitive Physics Model.
European Conference on Computer Vision (ECCV), 2018.


Xiaolong Wang*, Rohit Girdhar*, and Abhinav Gupta.
Binge Watching: Scaling Affordance Learning from Sitcoms.
Conference on Computer Vision and Pattern Recognition (CVPR), 2017 (spotlight presentation) (*indicates equal contributions.)

David F. Fouhey, Xiaolong Wang, and Abhinav Gupta.
In Defense of the Direct Perception of Affordances.
arXiv, 2015.