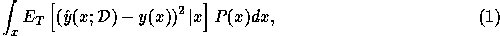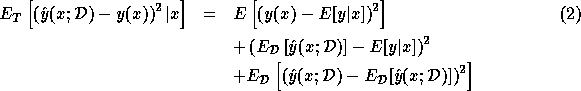We begin by defining  to be the unknown joint distribution
over x and y, and
to be the unknown joint distribution
over x and y, and  to be the known marginal distribution of
x (commonly called the input distribution). We denote the
learner's output on input x, given training set
to be the known marginal distribution of
x (commonly called the input distribution). We denote the
learner's output on input x, given training set  as
as
 .
. We can then write the expected error of the
learner as follows:
We can then write the expected error of the
learner as follows:
where 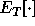 denotes expectation over
denotes expectation over  and over training
sets
and over training
sets 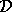 . The expectation inside the integral may be
decomposed as follows [Geman
et al. 1992]:
. The expectation inside the integral may be
decomposed as follows [Geman
et al. 1992]:
where  denotes the expectation over training sets
denotes the expectation over training sets
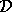 and the remaining expectations on the right-hand side are
expectations with respect to the conditional density
and the remaining expectations on the right-hand side are
expectations with respect to the conditional density 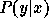 . It is
important to remember here that in the case of active learning, the
distribution of
. It is
important to remember here that in the case of active learning, the
distribution of  may differ substantially from the joint
distribution
may differ substantially from the joint
distribution  .
.
The first term in Equation 2 is the variance of y
given x --- it is the noise in the distribution, and does not
depend on the learner or on the training data. The second term is the
learner's squared bias, and the third is its variance;
these last two terms comprise the mean squared error of the learner
with respect to the regression function 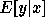 . When the second
term of Equation 2 is zero, we say that the learner is
unbiased. We shall assume that the learners considered in this
paper are approximately unbiased; that is, that their squared bias is
negligible when compared with their overall mean squared error. Thus
we focus on algorithms that minimize the learner's error by minimizing
its variance:
. When the second
term of Equation 2 is zero, we say that the learner is
unbiased. We shall assume that the learners considered in this
paper are approximately unbiased; that is, that their squared bias is
negligible when compared with their overall mean squared error. Thus
we focus on algorithms that minimize the learner's error by minimizing
its variance:
(For readability, we will drop the explicit dependence on x and
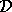 --- unless denoted otherwise,
--- unless denoted otherwise,  and
and
 are functions of x and
are functions of x and 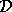 .) In an active
learning setting, we will have chosen the x-component of our
training set
.) In an active
learning setting, we will have chosen the x-component of our
training set  ; we indicate this by rewriting
Equation 3 as
; we indicate this by rewriting
Equation 3 as

where  denotes
denotes 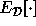 given a fixed
x-component of
given a fixed
x-component of 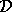 . When a new input
. When a new input 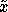 is selected
and queried, and the resulting
is selected
and queried, and the resulting  added to the
training set,
added to the
training set, 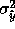 should change. We will denote the
expectation (over values of
should change. We will denote the
expectation (over values of 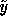 ) of the learner's new variance
as
) of the learner's new variance
as