


In this section we review the use of techniques from Optimal
Experiment Design (OED) to minimize the estimated variance of a neural
network [Fedorov 1972,MacKay 1992,Cohn 1994]. We will assume we have
been given a learner 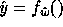 , a training set
, a training set 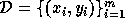 and a parameter vector estimate
and a parameter vector estimate 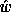 that maximizes some likelihood measure given
that maximizes some likelihood measure given  . If, for
example, one assumes that the data were produced by a process whose
structure matches that of the network, and that noise in the process
outputs is normal and independently identically distributed, then the
negative log likelihood of
. If, for
example, one assumes that the data were produced by a process whose
structure matches that of the network, and that noise in the process
outputs is normal and independently identically distributed, then the
negative log likelihood of  given
given  is proportional
to
is proportional
to
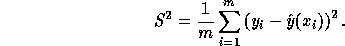
The maximum likelihood estimate for 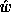 is that which minimizes
is that which minimizes
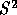 .
.
The estimated output variance of the network is

where the true variance is approximated by a second-order Taylor
series expansion around  . This estimate makes the assumption that
. This estimate makes the assumption that
 is locally linear. Combined with the
assumption that
is locally linear. Combined with the
assumption that 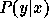 is Gaussian with constant variance for all
x, one can derive a closed form expression for
is Gaussian with constant variance for all
x, one can derive a closed form expression for
 . See [Cohn [1994]]
for details.
. See [Cohn [1994]]
for details.
In practice, 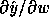 may be highly nonlinear,
and
may be highly nonlinear,
and  may be far from Gaussian; in spite of this, empirical
results show that it works well on some problems [Cohn 1994]. It
has the advantage of being grounded in statistics, and is optimal
given the assumptions. Furthermore, the expectation is differentiable
with respect to
may be far from Gaussian; in spite of this, empirical
results show that it works well on some problems [Cohn 1994]. It
has the advantage of being grounded in statistics, and is optimal
given the assumptions. Furthermore, the expectation is differentiable
with respect to 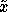 . As such, it is applicable in continuous
domains with continuous action spaces, and allows hillclimbing to find
the
. As such, it is applicable in continuous
domains with continuous action spaces, and allows hillclimbing to find
the  that minimizes the expected model variance.
that minimizes the expected model variance.
For neural networks, however, this approach has many disadvantages.
In addition to relying on simplifications and assumptions which hold
only approximately, the process is computationally expensive.
Computing the variance estimate requires inversion of a  matrix for each new example, and incorporating new examples into
the network requires expensive retraining. Paass and Kindermann
paass-kindermann95 discuss a Markov-chain based sampling
approach which addresses some of these problems. In the rest of this
paper, we consider two ``non-neural'' machine learning architectures
that are much more amenable to optimal data selection.
matrix for each new example, and incorporating new examples into
the network requires expensive retraining. Paass and Kindermann
paass-kindermann95 discuss a Markov-chain based sampling
approach which addresses some of these problems. In the rest of this
paper, we consider two ``non-neural'' machine learning architectures
that are much more amenable to optimal data selection.