


The goal of machine learning is to create systems that can improve their performance at some task as they acquire experience or data. In many natural learning tasks, this experience or data is gained interactively, by taking actions, making queries, or doing experiments. Most machine learning research, however, treats the learner as a passive recipient of data to be processed. This ``passive'' approach ignores the fact that, in many situations, the learner's most powerful tool is its ability to act, to gather data, and to influence the world it is trying to understand. Active learning is the study of how to use this ability effectively.
Formally, active learning studies the closed-loop phenomenon of a learner selecting actions or making queries that influence what data are added to its training set. Examples include selecting joint angles or torques to learn the kinematics or dynamics of a robot arm, selecting locations for sensor measurements to identify and locate buried hazardous wastes, or querying a human expert to classify an unknown word in a natural language understanding problem.
When actions/queries are selected properly, the data requirements for some problems decrease drastically, and some NP-complete learning problems become polynomial in computation time [Angluin 1988,Baum & Lang 1991]. In practice, active learning offers its greatest rewards in situations where data are expensive or difficult to obtain, or when the environment is complex or dangerous. In industrial settings each training point may take days to gather and cost thousands of dollars; a method for optimally selecting these points could offer enormous savings in time and money.
There are a number of different goals which one may wish to achieve using active learning. One is optimization, where the learner performs experiments to find a set of inputs that maximize some response variable. An example of the optimization problem would be finding the operating parameters that maximize the output of a steel mill or candy factory. There is an extensive literature on optimization, examining both cases where the learner has some prior knowledge of the parameterized functional form and cases where the learner has no such knowledge; the latter case is generally of greater interest to machine learning practitioners. The favored technique for this kind of optimization is usually a form of response surface methodology [Box & Draper 1987], which performs experiments that guide hill-climbing through the input space.
A related problem exists in the field of adaptive control, where one must learn a control policy by taking actions. In control problems, one faces the complication that the value of a specific action may not be known until many time steps after it is taken. Also, in control (as in optimization), one is usually concerned with the performing well during the learning task and must trade of exploitation of the current policy for exploration which may improve it. The subfield of dual control [Fe'ldbaum 1965] is specifically concerned with finding an optimal balance of exploration and control while learning.
In this paper, we will restrict ourselves to
examining the problem of supervised learning: based on a set of
potentially noisy training examples 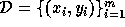 , where
, where  and
and
 , we wish to learn a general
mapping
, we wish to learn a general
mapping  . In robot control,
the mapping may be
. In robot control,
the mapping may be 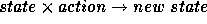 ; in hazard
location it may be
; in hazard
location it may be  . In
contrast to the goals of optimization and control, the goal of
supervised learning is to be able to efficiently and accurately
predict y for a given x.
. In
contrast to the goals of optimization and control, the goal of
supervised learning is to be able to efficiently and accurately
predict y for a given x.
In active learning
situations, the learner itself is responsible for acquiring the
training set. Here, we assume it can iteratively select a new input
 (possibly from a constrained
set), observe the resulting output
(possibly from a constrained
set), observe the resulting output  , and incorporate the new example
, and incorporate the new example  into its training set. This contrasts with
related work by Plutowski and White
[1993], which is concerned with filtering an existing data set.
In our case,
into its training set. This contrasts with
related work by Plutowski and White
[1993], which is concerned with filtering an existing data set.
In our case, 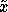 may be thought
of as a query, experiment, or action, depending on the research field
and problem domain. The question we will be concerned with is how to
choose which
may be thought
of as a query, experiment, or action, depending on the research field
and problem domain. The question we will be concerned with is how to
choose which 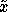 to try next.
to try next.
There are many heuristics for choosing  , including choosing places where we don't have data
[Whitehead 1991], where we
perform poorly [Linden & Weber
1993], where we have low confidence [Thrun & Möller 1992], where
we expect it to change our model [Cohn et
al. 1990,Cohn et al. 1994], and
where we previously found data that resulted in learning [Schmidhuber & Storck 1993]. In
this paper we will consider how one may select
, including choosing places where we don't have data
[Whitehead 1991], where we
perform poorly [Linden & Weber
1993], where we have low confidence [Thrun & Möller 1992], where
we expect it to change our model [Cohn et
al. 1990,Cohn et al. 1994], and
where we previously found data that resulted in learning [Schmidhuber & Storck 1993]. In
this paper we will consider how one may select 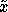 in a statistically ``optimal'' manner for some
classes of machine learning algorithms. We first briefly review how
the statistical approach can be applied to neural networks, as
described in earlier work [MacKay
1992,Cohn 1994]. Then, in
Sections 3 and 4 we consider two alternative,
statistically-based learning architectures: mixtures of Gaussians and
locally weighted regression. Section 5 presents the empirical
results of applying statistically-based active learning to these
architectures. While optimal data selection for a neural network is
computationally expensive and approximate, we find that optimal data
selection for the two statistical models is efficient and accurate.
in a statistically ``optimal'' manner for some
classes of machine learning algorithms. We first briefly review how
the statistical approach can be applied to neural networks, as
described in earlier work [MacKay
1992,Cohn 1994]. Then, in
Sections 3 and 4 we consider two alternative,
statistically-based learning architectures: mixtures of Gaussians and
locally weighted regression. Section 5 presents the empirical
results of applying statistically-based active learning to these
architectures. While optimal data selection for a neural network is
computationally expensive and approximate, we find that optimal data
selection for the two statistical models is efficient and accurate.