One method of judging the quality of a particular model is by residuals. That means the model is fit using all the data points and the prediction for each data point is compared with its actual output. The absolute value of each error is taken and the mean of those values is computed to arrive at the mean absolute residual error. Models with lower values of this measure are deemed to be better.
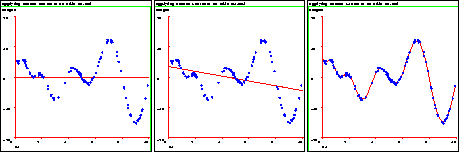
Figure 24: Approximating a one-dimensional data set with A90:9, L90:9, L10:9
metacodes. The residual error for each data point is the distance along a
vertical line between it and the fitted line. The result is very large, large,
and zero residual error, respectively.

Figure 25: Approximating a one-dimensional data set, with A90:9, L90:9, L10:9
metacodes. The residual error for each data point is the distance along a
vertical line between it and the fitted line. The result is very large, small,
and near zero residual error, respectively.
Fig. 24 shows an example where choosing the model with the lowest residual error is a good idea (the data comes from b1.mbl if you want to load it into Vizier). The fit on the right is clearly the best fit of the three for the data and its mean absolute residual error is near zero. However, choosing models by residual error is a risky thing to do.
Fig. 25 shows an example (from a1.mbl) where residuals can lead us astray. Again, the residual error in the middle plot is moderate, and the residual error on the rightmost plot is near zero. The middle plot is a much better fit though. The reason is that the rightmost plot is fitting the noise in the data. This phenomenon is referred to as ``overfitting'' and is a common problem that must be avoided in learning systems. Overfitting in this example means that errors in predicting future data points from this curve will actually be higher than if we use the middle plot's fit instead. In general, it is preferable to use something more trustworthy than residual error to choose a good model and avoid overfitting.