
CV |
Research Statement |
Bio |
Google Scholar |
Twitter |
I am a JPMorgan Chase Associate Professor of Computer Science in the Machine Learning Department at Carnegie Mellon University. I work in Artificial Intelligence at the intersection of Computer Vision, Machine Learning, Language Understanding and Robotics. Prior to joining MLD's faculty I spent three wonderful years as a post doctoral researcher first at UC Berkeley working with Jitendra Malik and then at Google Research in Mountain View working with the video group. I completed my Ph.D. in GRASP, UPenn with Jianbo Shi . I did my undergraduate studies at the National Technical University of Athens and before that I was in Crete. Prospective students: If you want to join CMU as PhD student, just mention my name in your application. Otherwise, if you would like to join our group in any other capacity, please fill this form and then please send me a short email note without any documents. |
News
- Invited talk at AAAI 2026 workshop Beyond Teleoperation Learning from Diverse Human and Simulation Data
- Four invited talks at CVPR 2026 workshops: MUSI: 2nd Workshop on Multimodal Spatial Intelligence - 4D Digital Twins: Real-to-Sim-to-Real for Physical AI - Vision-based Assistants in the Real World - CogVL: Cognitive Foundations for Multimodal Models
- Invited keynote talk at AAAI 2026.
- Invited talk at NVIDIA on RobotArena.
- Six invited talks at ICCV 2025 workshops: Reliable and Interactable World Models - Long Multi-Scene Video Foundations - Generating Indoor Digital Twins - Spatial Understanding for Embodied Intelligence - Vision and Language - Spatiotemporal Action Grounding in Videos
- Invited keynote talk at MVA 2025 conference
- Invited talks at CoRL 2025 workshop: Learning to Simulate Robot Worlds
- Invited keynote talk at Greeks in AI symposium
- Two invited talks at RSS 2025 workshops: Structured World Models for Robotic Manipulation - Benchmarking Robot Manipulation
- Seven invited talks at CVPR 2025 workshops: Multimodal Learning and Applications - Benchmarking AI Multimodal Models - 3D VLMs for Robot Manipulation - Physical Simulation and Computer Vision - 3D LLMs and VLAs - Foundation Models Meet Embodied Agents
- Two invited talks at ICRA 2025 workshops: Beyond Pick and Place - Learning Meets Model-Based Methods for Contact-Rich Manipulation
- Invited talk at Amazon Consumer Robotics' Research Symposium April 2025
- Invited Tekura Yata lecture in CMU, March 2025
- Invited talk at TTIC Colloquium, February 2025
- The GENESIS Physics engine is released and fully open sourced!
- Invited talk at Tesla.
- Invited talk at the Workshop on Mastering Robot Manipulation in a World of Abundant Data at CoRL 2024.
- Invited talk at Autonomous Vehicles meet Multimodal Foundation Models Workshop at ECCV 2024.
- Invited talk at the future for Machine learning symposium in ISTA, Vienna.
- Invited talk at the data generation for robotics workshop and geometric and algebraic structures for robot learning workshop at RSS 2024.
- Invited talks on unified 2D/3D foundational models in Multimodal 3D scenes workshop , on perception with generative feedback in Generative models for Computer Vision workshop and on memory prompting for 3D scene understanding in Compositional 3D vision workshop at CVPR 2024.
- Invited talk at the 3D visual representations for robot manipulation workshop at ICRA 2024.
- Invited talk at the Toronto vision seminar.
- Invited talks at the Active methods in autonomous navigation workshop at ICRA 2023, and at the 2nd Workshop on Computer Vision in the Wild and C3DV: 1st Workshop On Compositional 3D Vision workshops in CVPR 2023.
- I am a program chair for ICLR 2024.
- Our research was awarded an Amazon research faculty award .
- Invited talk at Archimedes , a Greek summer school on AI.
- Invited talks at three CVPR 2022 workshops, Workshop on Learning with Limited Labelled Data for Image and Video Understanding , 4th International Workshop on Visual Odometry \& Computer Vision Applications Based on Location Clues , and Embodied AI workshop .
- Invited Keynote talk at BMVC 2021.
- Invited Keynote talk at 3DV 2021.
- Invited talk at the ICCV workshop for Learning 3D Representations for Shape and Appearance and on 6th Workshop on Benchmarking Multi-Target Tracking (Segmenting and Tracking Every Point and Pixel).
- Our team's research was awarded a DARPA Young Investigator Award 2021 to support work on analogical planning agents with visuomotor commonsense.
- Invited talks at three CVPR 2021 workshops, on language for 3D scenes , Robust Video Scene Understanding and Learning to Generate 3D Shapes and Scenes workshop.
- Invited talk on self-supervising 3D scene and object representations for perception and control in the Self-Supervised Learning-Theory and Practice workshop in NeurIPS 2020.
- Our team's research was awarded an Amazon Faculty Award 2020. to support work on object manipulation across diverse environments and viewpoints
- I got a Young Inverstigator Award from AFOSR (the Air Force Research Laboratory) to suport work that will develop intelligent multimodal surveillance systems. Special thanks to Chris and Adam for their help on proposal preparation.
- Invited talk at Geometric Processing and 3D Computer Vision series .
- Invited talk at the Workshop on Long-Term Visual Localization, Visual Odometry and Geometric and Learning-based SLAM and at the 3D Scene Understanding for Vision, Graphics, and Robotics . Check out also the visual physics tutorial .
- I got an NSF CAREER award from NSF IIS. Special thanks to Chris , Phil , and Adam for their help.
- I am an area chair for ICML 2020, NeurIPS 2020, CVPR 2021, ICML 2022, CVPR 2022, NeurIPS 2020, ECCV 2022, ICLR 2021.
- Workshop on common sense of a toddler coming up in CVPR 2020.
- I was awarded a Sony faculty research award 2019
- Invited talk at Embodied Visual Recognition at Google Seattle, UberATG, and RobustAI, 40 years anniversary of GRASP lab
- Area chair CVPR 2020, ICLR 2021
- Invited talk on Adversarial Inverse Graphics Networks at Augmenting humans workshop, CVPR 2019
- Invited talk on Embodied Visual recognition at Bringing Robots to the Computer Vision Community Workshop, CVPR, 2019
- Invited talk on Embodied language Grounding at The How2 Challenge: New Tasks for Vision and Language Workshop, ICML 2019
- Invited talk on geometry-aware deep visual learning at the theory and practice in ML and CV workshop at ICERM, slides and video are available.
- I was awarded a UPMC faculty research award 2019
- Ricson is selected as a runner-up of the CRA Outstanding Undergraduate Researcher Award for 2019 !
- Area chair ICML 2019, ICLR 2019
- We are organizing an AI4ALL summer school to expose rising juniors to AI and the good it can do for the world, as we see it, here in CMU!
- Area chair CVPR 2018
- I was awarded a Google faculty award 2018
Teaching
| Deep Reinforcement Learning and Control Spring 2023, Fall 2023, Spring 2024, Fall 2024, Spring 2025, Fall 2025 |
Research Group
|
Our group studies Artificial Intelligence, and specifically Machine Learning models at the intersection of Computer Vision, Language Understanding and Robotics.
Our ultimate goal is to build machines that will autonomously and in interactions with humans and with the environment acquire and continuously improve world models, that would let them reason through consequences of their and others decisions, to surpass humans in both dexterity and creativity. Topics we currently focus on include representation learning, video understanding, 2D/3D unified vision language models, generative modeling, learning simulators from data, real2sim and sim2real robot learning, reinforcement learning, continual learning.
| |
|
PhD Students Brian Yang (with Jeff Schneider) Mihir Prabhudesai (with Deepak Pathak) Ayush Jain Kashu Yamazaki Matthew Bronars Yuxuan Kuang (with Shubham Tulsiani) |
MS Students Yash Jangir He Zhu Ziyin Xiong Lucy Lin Naman Kumar Robert Ren |
|
Former Students / Collaborators Nikos Gkanatsios (PhD student, TESLA) Wen-hsuan Chu (PhD student, TESLA) Gabriel Sarch (PhD student, PostDoc Princeton) Alexander Swerlow (MS student, Stanford PhD) Tsung-Wei Ke (PostDoc, Professor at NTU CSIE) Lei Ke (PostDoc, Tencent AI Lab) Xian Zhou (PhD student, Genesis AI) Fish Tung (PhD student, post doc in M.I.T., Tesla, Google DeepMind) Adam Harley (PhD student, PostDoc at Stanford, Meta) Theo Gevret (PhD student, Skild, Mistral, Genesis AI) Pushkal Katara (MS student, ScaledFoundations) Ricson Chen (undergrad, CRA research award) Zhaoyuan Fang (MS student, Google) Mayank Singh (MS student, Apple). Yunchu Zhang (MS student, UW PhD) Ziyan Wang (MSR student, RI CMU PhD) Shamit Lal (MS student, Amazon AGI) Yiming Zuo (MSR student, Princeton PhD) Max Sieb (MSR student, Copvarian AI, Google DeepMind) Arpit Agarwal (MSR student, RI CMU PhD) Henry Huang (MS student, Bloomberg) Chris Ying (MS student, Google Brain) Darshan Patil (undergraduate, MILA PhD) Nilay Pande (MS, Tesla, Waymo) Ishitta Mediratta (undergraduate collaborator, Meta) |
|
Selected Publications

|
RobotArenaInf: Unlimited Robot Benchmarking via Real-to-Sim Translation
Yash Jangir, Yidi Zhang*, Kashu Yamazaki*, Chenyu Zhang*, Kuan-Hsun Tu, Tsung-Wei Ke, Lei Ke, Yonatan Bisk, Katerina Fragkiadaki ICLR 2026 project page |
|
3D FlowMatch Actor: Unified 3D Policy for Single- and Dual-Arm Manipulation
Nikolaos Gkanatsios*, Jiahe Xu*, Matthew Bronars, Arsalan Mousavian, Tsung-Wei Ke, Katerina Fragkiadaki arxiv GitHub / Project Page |
|
|
AllTracker: Efficient Dense Point Tracking at High Resolution
Adam W. Harley, Yang You, Xinglong Sun, Yang Zheng, Nikhil Raghuraman, Yunqi Gu, Sheldon Liang, Wen-Hsuan Chu, Achal Dave, Pavel Tokmakov, Suya You, Rares Ambrus, Katerina Fragkiadaki, Leonidas J. Guibas ICCV 2025 project page |
|

|
TAPIP3D: Tracking Any Point in Persistent 3D Geometry
Bowei Zhang, Lei Ke, Adam W. Harley, Katerina Fragkiadaki NeurIPS 2025 project page |

|
Diffusion Beats Autoregressive in Data-Constrained Settings
Mihir Prabhudesai*, Mengning Wu*, Amir Zadeh, Katerina Fragkiadaki, Deepak Pathak NeurIPS 2025 project page |
|
PartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers
Yuchen Lin, Chenguo Lin, Panwang Pan, Honglei Yan, Yiqiang Feng, Yadong Mu, Katerina Fragkiadaki NeurIPS 2025 project page |
|
|
Grounded Reinforcement Learning for Visual Reasoning
Gabriel Sarch, Snigdha Saha, Naitik Khandelwal, Ayush Jain, Michael Tarr, Aviral Kumar, Katerina Fragkiadaki NeurIPS 2025 project page |
|
|
Unified Multimodal Discrete Diffusion
Alexander Swerdlow*, Mihir Prabhudesai*, Siddharth Gandhi, Deepak Pathak, Katerina Fragkiadaki arxiv project page |
|

|
Video Depth without Video Models
Bingxin Ke, Dominik Narnhofer, Shengyu Huang, Lei Ke, Torben Peters, Katerina Fragkiadaki, Anton Obukhov, Konrad Schindler CVPR 2025 project page |

|
Unifying 2D and 3D Vision-Language Understanding
Ayush Jain*, Alexander Swerdlow*, Yuzhou Wang, Alexander Sax, Franziska Meier, Katerina Fragkiadaki ICML 2025 project page |
|
Video Diffusion Alignment via Reward Gradients
Mihir Prabhudesai, Russell Mendonca, Zheyang Qin, Katerina Fragkiadaki, Deepak Pathak VADER aligns video diffusion models using end-to-end reward gradient backpropagation from off-the-shelf differentiable reward functions. arxiv webpage |
|
|
VLM Agents Generate Their Own Memories: Distilling Experience into Embodied Programs of Thought
Gabriel Sarch, Lawrence Jang, Michael Tarr, William Cohen, Kenneth Marino, Katerina Fragkiadaki A technique that enables VLM agents to take initially suboptimal demonstrations and iteratively improve them, ultimately generating high-quality trajectory data that includes both optimized actions and detailed reasoning annotations suitable for more effective in-context learning and fine-tuning. NeurIPS 2024 spotlight webpage |
|
|
RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation
Yufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, Chuang Gan ICML 2024 webpage |
|
|
DreamScene4D: Dynamic Multi-Object Scene Generation from Monocular Videos
Wen-Hsuan Chu*, Lei Ke*, Katerina Fragkiadaki DreamScene4D generates 3D dynamic scenes of multiple objects from monocular videos training-free, using object-centric diffusion priors and pixel and motion reprojection error. NeurIPS 2024 webpage |
|

|
ODIN: A Single Model for 2D and 3D Perception
Ayush Jain, Pushkal Katara, Nikolaos Gkanatsios, Adam W. Harley, Gabriel Sarch, Kriti Aggarwal, Vishrav Chaudhary, Katerina Fragkiadaki ODIN processes both RGB images and sequences of posed RGB-D images by alternating between 2D and 3D fusion layers using projection and unprojection from camera info. New SOTA in Scannet200. CVPR 2024 spotlight webpage |
|
3D Diffuser Actor: Policy Diffusion with 3D Scene Representations
Tsung-Wei Ke*, Nikolaos Gkanatsios*, Katerina Fragkiadaki Combining 3D relative attention transformers with action trajectory diffusion gives SOTA imitation learning robot policies in CALVIN and RLbench. CoRL 2024 webpage |
|
|
Diffusion-ES: Gradient-free Planning with Diffusion for Autonomous Driving and Zero-Shot Instruction Following
Brian Yang, Huangyuan Su, Nikolaos Gkanatsios, Tsung-Wei Ke, Ayush Jain, Jeff Schneider, Katerina Fragkiadaki Diffusion-ES combines trajectory diffusion models with evolutionary search and achieves SOTA performance in nuPLAN. We prompt LLMs to map language instructions to shaped reward functions, and optimize them with diffusion-ES, and solve the hardest driving scenarios. CVPR 2024 webpage |
|

|
Test-time Adaptation of Discriminative Models via Diffusion Generative Feedback
Mihir Prabhudesai*, Tsung-Wei Ke*, Alexander C. Li, Deepak Pathak, Katerina Fragkiadaki NeurIPS 2023 webpage |
|
Open-Ended Instructable Embodied Agents with Memory-Augmented Large Language Models
Gabriel Sarch, Yue Wu, Michael J. Tarr, Katerina Fragkiadaki EMNLP findings 2023 webpage |
|

|
Brain Dissection: fMRI-trained Networks Reveal Spatial Selectivity in the Processing of Natural Images
Gabriel Sarch, Michael Tarr, Katerina Fragkiadaki*, Leila Wehbe* NeurIPS 2023 |
|
Act3D: 3D Feature Field Transformers for Multi-Task Robotic Manipulation
Theophile Gervet*, Zhou Xian*, Nikolaos Gkanatsios, Katerina Fragkiadaki CoRL 2023 webpage |
|

|
ChainedDiffuser: Unifying Trajectory Diffusion and Keypose Prediction for Robotic Manipulation
Zhou Xian*, Nikolaos Gkanatsios*, Theophile Gervet*, Tsung-Wei Ke, Katerina Fragkiadaki CoRL 2023 webpage |
|
Gen2Sim: Scaling up Robot Learning in Simulation with Generative Models
Pushkal Katara*, Xian Zhou*, Katerina Fragkiadaki ICRA 2023 webpage |
|
|
Test-time Adaptation with Slot-Centric Models
Mihir Prabhudesai, Anirudh Goyal, Sujoy Paul, Sjoerd van Steenkiste, Mehdi S. M. Sajjadi, Gaurav Aggarwal, Thomas Kipf, Deepak Pathak, Katerina Fragkiadaki ICML 2023 webpage |
|

|
Energy-based Models are Zero-Shot Planners for Compositional Scene Rearrangement
Nikolaos Gkanatsios, Ayush Jain, Zhou Xian, Yunchu Zhang, Christopher Atkeson, Katerina Fragkiadaki RSS 2023 webpage |

|
Simple-BEV: What Really Matters for Multi-Sensor BEV Perception?
Adam W. Harley, Zhaoyuan Fang, Jie Li, Rares Ambrus, Katerina Fragkiadaki ICRA 2023 webpage |

|
FluidLab: A Differentiable Environment for Benchmarking Complex Fluid Manipulation
Zhou Xian, Bo Zhu, Zhenjia Xu, Hsiao-Yu Tung, Antonio Torralba, Katerina Fragkiadaki, Chuang Gan ICLR 2023, spotlight webpage |

|
Analogy-Forming Transformers for Few-Shot 3D Parsing
Nikolaos Gkanatsios, Mayank Singh, Zhaoyuan Fang, Shubham Tulsiani, Katerina Fragkiadaki ICLR 2023 webpage |

|
Bottom Up Top Down Detection Transformers for Language Grounding in Images and Point Clouds
Ayush Jain, Nikolaos Gkanatsios, Ishita Mediratta, Katerina Fragkiadaki ECCV 2022 webpage |

|
TIDEE: Tidying Up Novel Rooms using Visuo-Semantic Commonsense Priors
Gabriel Sarch, Zhaoyuan Fang, Adam W. Harley, Paul Schydlo, Michael J. Tarr, Saurabh Gupta, Katerina Fragkiadaki ECCV 2022 webpage |

|
Particle Videos Revisited: Tracking Through Occlusions Using Point Trajectories
Adam W. Harley, Zhaoyuan Fang, Katerina Fragkiadaki ECCV 2022, oral webpage |

|
Visually-Grounded Library of Behaviors for Manipulating Diverse Objects across Diverse Configurations and Views
Jingyun Yang*, Hsiao-Yu Fish Tung*, Yunchu Zhang*, Gaurav Pathak, Ashwini Pokle, Christopher G Atkeson, Katerina Fragkiadaki CoRL 2021 webpage |

|
Disentangling 3D Prototypical Networks for Few-Shot Concept Learning
Mihir Prabhudesai*, Shamit Lal*, Darshan Patil*, Hsiao-Yu Tung, Adam Harley, Katerina Fragkiadaki ICLR 2021 webpage |

|
Track, Check, Repeat: An EM Approach to Unsupervised Tracking
Adam W. Harley, Yiming Zuo, Jing Wen, Ayush Mangal, Shubhankar Potdar, Ritwick Chaudhry, Katerina Fragkiadaki CVPR 2021 webpage |

|
Move to See Better: Self-Improving Embodied Object Detection
Zhaoyuan Fang, Ayush Jain, Gabriel Sarch, Adam W. Harley, Katerina Fragkiadaki BMVC 2021 webpage |

|
HyperDynamics: Generating Expert Dynamics Models by Observation
Zhou Xian, Shamit Lal, Hsiao-Yu Tung, Emmanouil Antonios Platanios, Katerina Fragkiadaki ICLR 2021 webpage |

|
CoCoNets: Continuous Contrastive 3D Scene Representations
Shamit Lal, Mihir Prabhudesai, Ishita Mediratta, Adam W. Harley, Katerina Fragkiadaki CVPR 2021 webpage |
|
|
Tracking Emerges by Looking Around Static Scenes, with Neural 3D Mapping
Adam W. Harley, Shrinidhi K. Lakshmikanth, Paul Schydlo, Katerina Fragkiadaki ECCV 2020 |

|
Embodied Language Grounding with Implicit 3D Visual Feature Representations
Mihir Prabhudesai*, Hsiao-Yu Fish Tung*, Syed Ashar Javed*, Maximilian Sieb, Adam W. Harley, Katerina Fragkiadaki CVPR 2020 webpage |
|
|
|

|
Graph-structured Visual Imitation
Xian Zhou*, Max Sieb*, Audrey Huang, Oliver Kroemer, Katerina Fragkiadaki CoRL 2019, spotlight webpage |

|
Learning from Unlabelled Videos Using Contrastive Predictive Neural 3D Mapping
Adam W. Harley, Fangyu Li, Shrinidhi K. Lakshmikanth, Xian Zhou, Hsiao-Yu Fish Tung, Katerina Fragkiadaki ICLR 2020 webpage |

|
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
Hsiao-Yu Fish Tung, Ricson Cheng, Katerina Fragkiadaki CVPR 2019, oral webpage |

|
Model Learning for Look-ahead Exploration in Continuous Control
Arpit Agarwal, Katharina Muelling and Katerina Fragkiadaki AAAI 2019 oral webpage |

|
Reinforcement Learning of Active Vision for Manipulating Objects under Occlusions
Ricson Cheng, Arpit Agarwal, and Katerina Fragkiadaki CoRL 2018 slides | code |

|
Geometry-Aware Recurrent Neural Networks for Active Visual Recognition
Ricson Cheng, Ziyan Wang, and Katerina Fragkiadaki NIPS 2018 |

|
Reward Learning from Narrated Demonstrations
Fish Tung, Adam Harley, Liang-Kang Huang, Katerina Fragkiadaki CVPR 2018 bibtex |

|
Depth-adaptive Computational Policies for Efficient Visual Tracking
Chris Ying, Katerina Fragkiadaki EMMCVPR 2017 bibtex |
|
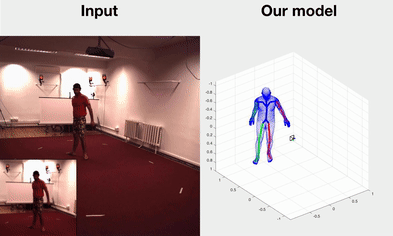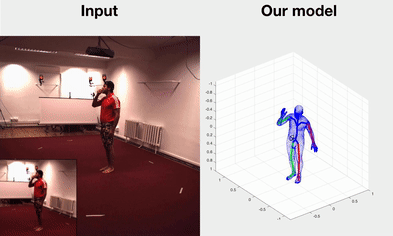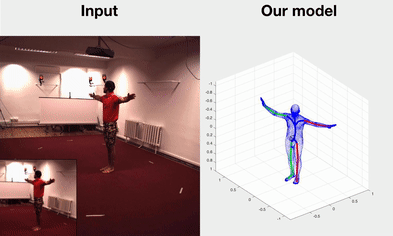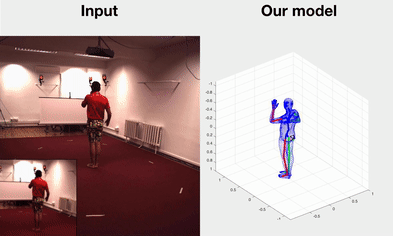
Self-supervised Learning of Motion Capture
Hsiao-Yu Fish Tung, Wei Tung, Ersin Yumer, Katerina Fragkiadaki NIPS 2017 spotlight bibtex | code |

|
Adversarial Inverse Graphics Networks: Learning 2D-to-3D Lifting and Image-to-Image Translation from Unpaired Supervision
Hsiao-Yu Fish Tung, Adam Harley, William Seto, Katerina Fragkiadaki ICCV 2017 bibtex | code |

|
SfM-Net: Learning of Structure and Motion from Video
Sudheendra Vijayanarasimhan, Susanna Ricco, Cordelia Schmid, Rahul Sukthankar, Katerina Fragkiadaki arxiv |

|
Learning Predictive Visual Models of Physics for Playing Billiards
Katerina Fragkiadaki*, Pulkit Agrawal*, Sergey Levine, Jitendra Malik ICLR 2016 webpage |

|
Recurrent Network Models for Human Dynamics
Katerina Fragkiadaki, Sergey Levine, Panna Felsen, Jitendra Malik ICCV 2015 webpage |

|
Human Pose Estimation with Iterative Error Feedback
Joao Carreira, Pulkit Agrawal, Katerina Fragkiadaki, Jitendra Malik arXiv webpage |

|
Learning to Segment Moving Objects in Videos
Katerina Fragkiadaki, Pablo Arbelaez, Panna Felsen, Jitendra Malik CVPR 2015 poster | bibtex | webpage |

|
Grouping-Based Low-Rank Video Completion and 3D Reconstruction
Katerina Fragkiadaki, Marta Salas, Pablo Arbelaez, Jitendra Malik NIPS 2014 poster | bibtex | webpage |

|
Two Granularity Tracking: Mediating Trajectory and Detection Graphs for Tracking under Occlusions
Katerina Fragkiadaki, Weiyu Zhang, Geng Zhang, Jianbo Shi ECCV 2012 poster | bibtex | webpage |