Christian Kästner
Associate Professor · Carnegie Mellon University · Institute for Software Research
Feature Flags vs Configuration Options – Same Difference?
Update: We have published a paper on this discussion, including updates from interviews we conducted, at ICSE-SEIP 2020.
Having spent over a decade researching configurable systems and software product lines, the phenomenon of feature flags is interesting but also deeply familiar. After reading papers and blogs, watching talks, and interviewing several developers, we see some nuance but also many issues that we had thought were solved long ago.
Several research communities have looked into features, flags, and options: In the 90s researchers were investigating feature interactions in telecommunication systems and were worried about weird interaction bugs stemming from compositions of optional features. The product line community has developed notations and tools for modeling and reasoning about variability at scale (thousands of options) and has discussed implementation, testing, and analysis strategies for systems with planned configurations. The systems community has investigated how the number of options seem to only ever grow and how users are increasingly frustrated with overwhelming configuration spaces, but also how to diagnose, fix, or even prevent configuration mistakes. For feature flags, we now see all those discussions again: too many flags, hard to remove, hard to test, surprising interaction faults, ...
Let us share some thoughts and a (probably biased) overview of the research landscape:
Feature Interactions and Complexity
Feature interactions (long studied not only on telecommunication systems), occur when two options together behave different from what could be expected from each of them individually. There are many well known examples:
- A fire and a flood control system in a building can both be installed and tested independently, but if combined without understanding their interactions, the flood control system may shut down water to a building on fire after the fire control system activates the sprinklers (a form of resource conflict with one feature interfering with the behavior of the other).
- Call waiting and call forwarding can be both independently developed and activated, but how to handle an incoming call on a busy line is unclear when both are activated (two features competing on the same event).
- Plugins in a software system can be developed and tested independently, but may not always work in all combinations. For example, two WordPress plugins that transform the blog post by inserting smileys or weather forecasts may capture overlapping parts of the post:

Feature interaction causing a problem when composing two optional plugins
Feature interactions are a failure of compositionality. Developers think of two features as independent and develop and test them independently, but when composed surprising things may happen. Often interactions are actually intended (true orthogonality is rare) and extra coordination mechanisms are needed, such as priority mechanisms (e.g., fire control overwrites flood control; weather tags are translated before smiley tags, etc). Coordination is easy once interactions are known, however finding and understanding interactions is nontrivial, especially when features are developed separately and there are no clear specifications. We will come back to this later.
Combinatorial explosion challenges program understanding: Each decision in the code doubles the number of paths the program can take. Developers have a really hard time reasoning about large configuration spaces. Recent studies have shown that as few as three configuration options can make it really hard for developers to correctly understand the behavior of 20 line programs (Melo, Brabrand, and Wsowski 2016). Although one might argue that the number of combinations does not matter as long as the set of configurations is limited and the options have a fixed values, developers may not have the benefit of such understanding and face code with many decisions. Thus, each additional feature impacts a developers productivity, especially if we are talking about thousands of features.
Key differences and insights: Adding options or flags is always challenging for understanding, maintenance, and quality assurance. Feature flags are no exception. Unexpected feature interactions among options can be really tricky to find and can have severe consequences.
Temporary vs Permanent Flags
The term feature flag (or toggle) is used very broadly for many different concepts. They are popular for controlling code paths in operation (A/B testing, canary releases, rollouts and rollbacks) and for hiding incomplete implementations while committing to head (avoiding branches and merge conflicts), as well as for traditional configuration settings (setting parameters, enabling functionality for certain users, etc).
The research community around configurable systems and product lines use the terms configuration option or feature and focus mostly on the latter problem. Configuration options are often used in a similar way, though usually they are intended to stick around (several researchers found that configuration options are rarely removed), whereas some (but not all) feature flags are intended to be removed after a feature is completed, tested, and deployed. Feature flag removal and technical debt around unremoved feature flags seems to be a key (process) challenge.
Research in configurable systems has shown that options are also often added and rarely removed and that too many options produce significant maintenance and support costs (Xu et al. 2015; Lotufo et al. 2010). It's cheap to introduce an option, but potentially expensive to maintain. If end users can configure the system it can be very difficult to ever get rid of options that some users might use (though in practice there is often little evidence who uses what).
Since the values of feature flags and their rationale for introducing them is often known, there are great opportunities here to track feature flag use better and introduce mechanisms for removal. Discipline in how feature flags are implemented and documented can simplify management and removal, as discussed below.
Key differences and insights: Feature flags are often temporary, but removing them is a common process challenge, causing technical debt, that hasn't been a focus of previous work on configurable systems.
Who is Making Configuration Decisions?
In the world of product lines and configurable systems, one key distinction that drives many other considerations, especially testing (see below), is who is in charge of configuring the system:
- Developers/operators configure: In many traditional software product lines, a company releases a small to medium number of distinct products (e.g., different printers for HP, different releases of Windows with different features). Sometimes, features are activated for paying customers only. In these cases, developers or operators are in charge of configuring the system and users just receive the configured (and hopefully tested) configuration. For example, HP's printer firmware has over 2000 boolean flags, but the company releases only around 100 configurations which each go through CI before release.
- Users configure: Most end-user software and system software has dozens or even thousands of configuration options that users can use to customize the software. For example, end users can use graphical interfaces to change various options in Firefox or Chrome, specify hundreds of parameters in Apache's httpd.conf configuration file, or select from about 14000 compile-time options when they compile their own Linux kernel. When configuration is in the user's hands, it is unpredictable which configurations will actually be used. In most cases (except for web-based systems and systems with good telemetry), we may not even know which configurations are used.
This has profound consequences for testing, because we can focus on a few known configurations in the first case, but may want to make assurances for all potential configurations a user may select.
Feature flags again somehow touch both of these worlds. Most feature flags seem to be clearly in the "operators configure" world. When used for A/B testing, canary releases, or to hide unfinished features, they are controlled by the operations team and the used configurations are (or should be) known. However, feature flags are sometimes also used for experimental releases that end users can configure (e.g., Chrome's chrome://flags/, see Rahman et al. (2016)), blurring the distinction.
Chrome configuration dialog
Being in control of the configuration has major advantages: One can observe which configurations are used, e.g., monitor which flags have not been changed in weeks. One does not have to care about all the combinations of flags that are not actually used (well, only somewhat, as discussed below). And one can actually remove flags without having to fear to break user configurations.
Key differences and insights: Developer/operator controlled options have many advantages and most feature flags fall into this category. Be explicit about and limit which flags can be configured by end users.
Binding Times
A key distinction in implementing configuration options is what binding times are supported, i.e., when the decisions are made. Several papers have discussed different implementation mechanisms and their corresponding binding times (e.g., Svahnberg, Gurp, and Bosch 2005; Apel, Batory, et al. 2013; Kästner, Apel, and Kuhlemann 2008; Muthig and Patzke 2002; Czarnecki and Eisenecker 2000; Anastasopoules and Gacek 2001).
- Compile-time binding: Options are set when the project is compiled and not changed afterward. A specific configuration is thus compiled, tested, and deployed. For example, preprocessor
#ifdefstatements are often used to exclude code at compile time. Various code composition approaches have been suggested to separate feature implementations in distinct modules, but it's just as well possible to use constants and normalifstatements in the implementation, or configuration files that don't change after compilation. Even when normalifstatements are used, compilers can potentially optimize the code and remove infeasible paths (from simple optimization to partial evaluation (Jones 1996; Jones, Gomard, and Sestoft 1993)). - Load-time binding: Options are loaded (e.g., from command-line options or configuration files) when the program starts; from the perspective of a running program they are essentially constants. This is extremely common and usually very simple to implement. However, since configuration options may be set after compilation, it is less common to rigorously test all used configurations in a CI process or similar.
- Run-time variability: Options may change at runtime, typically when the user changes values in a configuration dialog (e.g., Firefox settings) or, more common for feature flags, when a configuration value is queried through an API from a service and changes at some point (often homegrown solutions or services like LaunchDarkly and split). The advantage is that options can be changed in long-running processes without restarting, but the disadvantage is that it is much harder to ensure consistency and avoid stale values (see Toman and Grossman (2016) and Toman and Grossman (2018) for mechanisms to detect such issues). Sometimes it's easier to ask users to restart the system after a configuration change; for short running processes serving web requests it's also easier to essentially assume load-time variability for every request.
Most research on configurable systems focuses on compile-time or load-time variability. For example, there is a huge amount of research on #ifdefs and module composition mechanisms. Runtime variability seems less common and seems often not worth the extra challenges. For feature flags, consider whether load-time rather than runtime variability is feasible to reduce complexity and the chance of inconsistent states.
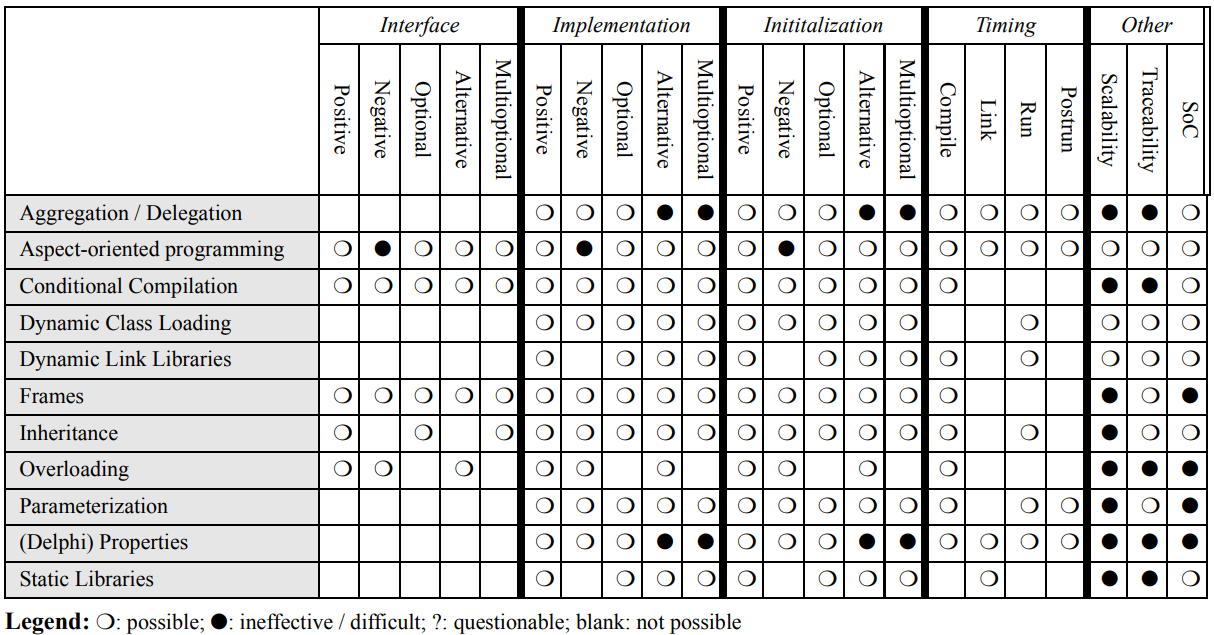
Different variability implementation strategies and their characteristics, from Svahnberg, Gurp, and Bosch (2005)
A key consideration is the interaction of binding times with testing. Traditionally, automated testing is performed after compilation (i.e., for each compile-time configuration), but rarely for each load-time or run-time configuration decision.
Key differences and insights: Feature flags mostly use run-time bindings, but often load-time or even compile-time bindings are sufficient and simpler.
Tracing Feature Flags (Flag to Implementation Mapping)
How does one find all the code related to an option or flag? In some cases it's trivial: find the #ifdef or if statement that checks a well-named flag and a few statements guarded by it. But things can quickly get complicated.
First, the flow from where an option's value is read to where it is used is not always obvious or easy to trace in an automated fashion. Options are often loaded into configuration options (e.g., hashmaps) or propagated across function calls and various variables.
Second, even when only few statements in a method are directly guarded by a flag, these few statements can of course invoke lots of other code elsewhere, that might not obviously be associated with this feature flag--that is, there can be large parts of the code (entire classes, modules, dependencies) that are essentially dead code unless a feature flag is enabled, but that mapping might not always be obvious. Also the extra statements may introduce unusual or complex control flows (e.g., exceptions) that are not easily recognized (our own study has shown that developers often make such mistakes when asked to identify all code belonging to an option (Lillack, Kästner, and Bodden 2018)). Finally, code guarded by flags can change various values that are then used later in other places to trigger other if statements or cause various forms of changes and interactions.
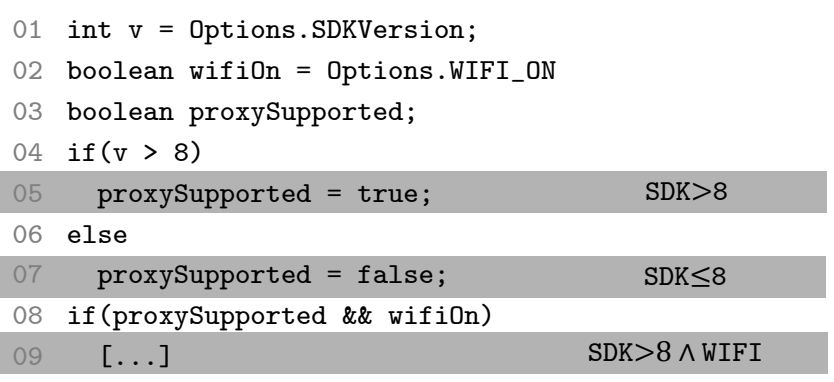
Understanding how code fragments rely on Android's options from Lillack, Kästner, and Bodden (2018)
Lots of research on configurable systems and product lines has shown that options often have fairly limited effects and do not interact with most other options, but also that effects of options are often not strictly local and often cause indirect effects through data flows (Meinicke et al. 2016). Several researchers have developed analysis tools to track configuration options across various data and control flows, for example, to approximate possible interactions, detect the scope of an option's implementation, or detect dependencies among options (Lillack, Kästner, and Bodden 2018; Nadi et al. 2015; Xu et al. 2013; Angerer et al. 2015; Meinicke et al. 2016; Soares et al. 2018; Tartler et al. 2011; Zhang and Ernst 2014; Xu and Zhou 2015).
Disciplined option implementation: Tracing and analysis can be much simplified if discipline is used for implementing options. A key hygiene strategy is to separate configuration options as much as possible from other computations in the program; that is, avoid using options as input parameters to more sophisticated implementations, but rather mostly propagate them to the if statement where they make a decision. Clear naming conventions can help as well. Keep implementations corresponding to an option confined in a clear place and document unusual control or data flows. It might be worth investing in writing custom simple static analysis tools or even language mechanisms or libraries that enforce a separation of configuration mechanisms and program logic.
Modularity / abstraction / encapsulation: A common suggestion from the product line community for reducing the complexity if to separate the implementation of features from the rest of the program, thus, to localize or modularize features (Kästner, Apel, and Ostermann 2011). Many researchers have even explored dedicated language mechanisms (feature modules, aspects, delta modules), but they have never seen much adoption in practice and have various problems of their own (Apel, Batory, et al. 2013; Batory, Sarvela, and Rauschmayer 2004). A similar suggestion from our observations on feature flags is to hide features behind abstractions. This, however, adds boilerplate for each flag, which also needs to be removed after the flag is established. Especially for short-term feature flags it might be okay to skip the abstraction step and use a simple but disciplined mechanism to focus on long-term code quality and easy flag removal.
Our standing hypothesis is that most developers already follow a fairly strong discipline for configuration options and pursue locality of options, because they still want to be able to reason about their work. Options that all interact and are hidden in complicated data-flows are difficult to reason about for humans and analysis algorithms alike due to the combinatorial explosion of possible combinations and corresponding code paths. One can make the lives easier for both by enforcing discipline.
Key differences and insights: Identifying how flags relate to implementations can be surprisingly complicated, but discipline in the implementation, separating configuration logic from program logic, can make both manual and automated analyses much easier.
Removing Feature Flags
In traditional configurable systems, where users may change configuration options, it is often difficult to decide when an option can be removed, because it is usually not clear which options users actually use or even depend on. In product lines, where the producer maintains a finite list of configurations, removal is easier but often not done because developers may argue an option might still be useful for future product configurations. This may change significantly for feature flags, where at least some flags are intended to be short lived.
The technical part of removing options from an implementation has been studied and several tools have been built. In theory it could be as simple as removing an if statement, but if the scope of the implementation is not well understood it is easy to make mistakes. Even for #ifdefs the task turned out more complicated as one might expect due to possible data-flow among options with #define and #undef statements (Baxter and Mehlich 2001). Conceptually, removing an option is merely a form of partial evaluation (Jones, Gomard, and Sestoft 1993) where a program is specialized for known values of certain options, but in practice few practical tools exist for removing options and developers rarely go through the effort.
To make it easier for developers to remove feature flags, it might be useful to invest in building own tools that make such removal easy. To gain confidence that such tools work reliably, it is again useful to have clear conventions for feature flags and limit implementations to few specific patterns.
Key differences and insights: The problem of removing a flag from an implementation is conceptually well understood (partial evaluation), but not many practical tools are available. (Semi-)automated removal becomes much easier with more disciplined implementations.
Documenting Feature Flags
For the product line community, features are a central mechanism for communication, planning, and decision making. Much effort is taken to explicitly document features (or options) and their dependencies. The description of features, their possible values, and their constraints is explicitly separated from the actual values chosen for any specific configuration. Simple notations such as feature diagrams (e.g., see Batory (2005) or FeatureIDE) are widely adopted to group and document features and especially to describe constraints on possible configurations (most prominently documenting multiple features to be optional, mutually exclusive, depending on another, or in a hierarchical relationship where child features depend on parent features). Clear documentation of constraints enables automated reasoning and checking of configurations.
Beyond tools focused more on product lines like FeatureIDE or pure::variants, a great example is the Linux kernel's variability model (She et al. 2010), for which the kernel developers have developed their own domain-specific language to describe and document options and an interactive configurator to select configurations that adhere to all constraints. This is used for some 14000 configuration options in the kernel alone.
menu "Power management and ACPI options"
depends on !X86_VOYAGER
config PM
bool "Power Management support"
depends on !IA64_HP_SIM
---help---
"Power Management" means that . . .
config PM_DEBUG
bool "Power Management Debug Support"
depends on PM
config CPU_IDLE
bool "CPU idle PM support"
default ACPI
config PM_SLEEP
bool
depends on SUSPEND || HIBERNATION || XEN_SAVE_RESTORE
default y
...
endmenuThese kconfig files are part of the Linux kernel source tree and versioned with git (e.g., for mm submodule). Specific configurations are simple option value mappings in a separate file that can be generated and checked by tools that process the kconfig language.
Academic research has invested a considerable amount of effort into tools that can work with such documented feature models, for example, detecting inconsistencies among constraints (Batory 2005; Benavides, Seguraa, and Ruiz-Cortés 2010), analyzing the evolution of model changes (Lotufo et al. 2010; Thüm, Batory, and Kästner 2009), resolving conflicts in configurations (Xiong et al. 2015), or guiding humans through the configuration process (Schmid, Rabiser, and Grünbacher 2011; Hubaux et al. 2013).
In our interviews, we saw that documentation and description of dependencies is likely the place where feature flag practitioners most lack behind the product line community and use often at most ad-hoc mechanisms and sparse comments spread across various configuration or source files. In configurable systems more broadly, there is also less consensus on how to specify, load, and document options (Sayagh et al. 2017; Sayagh et al. 2018).
While documentation is often disliked, it is essential for configuration options, because values are often chosen by stakeholders who have not originally created the option and dependencies among options must be enforced, which can be easily missed if options are only added to a text file with a one-line comment at best. A central configuration model also ensures that all options are documented in a single place, rather than scattered across dozens of files or different mechanisms. A single configuration mechanism can be used across different implementation strategies and binding times. Of course, it should undergo version control just as all other parts of the implementation.
Intentions about defaults and life-time of an option can be used for further automation, such as reminding developers to remove a flag after 1 month or after successful deployment.
Finally, documentation and implementation of features may drift apart. For example, researchers have found flags in the Linux kernel implementation that can never be enabled, as well as documented flags that are never used in the implementation (Tartler et al. 2011). It is typically a good idea and easy to implement a static consistency check that assures that only documented options can be used in the implementation and that all options are used somewhere. In addition, more advanced static analyses have been developed in academia to identify dependencies among features from the implementation and check whether those align with the documented constraints (e.g., Nadi et al. 2015).
Key differences and insights: Documenting flags and their dependencies is important and enables many forms of reasoning and automation. Much can be learned from feature modeling in the product line community.
Analysis and Testing
Every boolean configuration option doubles the size of the configuration space and it quickly becomes infeasible to test all possible configurations (320 boolean options result in more possible configurations than there are atoms in the universe; the Linux kernel has 14000 compile-time options alone).
As discussed above, we can distinguish options by who makes the configuration decisions: developers/operators or end users. If developers are in charge we might only care about a few configurations that we release, but if users configure the system we don't know which configurations they choose and have to kind of care about all combinations of options.
Feature flags are typically, but not always under control of the development or operations team. Having control and full knowledge over used configurations is a major advantage and allows much more targeted testing and also allows monitoring of the use of flags, e.g., to suggest when to remove.
But even if the developers or operations team is in charge and feature flags are not exposed to users, one may want to change configurations quickly during operation without going through a full test cycle. Also, Detecting bugs, e.g., from unintended interactions among flags, or only when a combination of flags is actually used, may trigger some late and more costly fixes and reduces the agility with which configurations can be changed. Still, in most organizations, making sure that each configuration went through CI before it is deployed and ensuring that quick live changes are only allowed among tested configurations are not unreasonable strategies and can be implemented with moderate infrastructure.
In practice, it seems many teams using feature flags make changes to configurations live without testing the specific configurations -- which is dangerous.
If one cares about quality for the entire configuration space, there are a number of approaches. There is a lot of research on giving assurances on the entire space (Thüm et al. 2014; Rhein et al. 2018), but the more pragmatic and ready to use approach here is combinatorial testing (Nie and Leung 2011): Combinatorial testing selects a small set of configurations, such that every combination of every pair of options is included together in at least one configuration and individually in at least one configuration each. Since a single configuration can cover specific combinations of many pairs at the same time (e.g., a single configuration A, B, !C covers A and B together as well as A without C and B without C), combinatorial testing can typically cover interactions among many options with very few configurations (e.g., 18 test configurations for pairwise coverage of 1000 boolean options). For simple cases without constraints among options, just use the NIST tables, if there are constraints there are many academic and a few commercial tools to explore.
For example, the following table has 8 configurations (rows) that assign configuration values to 15 boolean options A--O. For every pair of options there is always at least one configuration that enables both options together, two that each enable one but disables the other, and one that enables neither:
A B C D E F G H I J K L M N O
0 0 1 0 0 0 1 1 1 0 0 1 1 1 1
0 1 0 1 1 0 0 0 1 1 0 0 0 1 1
1 0 0 1 0 1 0 1 0 0 0 0 0 1 0
1 1 1 0 1 1 0 1 1 0 1 1 0 0 0
1 1 0 0 0 0 1 0 0 1 1 1 1 0 1
0 0 1 1 1 1 1 0 0 1 1 0 1 0 0
0 0 0 0 0 0 1 0 0 0 0 0 0 0 0
0 0 0 1 0 1 0 1 0 1 1 1 1 1 1 Many other strategies to sample configurations for testing have been explored. For example, the Linux kernel team uses a number of hand-curated representative configurations together with a farm of computers that perform testing on random configurations (see https://01.org/lkp/documentation/0-day-test-service). Several studies have compared the ability of different sampling strategies to find bugs in configurable systems (e.g., Medeiros et al. 2016).
Finally, automated tests are only as good as the executed test suites. It can be a good idea to write feature-specific tests that are only executed if that feature is executed but test the behavior of that feature independent of what other features may be enabled (Nguyen, Kästner, and Nguyen 2014; Greiler, Deursen, and Storey 2012; Apel, Rhein, et al. 2013). Similarly, it can be useful to write additional assertions in the source code that state assumptions that the feature implementation makes about the state of the system or other features if needed, so that such issues are more likely to be detected during testing.
Key differences and insights: Testing all configurations is clearly infeasible, but combinatorial testing and other sampling strategies can effectively cover large spaces.
What's new?
What are we missing? Are there any fundamentally new challenges or should we just learn from configurable systems? What are tooling challenges, what are process challenges?
We'd be happy to have a larger discussion around configuration options and feature flags. Feel free to reach out via comments below or email.
Readings
Anastasopoules, Michalis, and Critina Gacek. 2001. “Implementing Product Line Variabilities.” In Proc. Symposium on Software Reusability (SSR), 109–17. New York: ACM Press. doi:10.1145/375212.375269.
Angerer, Florian, Andreas Grimmer, Herbert Prähofer, and Paul Grünbacher. 2015. “Configuration-Aware Change Impact Analysis (T).” In 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 385–95. IEEE Computer Society. doi:10.1109/ASE.2015.58.
Apel, Sven, Don Batory, Christian Kästner, and Gunter Saake. 2013. Feature-Oriented Software Product Lines: Concepts and Implementation. Berlin/Heidelberg: Springer-Verlag. https://link.springer.com/book/10.1007%2F978-3-642-37521-7.
Apel, Sven, Alexander von Rhein, Thomas Thüm, and Christian Kästner. 2013. “Feature-Interaction Detection Based on Feature-Based Specifications.” Computer Networks. doi:10.1016/j.comnet.2013.02.025.
Batory, Don. 2005. “Feature Models, Grammars, and Propositional Formulas.” In Proc. Int’l Software Product Line Conference (SPLC), 3714:7–20. Lecture Notes in Computer Science. Berlin/Heidelberg: Springer-Verlag. doi:10.1007/11554844_3.
Batory, Don, Jacob Neal Sarvela, and Axel Rauschmayer. 2004. “Scaling Step-Wise Refinement.” IEEE Trans. Softw. Eng. (TSE) 30 (6). Los Alamitos, CA: IEEE Computer Society: 355–71. doi:10.1109/TSE.2004.23.
Baxter, Ira, and Michael Mehlich. 2001. “Preprocessor Conditional Removal by Simple Partial Evaluation.” In Proc. Working Conf. Reverse Engineering (WCRE), 281–90. Washington, DC: IEEE Computer Society. doi:10.1109/WCRE.2001.957833.
Benavides, David, Sergio Seguraa, and Antonio Ruiz-Cortés. 2010. “Automated Analysis of Feature Models 20 Years Later: A Literature Review.” Information Systems 35 (6). Elsevier: 615–36. doi:10.1016/j.is.2010.01.001.
Czarnecki, Krzysztof, and Ulrich Eisenecker. 2000. Generative Programming: Methods, Tools, and Applications. New York: ACM Press/Addison-Wesley.
Greiler, Michaela, Arie van Deursen, and Margaret-Anne Storey. 2012. “Test Confessions: A Study of Testing Practices for Plug-in Systems.” In Proc. Int’l Conf. Software Engineering (ICSE), 244–54. Los Alamitos, CA: IEEE Computer Society. doi:https://dl.acm.org/citation.cfm?id=2337253.
Hubaux, Arnaud, Patrick Heymans, Pierre-Yves Schobbens, Dirk Deridder, and Ebrahim Khalil Abbasi. 2013. “Supporting Multiple Perspectives in Feature-Based Configuration.” Software & Systems Modeling 12 (3). Springer: 641–63.
Jones, Neil D. 1996. “An Introduction to Partial Evaluation.” ACM Computing Surveys (CSUR) 28 (3). New York, NY, USA: ACM: 480–503. http://www.cs.ucdavis.edu/~devanbu/teaching/260/jones-survey.pdf.
Jones, Neil D., Carsten K. Gomard, and Peter Sestoft. 1993. Partial Evaluation and Automatic Program Generation. Upper Saddle River, NJ: Prentice-Hall.
Kästner, Christian, Sven Apel, and Martin Kuhlemann. 2008. “Granularity in Software Product Lines.” In Proc. Int’l Conf. Software Engineering (ICSE), 311–20. New York: ACM Press. doi:10.1145/1368088.1368131.
Kästner, Christian, Sven Apel, and Klaus Ostermann. 2011. “The Road to Feature Modularity?” In Proc. SPLC Workshop on Feature-Oriented Software Development (FOSD). New York: ACM Press. https://www.cs.cmu.edu/~ckaestne/pdf/FOSD11-modularity.pdf.
Lillack, Max, Christian Kästner, and Eric Bodden. 2018. “Tracking Load-Time Configuration Options.” IEEE Transactions on Software Engineering 44 (12). Los Alamitos, CA: IEEE Computer Society: 1269–91. doi:10.1109/TSE.2017.2756048.
Lotufo, Rafael, Steven She, Thorsten Berger, Krzysztof Czarnecki, and Andrzej Wsowski. 2010. “Evolution of the Linux Kernel Variability Model.” In Proc. Int’l Software Product Line Conference (SPLC), 136–50. Berlin/Heidelberg: Springer-Verlag. http://dl.acm.org/citation.cfm?id=1885639.1885653.
Medeiros, Flávio, Christian Kästner, Márcio Ribeiro, Rohit Gheyi, and Sven Apel. 2016. “A Comparison of 10 Sampling Algorithms for Configurable Systems.” In Proceedings of the 38th International Conference on Software Engineering (ICSE), 643–54. New York, NY: ACM Press. doi:10.1145/2884781.2884793.
Meinicke, Jens, Chu-Pan Wong, Christian Kästner, Thomas Thüm, and Gunter Saake. 2016. “On Essential Configuration Complexity: Measuring Interactions in Highly-Configurable Systems.” In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering (ASE), 483–94. New York, NY: ACM Press. doi:10.1145/2970276.2970322.
Melo, Jean, Claus Brabrand, and Andrzej Wsowski. 2016. “How Does the Degree of Variability Affect Bug Finding?” In Proceedings of the 38th International Conference on Software Engineering, 679–90. ACM. doi:10.1145/2884781.2884831.
Muthig, Dirk, and Thomas Patzke. 2002. “Generic Implementation of Product Line Components.” In Proc. Int’l Conf. Object-Oriented and Internet-Based Technologies, Concepts, and Applications for a Networked World (Net.ObjectDays), 2591:313–29. Lecture Notes in Computer Science. Berlin/Heidelberg: Springer-Verlag. doi:10.1007/3-540-36557-5_23.
Nadi, Sarah, Thorsten Berger, Christian Kästner, and Krzysztof Czarnecki. 2015. “Where Do Configuration Constraints Stem from? An Extraction Approach and an Empirical Study.” IEEE Transactions on Software Engineering. doi:10.1109/TSE.2015.2415793.
Nguyen, Hung Viet, Christian Kästner, and Tien N. Nguyen. 2014. “Exploring Variability-Aware Execution for Testing Plugin-Based Web Applications.” In Proc. Int’l Conf. Software Engineering (ICSE), 907–18. New York: ACM Press.
Nie, Changhai, and Hareton Leung. 2011. “A Survey of Combinatorial Testing.” ACM Computing Surveys (CSUR) 43 (2). New York: ACM Press: 11:1–11:29. doi:10.1145/1883612.1883618.
Rahman, Md Tajmilur, Louis-Philippe Querel, Peter C Rigby, and Bram Adams. 2016. “Feature Toggles: Practitioner Practices and a Case Study.” In Proceedings of the 13th International Conference on Mining Software Repositories, 201–11. ACM. http://users.encs.concordia.ca/~pcr/paper/Rahman2016MSR.pdf.
Rhein, Alexander von, Jörg Liebig, Andreas Janker, Christian Kästner, and Sven Apel. 2018. “Variability-Aware Static Analysis at Scale: An Empirical Study.” ACM Transactions on Software Engineering and Methodology 27 (4). New York, NY: ACM Press: Article No. 18. doi:10.1145/3280986.
Sayagh, Mohammed, Zhen Dong, Artur Andrzejak, and Bram Adams. 2017. “Does the Choice of Configuration Framework Matter for Developers? Empirical Study on 11 Java Configuration Frameworks.” In 2017 IEEE 17th International Working Conference on Source Code Analysis and Manipulation (SCAM), 41–50. IEEE. http://mcis.polymtl.ca/~msayagh/scam17.pdf.
Sayagh, Mohammed, Noureddine Kerzazi, Bram Adams, and Fabio Petrillo. 2018. “Software Configuration Engineering in Practice: Interviews, Survey, and Systematic Literature Review.” IEEE Transactions on Software Engineering. IEEE. http://mcis.polymtl.ca/publications/2019/tse.pdf.
Schmid, Klaus, Rick Rabiser, and Paul Grünbacher. 2011. “A Comparison of Decision Modeling Approaches in Product Lines.” In Proc. Int’l Workshop on Variability Modelling of Software-Intensive Systems (VaMoS), 119–26. New York: ACM Press. doi:10.1145/1944892.1944907.
She, Steven, Rafael Lotufo, Thorsten Berger, Andrzej Wsowski, and Krzysztof Czarnecki. 2010. “The Variability Model of the Linux Kernel.” In Proc. Int’l Workshop on Variability Modelling of Software-Intensive Systems (VaMoS), 45–51. Essen: University of Duisburg-Essen. https://gsd.uwaterloo.ca/sites/default/files/camera-vamos-20100107.pdf.
Soares, Larissa Rocha, Jens Meinicke, Sarah Nadi, Christian Kästner, and Eduardo Santana de Almeida. 2018. “Exploring Feature Interactions Without Specifications: A Controlled Experiment.” In Proceedings of the 17th ACM International Conference on Generative Programming and Component Engineering (GPCE), 41–52. New York, NY: ACM Press. doi:10.1145/3278122.3278127.
Svahnberg, Mikael, Jilles van Gurp, and Jan Bosch. 2005. “A Taxonomy of Variability Realization Techniques.” Software–Practice & Experience 35 (8). New York, NY: John Wiley & Sons, Inc.: 705–54. doi:10.1002/spe.v35:8.
Tartler, Reinhard, Daniel Lohmann, Julio Sincero, and Wolfgang Schröder-Preikschat. 2011. “Feature Consistency in Compile-Time-Configurable System Software: Facing the Linux 10,000 Feature Problem.” In Proc. Europ. Conf. Computer Systems (EuroSys), 47–60. New York: ACM Press. http://www4.informatik.uni-erlangen.de/Publications/2011/tartler_11_eurosys.pdf.
Thüm, Thomas, Sven Apel, Christian Kästner, Ina Schaefer, and Gunter Saake. 2014. “A Classification and Survey of Analysis Strategies for Software Product Lines.” ACM Computing Surveys 47 (1). New York, NY: ACM Press: Article 6. doi:10.1145/2580950.
Thüm, Thomas, Don Batory, and Christian Kästner. 2009. “Reasoning About Edits to Feature Models.” In Proc. Int’l Conf. Software Engineering (ICSE), 254–64. Washington, DC: IEEE Computer Society. https://www.cs.cmu.edu/~ckaestne/pdf/icse2009_fm.pdf.
Toman, John, and Dan Grossman. 2016. “Staccato: A Bug Finder for Dynamic Configuration Updates.” In 30th European Conference on Object-Oriented Programming (ECOOP 2016). Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik. http://drops.dagstuhl.de/opus/volltexte/2016/6118/pdf/LIPIcs-ECOOP-2016-24.pdf.
———. 2018. “Legato: An at-Most-Once Analysis with Applications to Dynamic Configuration Updates.” In 32nd European Conference on Object-Oriented Programming (ECOOP 2018). Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik. http://drops.dagstuhl.de/opus/volltexte/2018/9229/pdf/LIPIcs-ECOOP-2018-24.pdf.
Xiong, Yingfei, Hansheng Zhang, Arnaud Hubaux, Steven She, Jie Wang, and Krzysztof Czarnecki. 2015. “Range Fixes: Interactive Error Resolution for Software Configuration.” IEEE Transactions on Software Engineering 41 (6). IEEE: 603–19. http://sei.pku.edu.cn/~xiongyf04/papers/TSE14.pdf.
Xu, Tianyin, and Yuanyuan Zhou. 2015. “Systems Approaches to Tackling Configuration Errors: A Survey.” ACM Computing Surveys (CSUR) 47 (4). ACM: 70.
Xu, Tianyin, Long Jin, Xuepeng Fan, Yuanyuan Zhou, Shankar Pasupathy, and Rukma Talwadker. 2015. “Hey, You Have Given Me Too Many Knobs!: Understanding and Dealing with over-Designed Configuration in System Software.” In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, 307–19. ACM. http://cseweb.ucsd.edu/~longjin/FSE15.pdf.
Xu, Tianyin, Jiaqi Zhang, Peng Huang, Jing Zheng, Tianwei Sheng, Ding Yuan, Yuanyuan Zhou, and Shankar Pasupathy. 2013. “Do Not Blame Users for Misconfigurations.” In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, 244–59. SOSP ’13. New York, NY, USA: ACM. doi:10.1145/2517349.2522727.
Zhang, Sai, and Michael D Ernst. 2014. “Which Configuration Option Should I Change?” In Proceedings of the 36th International Conference on Software Engineering, 152–63. ACM. http://zhang-sai.github.io/pdf/zhang-icse14.pdf.