Christian Kästner
Associate Professor · Carnegie Mellon University · Institute for Software Research
Software Engineering for AI-Enabled Systems
We explore how different facets of software engineering change with the introduction of machine learning components in production systems, with an interest in interdisciplinary collaboration, quality assurance, system-level thinking, safety, and better data science tools: Capturing Software Engineering for AI-Enabled Systems · Interdisciplinary Collaboration in Engineering AI-Enabled Systems · Developer Tooling for Data Scientists
Sustainability and Fairness in Open Source
We study the dynamics of open source communities with a focus on unstanding and fostering fair and sustainable environments. Primarily with empirical research methods, we explore topics, such as open source culture, coordination, stress and disengagement, funding, and security: Sustainability and Fairness in Open Source · Collaboration and Coordination in Open Source · Adoption of Practices and Tooling
Quality Assurance for Highly-Configurable Software Systems
We explore approaches to scale quality assurance strategies, including parsing, type checking, data-flow analysis, and testing, to huge configuration spaces in order to find variability bugs and detect feature interactions: Variational Analysis · Analysis of Unpreprocessed C Code · Variational Type Checking and Data-Flow Analysis · Variational Execution (Testing) · Sampling · Feature Interactions · Variational Specifications · Assuring and Understanding Quality Attributes as Performance and Energy · Security
Maintenance and Implementation of Highly-Configurable Systems
We explore a wide range of different variability implementation mechanisms and their tradeoffs; in addition, we explore reverse engineering and refactoring mechanisms for variability and support developers with variability-related maintenance: Reverse Engineering Variability Implementations · Feature Flags · Feature-Oriented Programming · Assessing and Understanding Configuration-Related Complexity · Understanding Preprocessor Use · Tracking Load-Time Configuration Options · Build Systems · Modularity and Feature Interactions
Working with Imperfect Modularity
We explore mechanisms to support developers in scenarios in which traditional modularity mechanisms face challenges; among others, we explore strategies to complement modularity mechanisms with tooling: Virtual Separation of Concerns · Awareness for Evolution in Software Ecosystems · Conceptual Discussions
Variability Mechanisms Beyond Configurable Software Systems
We explore how analyses developed for variability can solve problems in contexts beyond software product lines, such as design space exploration, that share facets of the problem such as large finite search spaces with similarities among candidates: Developer Support and Quality Assurance for PHP · Sensitivity Analysis · Mutation Testing and Program Repair
Other Topics
We have collaborated on a number of other software engineering and programming languages topics, including dynamic software updates, extensible domain-specific languages, software merging, and various empirical methods topics: Understanding Program Comprehension with fMRI
Software Engineering for AI-Enabled Systems
We investigate how the introduction of machine learning in software projects (AI-enabled systems) changes the way that production systems are developed, tested, and maintained. This is true both for traditional software systems where now a machine-learned component is added (e.g., adding automated slide layout to PowerPoint) as well for systems build around machine-learning innovations (e.g., an automated audio transcription service). Machine learning models form heuristics that often work, but without clear specifications that could be checked as in traditional quality assurance work. Assuming that a model may make mistakes, the focus must increasingly be on system-level thinking, whole system design, testing in production, and requirements engineering. Our goal is to understand challenges and provide better techniques for design, quality assurance, maintenance, and operation of software systems with machine learning components. It is particularly interesting how to bring together team-members with different backgrounds (data scientists, software engineers, operators, ...) to build AI-enabled systems and transition them into production.
This is a recent and fast moving field, with many interesting research problems.

Capturing Software Engineering for AI-Enabled Systems
Software engineering for AI-enabled systems is a new and emergent field, emphasizing that one has to look beyond the machine-learning model at the larger system to plan a successful software product with AI components in production. We are particularly interested in this from an education perspective [ICSE-SEET 2020] and from forming a community to understand the relevant topics in the field [🖺], captured also in multiple talks [🎞, 🎞, 🎞]. This way, we tough on many topics, including quality assurance [🖺, 🖺], software development processes [🖺], requirements engineering [🖺, 🖺], safety, fairness, MLOps, and many others.
Interdisciplinary Collaboration in Engineering AI-Enabled Systems
Interdisciplinary collaboration becomes a central point, as software engineers and data scientists each have distinct specialities, focus, goals, and experiences, but need to work together in building these AI-enabled systems. For example, software engineers need to work with data scientists to define quality expectations for machine-learned components beyond just prediction accuracy, but also covering performance, fairness, safety, and explainability requirements among many others. They also need to work together to understand how to design the overall system to deal with mistakes the model makes, typically with mitigation and system-design strategies outside the model [🎞]. This requires a fresh look at the development process of AI-enabled systems [🖺].
Much of our work focuses on understanding collaboration points, such as the handoff of modeling code between data scientists and software engineers when transitioning a research project into a production system. We believe that there is high potential for deliberate collaboration, for capturing contracts at collaboration points, and for providing tooling and automation to catch common problems and make teams more effective.

Developer Tooling for Data Scientists
Computational notebooks, such as Jupyter, are broadly adopted by data scientists, but offer a far less rich developer environment than what software engineers are used to. At the same time, data scientist's workflows and goals are different, so a direct translation of software engineering tools and practices is not appropriate. We investigate techniques to improve developer tooling for data scientistis, primarily targeted at notebooks. For example, can we nudge data scientists to consider various quality attributes beyond prediction accuracy, can we automatically derive documentation, can we provide debugging support, can we automatically migrate notebook code toward production-ready pipeline code and back? We develop analysis tools and notebook extensions to help data scientists in their work and in their collaboration with software engineers as part of a larger AI-enabled system.
Sustainability and Fairness in Open Source
Open-source software is ubiquitous and plays such critical roles in today’s software infrastructure and economy that threats to its sustainability must be taken seriously. Unsustainable open-source infrastructure poses serious risks and undermines innovation for the economy as a whole. However, over the last 8-10 years open source has significantly changed—nowadays, open source is increasingly characterized by professionalization and commercial involvement, by high pressure through transparency, and by high demands and expectations from users, just to name a few. Participants in open source communities, many of which volunteer their time, are often exposed to high levels of stress and some even report burnout. We are interested in questions of individual fairness and how to shape open source culture to be sustainable. This involves many important research topics, such as the common collaboration and coordination mechanisms used, the role of money in open source, stress and burnout and toxic interactions, mechanisms to shape culture and encourage the adoption of sustainable practices, and many more. Our research aims to supplement discussions that are currently typically shaped by opinions and anecdotes with empirical evidence as well as to provide evidence-supported and validated interventions.

Sustainability and Fairness in Open Source
With the increasing commercialization and professionalization of open source new stressors around interactions between paid contributors and voluteers, high transparency, entitled users and many others emerge. We are interested in understanding current practices and suggesting interventions (e.g., tools and best practices) for more sustainable and equitable communities [🎞]. This involves studying the reasons for disengagement and stress [ICSE-NIER 2020, OSS 2019], studying community culture [FSE 2016], studying funding mechanisms such as donations [ICSE 2020, 🖺], and designing security mechanisms [ICSE-NIER 2019, ICSE 2021].
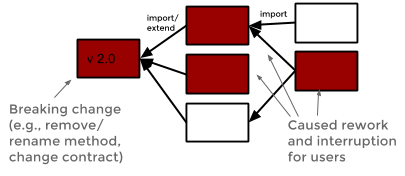
Collaboration and Coordination in Open Source
Open source strives from the collaboration within and across multiple projects. Work is largely decentralized and loosely coordinated, providing new opportunities but also new challenges. Supporting better and more equitable collaboration in open source will help to sustain the communities of developers and maintainers. A key point of tension is the definition and change of interfaces between different dependent open source projects that become apparent around breaking changes; we found that different ecosystems and corresponding communities have adopted very different coordination and communication strategies around handling breaking changes and absorbing the corresponding costs [FSE 2016, 🖺, 🎞]. We found that repository badges are an effective way to signal qualities and encourage practices without explicit enforcement mechanisms [ICSE 2018]. We also studied how developers collaborate across forks of a repository [ICSE 2020, ESEC/FSE 2019, SANER 2019, ICSE 2018], finding among others several inefficiencies that can be addressed with different development practices [ESEC/FSE 2019] and opportunites to mitigate some inefficiences such as redundant development with suitable tooling [SANER 2019, ICSE 2020].

Adoption of Practices and Tooling
There are many positive practices and useful forms of tooling that are often benefitial to open source projects and their sustainability. Understanding the costs and benefits is crutial, but so are strategies to encourage adoption of good practices and tools by the broader community. We studied the diffusion of practices [ESEC/FSE 2020], which can help design more effective communication strategies. Repository badges seem effective at nudging developers to adopt specific practices, such as submitting more pull requests with tests if the importance of test coverage is signaled through a badge [ICSE 2018, 🖺]. With the example of continuous integration, we also dug deeper to understand problems around tooling and how adoption (or abandonment) of tooling can be understood or influenced [ESEC/FSE 2019, MSR 2018].
Quality Assurance for Highly-Configurable Software Systems
We investigate approaches to scale various quality assurance strategies to entire configuration spaces. Configuration options can change the behavior of a system and can interact with other configuration options, leading to an exponential configuration space, often complicated further by constraints. For example, the Linux kernel has 13,000 compile-time options alone that could be combined into up to 2^13000 configurations; a huge configuration space that can obviously not be assured by looking at one configuration at a time. We investigate a wide range of approaches (including parsing, type checking, data-flow analysis, testing, energy analysis, and sampling) for a large number of languages and environments (conditional compilation in C, load-time options in Java, plugin mechanisms in PHP). Our typical goal is to make assurance judgements for the entire configuration space that yields equivalent results but is much faster than looking at each configuration separately, typically by exploiting the similarities among configurations.
I think variability-related complexity is a fascinating topic. On the surface it seems impossible to deal with the complexity of these huge configuration spaces and it surprising how developers cope at all, but a closer look reveals a lot of structure to how variability is used and how it is different from other sources of complexity. Configuration spaces are large but finite, which opens many interesting possibilities for automated reasoning. Developers intentionally share many implementations across configurations and most configuration options intentionally do not interact. It is this balance between sharing and variability in finite spaces that allows many innovative quality assurance strategies that might not be applicable for other sources of complexity; of course other analyses outside of configurable software systems with similar characteristics can benefit from the same insights.

Variational Analysis
Variational analysis (or variability-aware analysis) is the idea of analyzing the entire configuration space at once instead of analyzing individual configurations either brute force or by sampling. Variational analysis typically represents the entire program and all its variations together and considers those variations in every analysis step. For example, if a variable in a program can have three alternative types depending on two configuration options, a type checker would track all alternative types and their corresponding conditions and make sure that they are used appropriately in every context.
Variational analysis is typically sound and complete with regard to a brute-force strategy—that is it finds exactly the same issues a baseline brute-force analysis would find and introduces no false positives—but much faster because it exploits the similarities in the program. While variations in different parts of the program can interact and lead to an exponential explosion, we have shown empirically for many problems that those interactions, although they exist, are often relatively rare and local, enabling to scale variational analyses to huge configuration spaces as in the Linux kernel with thousands of compile-time options.
We have investigated variational analyses and built tools for parsing [OOPSLA 2011], type checking [ASE 2008, TOSEM 2012, OOPSLA 2012], linker checks (compositionality) [OOPSLA 2012], control-flow and data-flow analysis [ESEC/FSE 2013], and testing [ICSE 2014, FOSD 2012, ASE 2016, GPCE 2018, OOPSLA 2018]. Furthermore, we have investigated general principles, patterns, and data structures for variational analyses [ESEC/FSE 2013, Onward! 2014] and performed a survey of the field [CSUR 2014].

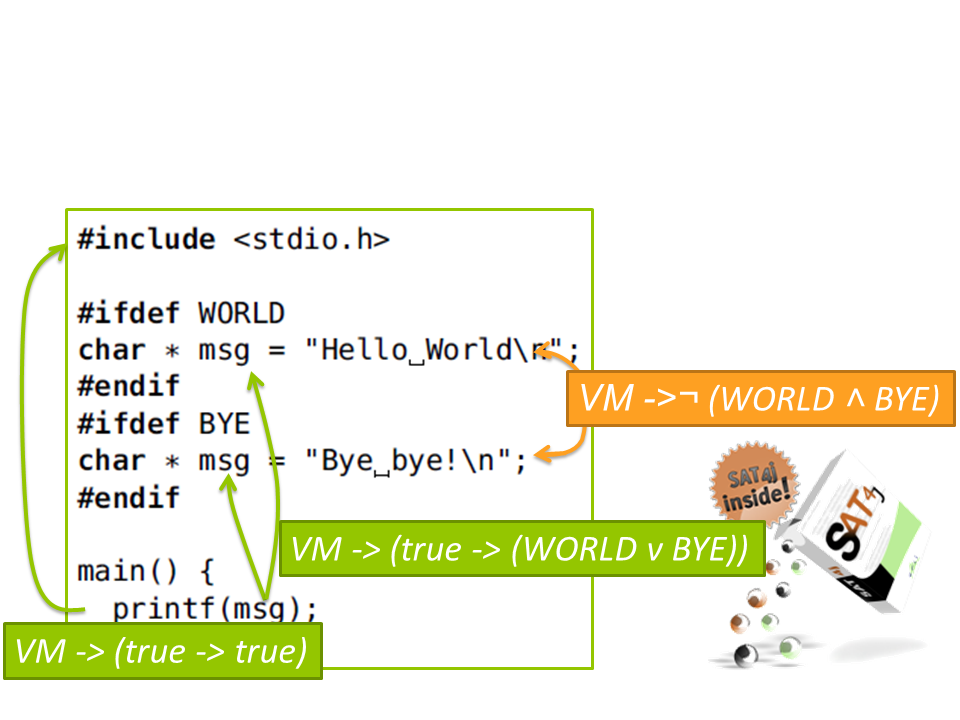
Analysis of Unpreprocessed C Code
With our TypeChef infrastructure, we have built the first sound and complete parser and analysis infrastructure for unpreprocessed C code. Most analyses for C code work on preprocessed code of a single configuration, after expanding macros, including files, and deciding conditional compilation conditions—by preprocessing code, they loose information about other configurations. For the same reason, tools such as refactoring engines that work on unpreprocessed code which a developer edits are very challenging to build. Before TypeChef, parsing unpreprocessed C code was only possible with unsound heuristics or by restricting heavily how developers could use the C preprocessor. The TypeChef lexer and parser explore all possible branches of conditional compilation decisions, all possible macro expansions, and file inclusions and build an abstract syntax tree representing all preprocessor variability of the unpreprocessed C code through choice nodes. TypeChef is sound and complete with regard to parsing all preprocessed configurations in a brute-force fashion, but much faster: it finds exactly the same bugs and does not reject code that could be parsed after preprocessing.
On top of the TypeChef parser, we have built a variational type system and variational linker checks [OOPSLA 2012], a variational data-flow analysis framework [ESEC/FSE 2013, TOSEM 2018], facilities for variational pointer analysis and variational call graphs. Others have used lightweight variations [Medeiros et al. 2014] or have used TypeChef as the basis for imports [Szabó et al. 2015] and refactoring engines [Liebig et al. 2014] that could handle the C preprocessor.
TypeChef has been used to analyze the entire configuration space of the Linux kernel’s x86 architecture (>6000 compile-time options), of Busybox (>800 compile-time options), OpenSSL, and other highly configurable systems written in C.
Variational Type Checking and Data-Flow Analysis
We have built variational type systems, linker checks, and data-flow analyses for compile-time variability in Java and C, again instances of the general idea of variational analysis. When faced with compile-time variability, compiler errors in certain configurations are a common problem, for example, when a function is called in a configuration in which it is not defined. Such problems may surface only in configurations that require specific combinations of multiple options, for example enabling some and disabling others. When end- users perform the configuration as in Linux and most plugin systems, one would like to ensure the absence of configuration-related compilation errors for the entire configuration space.
We built our first variational type system for compile-time variability in Java code and found bugs in various JavaME applications that used compile-time variability [ASE 2008, TOSEM 2012]. Subsequently, we have implemented a variational type system and variational linker checks for unpreprocessed C code on top of TypeChef and found found various variability-related errors in real world software systems, sometimes involving more than 10 configuration options. A key mechanism to scale the analysis of large code bases was to perform compositional analysis analyzing one C file at a time and subsequently performing variational linker checks, for which we have designed and formalized a variational module system [OOPSLA 2012].
Furthermore, we have built a variational static analysis framework on top of TypeChef that can perform typical data-flow analyses as constant propagation and taint tracking over all compile-time configurations [ESEC/FSE 2013, TOSEM 2018]. In addition to the possibility of finding bugs, these analyses provide a foundation for sound variational refactorings of unpreprocessed C code [Liebig et al. 2014].

Variational Execution (Testing)
With variational execution, we try to bring variational analysis to testing and dynamic analyses. Again, we track differences and share similarities across configurations, but instead of tracking alternative types, we track alternative values of variables during execution. That is, we attempt to execute a program across all configurations at once: we track all distinct values a variable could have in any configuration and explore all branches on configuration-related control-flow decisions. In contrast to symbolic execution, we use only concrete values, but a variable may have multiple concrete values in different configurations. When hitting assertions or output, we can simply check all possible values for the entire configuration space. Again, we track differences only where they matter and share similarities across configurations, which allows us to scale over brute-force approaches. We have experimented with different implementations, primarily by lifting interpreters. We created experimental variational interpreters for PHP [ICSE 2014] and Java [Meinicke 2015, ASE 2016, OOPSLA 2018].
Our primary goal is testing highly configurable systems, but we experimented with many other applications of dynamic analyses to large but finite configuration spaces beyond the traditional product line field, including higher-order mutation testing [ESEC/FSE 2020] and program repair [FSE-NIER 2018]. Others have used these techniques also for dynamic information-flow analysis and policy enforcement [Austin et al. 2012, Austin et al. 2013].
Sampling
While I am personally biased toward sound variational analyses that cover entire configuration spaces, we have investigated sampling strategies toward quality assurance. Sampling is by its very nature incomplete with regard to the configuration space because it does not analyze all configurations, but it is typically much easier to perform. Among others, we have compared different sampling strategies and have compared variational analyses to sampling, where variational analysis can provide a ground truth about issues in a system. This allowed us, for example, to study whether the assumptions behind many sampling strategies, such as that most issues involve only few configuration options, hold in practice. In addition, we found that many sampling strategies are only easy to apply when making strong simplifying assumptions, such as that the system does not contain constraints or that each file can be analyzed separately [ESEC/FSE 2013, ICSE 2016].

Feature Interactions
Feature interactions are still a mystery to me. They are emergent properties in a system and surface as interoperability problems. They emerge from a failure of compositionality, when the behavior of combining two parts is unexpected from their individual behaviors. In the common example of flood control and fire control in a building, both work fine in isolation but can be dangerous if combined incorrectly, as flood control can turn off water from the sprinklers in case of a fire. Interactions are often actually intended and desired, so pure isolation is rarely an optimal strategy; for example plugins of a blogging software should often interact to reach a common goal. Although feature interactions have been studied in depth from a requirements perspective in the 90s and some success has been achieved in understanding interactions and designing for them in the telecommunications domain, to me it is still largely unclear how we can detect them in practice or design new systems to allow intentional interactions but prevent undesired ones. For example, how can we ensure orthogonality or isolation of options except for those cases where interactions are explicitly intended? How can we help developers understand such issues despite huge exponential configuration spaces?
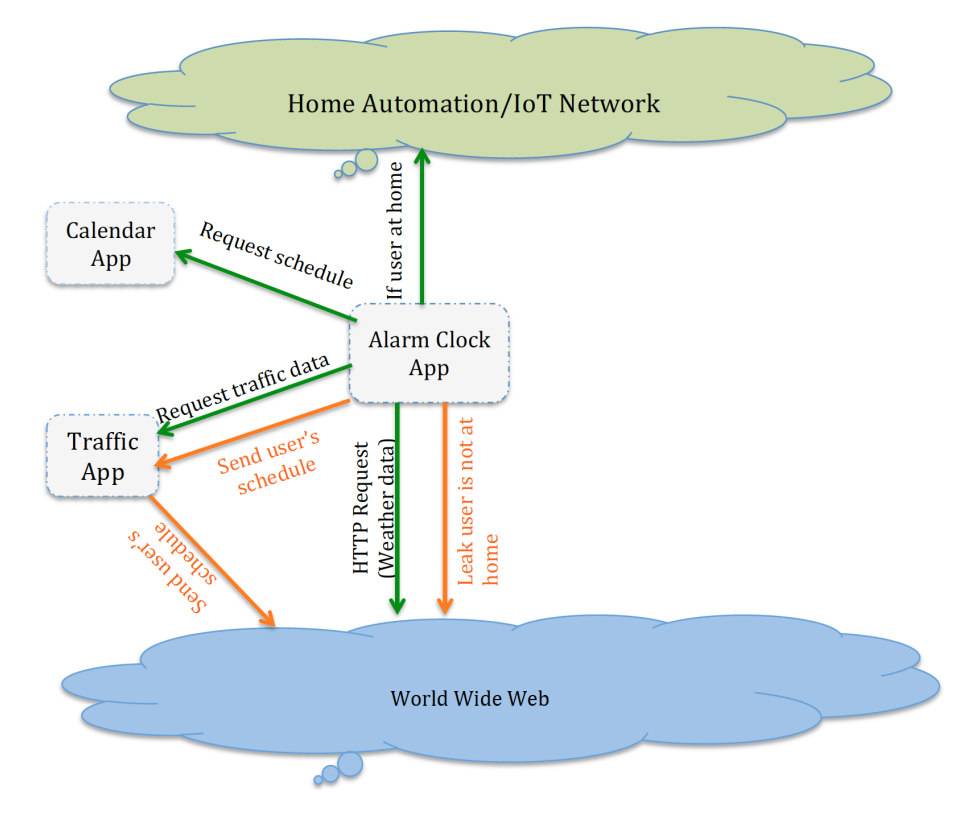
I am interested in understanding how interactions manifest in implementations, for example, at the level of data flow. To that end, we use variational analyses (data flow, variational execution) to understand systems. Only when we understand current practice can we identify common problems and successful patterns for managing interactions. We focus on interactions among options (compile-time, run-time, plugins), but take a very wide view on interactions that includes diverging behavior, alternative values of a variable depending on multiple options, structural interactions as nested #ifdefs, as well as performance interactions. I am mostly interested in interactions at the code level [ASE 2016, GPCE 2018, EMSE 2019, VaMoS 2018, arXiv 2018], but with broad ranges of domains, such as infrastructure software, plugin systems, software ecosystems, home automation, or medical devices.

Variational Specifications
We explore different strategies to specify expected behavior in highly configurable systems. If options may interact, what correct behavior do we expect? How can we specify behavior in an exponential configuration space, when we obviously cannot think about every combination of options separately? How do we encode such specifications in test cases or for static analysis or verification tools? Global specifications that should uniformly hold across all configurations, such as all configurations should be well-typed or should not crash are easy to specify. I believe that the only meaningful scalable strategy to specify expected behavior and detect inconsistencies of interactions is to specify for each feature separately the expected behavior, independent of any other options. Such feature-specific specification will allow us to detect when that feature is negatively influenced by other options [COMNET 2013]. This view shapes my view on interactions and is a main reason for pursuing variational execution as an efficient way of checking such specifications encoded as test cases in large configuration spaces. I believe that writing test cases that assert a feature’s behavior independent from other features, combined with variational execution, will allow us to get a handle on interoperability and detecting feature interactions [ICSE 2014].
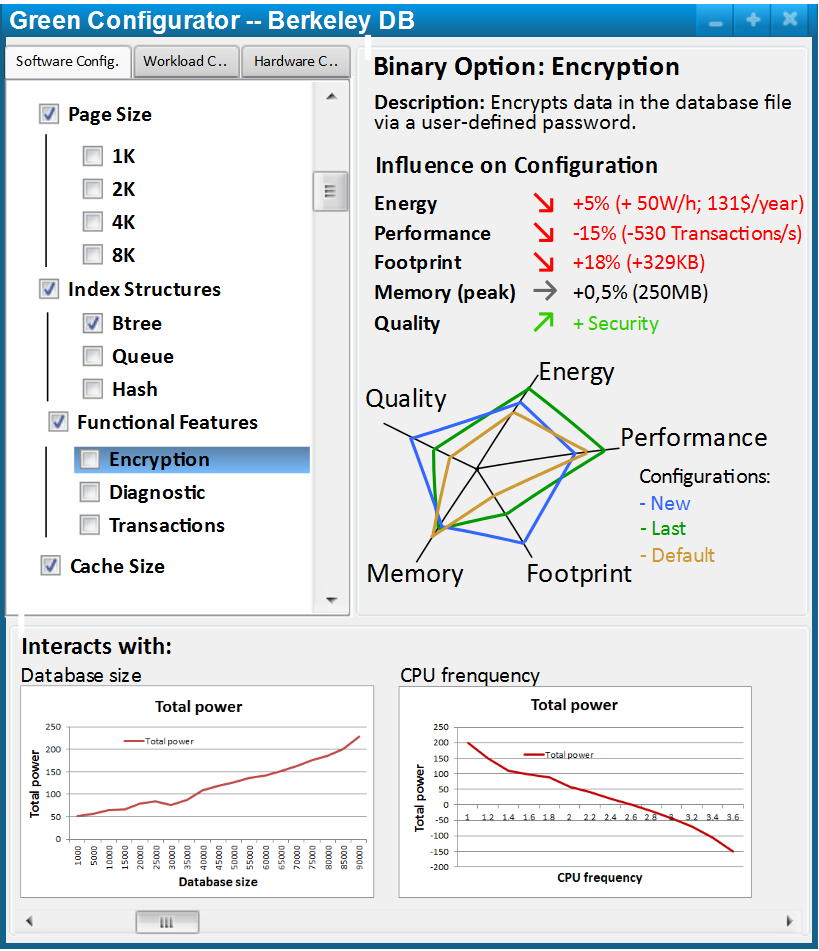
Assuring and Understanding Quality Attributes as Performance and Energy
We explore different approaches to understand how configuration options affect performance, power consumption, and other quality attributes of software systems. With their configuration options, many configurable software systems have a built-in potential to tweak performance and other quality attributes, for example to trade off faster encoding with lower video quality in a video encoder. However, understanding which configuration options affect performance or other quality attributes is difficult. Not all configuration options influence performance significantly and sometimes the interactions of multiple options have strong positive or negative influences—again the scale of the configuration space makes an analysis difficult.
We have focused on building performance-influence models and energy-influence models in a form of sensitivity analysis in which we measure quality attributes in various configurations and subsequently learn a model that describes which options and which interactions influence the quality attribute. These models are suitable for debugging, understanding, predicting, and optimizing quality attributes as performance for highly-configurable software systems. For example, by showing the influence of configuration options on energy consumption, we expect that users make more energy-conscious configuration decisions weighing the benefits of a feature against its cost—in a tool we call green configurator.
We have learned that we can build relatively accurate models even with few measurements and that there are various heuristics for learning about interactions, rooted in common observations in real-world systems [SPLC 2011, ICSE 2012, ESEC/FSE 2015]. Initially, we focused mainly on a black-box approach, where we just measure performance while executing the system, but more recently, we explored how program analysis techniques of the implementation can inform the sampling strategy and reduce the number of measurements [AUSE 2020, ICSE 2021]. In addition, we explored the use of transfer learning to reuse measurements for more accurate learning [SEAMS 2017, ESEC/FSE 2018, ASE 2017].

Security
We investigate assurance strategies and certification mechanisms for highly configurable systems. Many recent high-profile security vulnerabilities have been configuration related. For example, the Heartbleed vulnerability occurred only in optional code that was enabled by default but probably not needed in many real-world scenarios. Vulnerabilities may also arise due to nontrivial interactions of multiple options, even when individual configurations or options have been analyzed. Reducing the attack surface by disabling unneeded functionality and performing security analysis over all configurations (variational analyses) can help addressing security challenges.
We look at security in highly-configurable systems from many angles. Among others we explore variational information-flow analyses to understand how flows differ in different configurations, we investigate whether configuration complexity statistically associates with vulnerabilities in the implementation [SPLC 2016], we investigate how current certification approaches along the lines of Common Criteria can be improved toward supporting easier recertification and certification of systems composed from parts (ecosystems, plugin systems, configurable systems) [arXiv 2019], and we build techniques to contain malicious package updates [ICSE-NIER 2019, ICSE 2021].
Maintenance and Implementation of Highly-Configurable Systems
We are interested in how to best implement highly-configurable systems and software product lines to enable long-term maintenance. There is a huge range of implementation mechanisms, from branches in version control systems, to components and plugin systems, to #ifdefs and specialized languages for crosscutting implementations, all with their distinct tradeoffs [Springer-Verlag 2013]. As with much technical debt, many approaches that are easy to use in the short-term can turn into maintenance nightmares in the long run. In addition to analyzing tradeoffs of existing approaches and developing new implementation approaches, we research tooling, reverse engineering, and migration support for the various implementation techniques.

Reverse Engineering Variability Implementations
We investigate approaches to recover essential information from legacy variability implementations. Product lines are often started with ad-hoc implementations such as branches, command-line options, or ifdefs without much regard for planning, but developers then often get increasingly frustrated with difficult maintenance and increasing complexity. In such cases, we intend to help developers in understanding the current implementations and supporting migrations to more disciplined mechanisms.
We have explored reverse engineering for conditional compilation, command-line options, branches, and build systems. We have built an infrastructure to parse unpreprocessed C code and we explored mechanisms to enforce more disciplined usage of the preprocessor [OOPSLA 2011, TSE 2018], to extract constraints in the configuration space from such implementation [ICSE 2014], and to refactor conditional compilation into other variability mechanisms [GPCE 2009]. For load-time parameters like command-line options and configuration files, we use a variation of taint tracking to identify which (often scattered) statements in Java and Android programs are controlled by these options [ASE 2014]. For branches and clone-and-own development we look into merging and feature location techniques to enable an integration of the various changes in the branches into disciplined variability mechanisms [ESEC/FSE 2011, ICSE 2018]. Finally, we also investigate mechanisms to extract configuration knowledge from build systems [Releng 2015, Releng 2016, GPCE 2017].
Feature Flags
Feature flags (or feature toggles) emerged recently as a design pattern of how to (often temporarily) provide variability in software systems for experimentation, for deployment, and for trunk-based development. Feature flags are broadly used in practice and share many similarities with traditional configuration options, but they also have distinct characteristics, for example, with regard to lifetime expectations, documentation, and testing. We have explored the phenomenon of feature flags and contrasted it with traditional configuration options in order to bring researchers in both communities closer and to learn from each other [ICSE-SEIP 2020, MSR 2020, 🖺].

Feature-Oriented Programming
We have explored alternative language features and composition mechanisms that can support implementing features in product lines. In early work, we explored aspect-oriented programming as a possible means to implement features (identifying lots of problems) [SPLC 2007, JOT 2007] and compared aspect-oriented programming with feature-oriented programming [ISSE 2007, FOSD 2009, Springer-Verlag 2013]. Subsequently, we explored mechanisms to generalize feature-oriented programming to provide uniform mechanisms across multiple languages within the FeatureHouse tool suite [ICSE 2009, TSE 2013, SCP 2012], discuss modularity issues [FOSD 2011, SCP 2012], and to perform various quality assurance activities, such as variational type checking, for these languages [AUSE 2010]. To support teaching of product line development and feature-oriented programming specifically, we developed an Eclipse plugin FeatureIDE that makes the languages and tools more accessible [ICSE 2009, SCP 2014].
Assessing and Understanding Configuration-Related Complexity
We are interested in how developers understand highly-configurable systems and how they handle variability-related complexity. Variability introduces complexity into a system as developers have to think about multiple configurations at the same time. At the same time, the orthogonal nature and the huge but finite configuration spaces are different from many other sources of complexity. In fact, developers often (but not always) seem to be quite capable of handling configuration complexity despite enormous surface complexity one would expect from the exponentially growing configuration space: What distinguishes manageable from not manageable implementations? We have attempted to assess configuration complexity in systems with various metrics [ICSE 2010, ESEM 2011, EMSE 2015], have analyzed how configurability relates to proneness for bugs and vulnerabilities [SPLC 2016], and how we can support developers to handle the complexity with tools and visualizations [EMSE 2012, ICSE 2011, 2012, ICSE 2014, arXiv 2018].

Understanding Preprocessor Use
We empirically analyze how the C preprocessor is used in practice and how developers perceive its use. Conditional compilation with the C preprocessor is one of the most commonly used variability-implementation mechanism in practice. We argue that, when used with some discipline and supported by tooling, conditional compilation can be an easy and effective implementation strategy [JOT 2009, Springer-Verlag 2013] (see also virtual separation of concerns), but uncontrolled use can hinder understanding, quality assurance, and tool support substantially. We have investigated at scale how the C preprocessor is used in practice, both in dozens of open source programs [ICSE 2010, AOSD 2011] as well as in industrial software product lines [EMSE 2015]. In addition, we have interviewed C programmers to understand how they perceive the challenges of the C preprocessor [Springer-Verlag 2013].

Tracking Load-Time Configuration Options
We track how load-time configuration options are used within a program to identify where configuration-related code is actually implemented and which configurations interact. Load-time variability, for which configuration options are loaded from command-line options or configuration files and propagated through normal variables to control-flow decisions, is a common implementation strategy for variability. Unfortunately, in growing and evolving systems it can be difficult to keep track where the configurable part of the system is actually implemented as variability can become hard to distinguish from other computations in the system. We developed a specialized form of slicing, based on taint tracking, to identify where and how load-time options are used for control-flow decisions in the program. We create a configuration map that indicates for each line of code under which configurations it can be executed, similar to traceability one might expect from using conditional compilation directives around those code fragments [ASE 2014, TSE 2018]. Exploiting the fact that configuration options are used differently from other state in the program, we achieve a highly accurate tracking in most programs.
Build Systems
We investigate how to extract configuration knowledge from build systems. Build systems control a significant amount of compile-time variability in many software systems, but are often encoded in various, hard to analyze tools and languages such as make. The complicated build logic of many project can make it difficult to answer simple questions, such as, in which configurations is a file even compiled or which extra parameters are passed in which configurations. The problem of extracting configuration knowledge is limiting many quality assurance and reverse engineering approaches in their accuracy. So far, we have pursued a static extraction approach based on symbolic execution of make files [Releng 2015] and investigate other build systems and other analysis strategies [Releng 2016, GPCE 2017].
Modularity and Feature Interactions
We investigate how to modularity implement features in a way that avoids accidental feature interactions but still allows intended interactions among features. For example, a total isolation of features would be possible, but would prevent intended interactions as well. We study various ecosystems to understand what implementation mechanisms they use to control interactions, such as Android [MobileDeLi 2015, MSR 2016], and explore alternative forms of implementation. Among others, we have designed a module system that makes variability inside a module and its interface very explicit [OOPSLA 2012]. However, how to best implement variability to tame interactions but allow sufficient flexibility is still an open research challenge.
Working with Imperfect Modularity
We investigate mechanisms to support developers in scenarios where modularity, the separation of changeable internals from stable interfaces, reaches its limits. We then complement traditional modularity mechanisms with tool support and awareness mechanisms. Challenges to classic modularity mechanisms includes crosscutting concerns and feature implementations that are difficult or inefficient to modularize, as well as large and distributed development activities in software ecosystems without central planning. Software product lines have been an excellent case study for modularity challenges, because variable source code often is an important concern that is often challenging to modularize, due to its scattered and fine-grained nature and common implementation with control-flow mechanisms (if statements) and conditional compilation (#ifdef directives).
Virtual Separation of Concerns
Observing the common crosscutting implementations of features in product lines, often scattered with conditional compilation directives, we discussed whether modularizing those would be worth the required costs [FOSD 2011]. We argue that for many kinds of implementations, it might be simpler to provide tool support that would mimic several benefits of modularity, while still preserving the simplicity of scattered implementations. In what we call virtual separation of concerns, tool support synthesizes editable views on individual features and configurations of a product. Developers can switch between different views, depending on their tasks; tooling emulates many navigation and cohesion benefits otherwise expected from modularity [JOT 2009]. Static analysis can even compute certain interfaces on demand (called emergent interfaces) that can summarize the interactions with hidden code [ICSE 2014]. Finally, we have developed prototype tools that would rewrite the actual code base between virtual and actual physical separation [GPCE 2009]. While virtual separation of concerns cannot achieve separate compilation or open-world reasoning, it might be a lightweight practical alternative for many development scenarios where classic modularity is not practical or too expensive.

Awareness for Evolution in Software Ecosystems
Breaking change is inevitable in the long run and we strive to complement classical modularity with tailored awareness mechanisms. The scale of software ecosystems makes it likely that interfaces among modules (packages, components, plugins) will eventually evolve with rippling effects for other modules. Their distributed nature makes central planning (e.g., a change control board) unrealistic. We expect that change is generally inevitable and, while modularity can encapsulate a lot of change, we prefer to support developers in those cases where modularity does not protect them from change.
We study how developers plan changes and cope with changes in practice and how those practices are influenced by community values and technologies of the ecosystem [SCGSE 2015, FSE 2016]. Among others, we found that developers are overwhelmed with raw notification feeds but have found many mitigation strategies to cope with upstream change. We develop tailored awareness mechanisms that identify which changes are relevant for individual users of a software package to allow a timely reaction [IEEE-Sw 2015, JSEP 2018].
Conceptual Discussions
What might modularity look like for small and scattered features in a product line? How does one modularize interacting features to still enable flexible composition? Does classical logic correspond with how humans think about modules? How might alternative modularity mechanisms look like? Can tool support replace functions of traditional modularity?
We investigated from a conceptual perspective assumptions, costs, and limitations of modularity, both in the context of scattered variability implementations [FOSD 2011] and more broadly from a philosophical perspective [ECOOP 2011].
Variability Mechanisms Beyond Configurable Software Systems
We are increasingly interested in applying analysis mechanisms developed for configurable systems beyond traditional application areas of software product lines. Many technologies that we have developed for large finite configuration spaces apply also for other problems that explore large design spaces of different options, such as speculative analyses exploring effects of many potential changes and their interactions. Among others, we have also found, somewhat surprisingly, that our infrastructure for parsing unpreprocessed C code comes in very handy for analyzing PHP code.

Developer Support and Quality Assurance for PHP
We developed a technique to analyze HTML, CSS, and Javascript code while it is still embedded as string literals in PHP code. PHP web application have the interesting characteristic of staged programs, where the server-side PHP code is executed to produce a client-side HTML and Javascript program. As a consequence, it is difficult to analyze the client-side code before the server-side code is executed. To solve this cross-stage analysis, we symbolically execute the server-side code to approximate all client-side output. The approximated client-side code contains symbolic values and decisions from control-flow decisions. Interestingly, this can be interpreted similar to unpreprocessed C code with conditional output and we can use the same variational parsers from TypeChef to build variational representations of the HTML DOM and JavaScript programs, and we can subsequently build variational call graphs on top to enable various forms of tool support from navigation, to bug detection, to test quality assessment, to refactoring, and to slicing [FSE 2014, ESEC/FSE 2015, ICSE 2015, AUSE 2019]. This is a perfect example, where techniques originally developed for product lines can help to solve problems entirely outside the product line domain, in this case the analysis of staged programs.

Sensitivity Analysis
Performance analysis of highly configurable systems can be generalized as a form of sensitivity analysis. The same techniques we use to learn performance-influence models can be used to understand design spaces and consequences of changes in domains outside of traditional product lines, as long as we can evaluate the impact of these changes in an interpreter. For example, we can model which changes to parameters or variable types in a robotics or high-performance computing have a significant impact on performance or accuracy [SEAMS 2019, IEEE-Sw 2019, WSR 2016]. There is a broad field of potential application areas that potentially share similar characteristics about the nature of interactions of changes, where both black-box and white-box sensitivity- analysis techniques for highly-configurable systems can be reused.

Mutation Testing and Program Repair
We explore variational-analysis techniques for exploring the effect and the interactions of multiple potential changes to a software system. By encoding each potential change as a configuration decision, we can use techniques such as variational execution to see which change or which combination of changes break a test. We found that these techniques allow efficient exploration of large search spaces, as used for mutation-based testing or automatic program repair [ESEC/FSE 2020, FSE-NIER 2018].
Other Topics
We are generally open to research and collaborations in a broad spectrum of software engineering questions. We have worked on dynamic software updates [SPE 2013], embedded and extensible domain specific languages [OOPSLA 2011, GPCE 2011], software merging [ESEC/FSE 2011, ASE 2017, AUSE 2018], and exploring various empirical methods, including assessing program comprehension as a confounding factor [EMSE 2014], self-adaptation in robots [SEAMS 2019, IEEE-Sw 2019], and using fMRI scanners [ICSE 2014, ESEC/FSE 2017, TSE 2018].

Understanding Program Comprehension with fMRI
We analyzed how developers understand programs by directly observing brain area activations inside an fMRI scanner. While our initial project was focused on establishing the feasibility of fMRI as an technique for studying program comprehension (we confirmed many expected activations regarding short-term memory and language comprehension), this line of research can potentially help us in the long run to understand what makes programs complex and what form of complexity developers can handle well and what forms they struggle with. It may have further implications about how to teach programming or design programming languages [ICSE 2014, ESEC/FSE 2017, TSE 2018].