Allen [2] was the first to propose that a backtracking algorithm [11] could be used to find a consistent scenario of an IA network. In the worst case, a backtracking algorithm can take an exponential amount of time to complete. This worst case also applies here as Vilain and Kautz [27,28] show that finding a consistent scenario is NP-complete for IA networks. In spite of the worst case estimate, backtracking algorithms can work well in practice. In this section, we examine methods for speeding up a backtracking algorithm for finding a consistent scenario and present results on how well the algorithm performs on different classes of problems. In particular, we compare the efficiency of the algorithm on two alternative formulations of the problem: one that has previously been proposed by others and one that we have proposed [25]. We also improve the efficiency of the algorithm by designing heuristics for ordering the instantiation of the variables and for ordering the values in the domains of the variables.
As our starting point, we modeled our backtracking algorithm after that of Ladkin and Reinefeld [16] as the results of their experimentation suggests that it is very successful at finding consistent scenarios quickly. Following Ladkin and Reinefeld our algorithm has the following characteristics: preprocessing using a path consistency algorithm, static order of instantiation of the variables, chronological backtracking, and forward checking or pruning using a path consistency algorithm. In chronological backtracking, when the search reaches a dead end, the search simply backs up to the next most recently instantiated variable and tries a different instantiation. Forward checking [13] is a technique where it is determined and recorded how the instantiation of the current variable restricts the possible instantiations of future variables. This technique can be viewed as a hybrid of tree search and consistency algorithms (see [21,23]). (See [7] for a general survey on backtracking.)
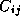 is the label on edge (i, j). The traditional
method for finding a consistent scenario of an IA network
is to search for a subnetwork S of a network C such that,
is the label on edge (i, j). The traditional
method for finding a consistent scenario of an IA network
is to search for a subnetwork S of a network C such that,
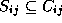 ,
,
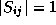 , for all i, j, and
, for all i, j, and
Our alternative formulation is based on results for two
restricted classes of IA networks, denoted here as SA
networks and NB networks. In IA networks, the relation
between two intervals can be any subset of I, the set of all
thirteen basic relations. In SA networks [27],
the allowed relations between two intervals are only those
subsets of I that can be translated, using the relations {<,
 , =, >,
, =, >,  ,
,  },
into conjunctions of
relations between the endpoints of the intervals. For example,
the IA network in Figure 2a is also an
SA network. As a specific example, the interval relation ``A
{bi,mi} B'' can be expressed as the conjunction of point relations,
},
into conjunctions of
relations between the endpoints of the intervals. For example,
the IA network in Figure 2a is also an
SA network. As a specific example, the interval relation ``A
{bi,mi} B'' can be expressed as the conjunction of point relations,
 where
where 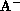 and
and  represent the start and end
points of interval A, respectively.
(See [18,26] for an enumeration of the allowed relations for SA networks.)
In NB networks [22], the allowed
relations between two intervals are only those subsets of I
that can be translated, using the relations {<,
represent the start and end
points of interval A, respectively.
(See [18,26] for an enumeration of the allowed relations for SA networks.)
In NB networks [22], the allowed
relations between two intervals are only those subsets of I
that can be translated, using the relations {<,  , =,
>,
, =,
>,  ,
,  }, into conjunctions of Horn clauses that
express the relations between the endpoints of the intervals.
The set of NB relations is a strict superset of the SA relations.
}, into conjunctions of Horn clauses that
express the relations between the endpoints of the intervals.
The set of NB relations is a strict superset of the SA relations.
Our alternative formulation is as follows. We describe the method in terms of SA networks, but the same method applies to NB networks. The idea is that, rather than search directly for a consistent scenario of an IA network as in previous work, we first search for something more general: a consistent SA subnetwork of the IA network. That is, we use backtrack search to find a subnetwork S of a network C such that,
 ,
,
 is an allowed relation for SA networks,
for all i, j, and
is an allowed relation for SA networks,
for all i, j, and
 = 1. The key idea in
our proposal is that we decompose the labels into the largest
possible sets of basic relations that are allowed for SA
networks and search through these decompositions. This can
considerably reduce the size of the search space. For example,
suppose the label on an edge is {b,bi,m,o,oi,si}. There are
six possible ways to label the edge with a singleton label:
{b}, {bi}, {m}, {o}, {oi}, {si}, but only two
possible ways to label the edge if we decompose the labels into
the largest possible sets of basic relations that are allowed for
SA networks: {b,m,o} and {bi,oi,si}. As another
example, consider the network shown in Figure 2a.
When searching through alternative singleton labelings, the worst
case size of the search space is
= 1. The key idea in
our proposal is that we decompose the labels into the largest
possible sets of basic relations that are allowed for SA
networks and search through these decompositions. This can
considerably reduce the size of the search space. For example,
suppose the label on an edge is {b,bi,m,o,oi,si}. There are
six possible ways to label the edge with a singleton label:
{b}, {bi}, {m}, {o}, {oi}, {si}, but only two
possible ways to label the edge if we decompose the labels into
the largest possible sets of basic relations that are allowed for
SA networks: {b,m,o} and {bi,oi,si}. As another
example, consider the network shown in Figure 2a.
When searching through alternative singleton labelings, the worst
case size of the search space is
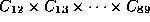 = 314
(the edges labeled with I must be included in the
calculation). But when decomposing the labels into the largest
possible sets of basic relations that are allowed for SA
networks and searching through the decompositions, the size of
the search space is 1, so no backtracking is necessary (in
general, the search is, of course, not always backtrack free).
= 314
(the edges labeled with I must be included in the
calculation). But when decomposing the labels into the largest
possible sets of basic relations that are allowed for SA
networks and searching through the decompositions, the size of
the search space is 1, so no backtracking is necessary (in
general, the search is, of course, not always backtrack free).
To test whether an instantiation of a variable is consistent with instantiations of past variables and with possible instantiations of future variables, we use an incremental path consistency algorithm (in Step 1 of Figure 3 instead of initializing L to be all edges, it is initialized to the single edge that has changed). The result of the backtracking algorithm is a consistent SA subnetwork of the IA network, or a report that the IA network is inconsistent. After backtracking completes, a solution of the SA network can be found using a fast algorithm given by van Beek [25].
The idea behind variable ordering heuristics is to instantiate variables first that will constrain the instantiation of the other variables the most. That is, the backtracking search attempts to solve the most highly constrained part of the network first. Three heuristics we devised for ordering the variables (edges in the IA network) are shown in Figure 9. For our alternative formulation, cardinality is redefined to count the decompositions rather than the elements of a label. The variables are put in ascending order. In our experiments the ordering is static---it is determined before the backtracking search starts and does not change as the search progresses. In this context, the cardinality heuristic is similar to a heuristic proposed by Bitner and Reingold [5] and further studied by Purdom [24].
The idea behind value ordering heuristics is to order the values in the domains of the variables so that the values most likely to lead to a solution are tried first. Generally, this is done by putting values first that constrain the choices for other variables the least. Here we propose a novel technique for value ordering that is based on knowledge of the structure of solutions. The idea is to first choose a small set of problems from a class of problems, and then find a consistent scenario for each instance without using value ordering. Once we have a set of solutions, we examine the solutions and determine which values in the domains are most likely to appear in a solution and which values are least likely. This information is then used to order the values in subsequent searches for solutions to problems from this class of problems. For example, five problems were generated using the model S(100, 1/4) and consistent scenarios were found using backtracking search and the variable ordering heuristic constraintedness/weight/cardinality. After rounding to two significant digits, the relations occurred in the solutions with the following frequency,

As an example of using this information to order the values in a domain, suppose that the label on an edge is {b,bi,m,o,oi,si}. If we are decomposing the labels into singleton labels, we would order the values in the domain as follows (most preferred first): {b}, {bi}, {o}, {oi}, {m}, {si}. If we are decomposing the labels into the largest possible sets of basic relations that are allowed for SA networks, we would order the values in the domain as follows: {b,m,o}, {bi,oi,si}, since 1900 + 20 + 220 > 1900 + 220 + 14. This technique can be used whenever something is known about the structure of solutions.
The first set of experiments, summarized in
Figure 10, examined the effect of
problem formulation on the execution time of the backtracking
algorithm. We implemented three versions of the algorithm that
were identical except that one searched through singleton
labelings (denoted hereafter and in Figure 10
as the SI method) and the other two searched through
decompositions of the labels into the largest possible allowed
relations for SA networks and NB networks, respectively.
All of the methods solved the same set of random problems drawn
from B(n) and were also applied to Benzer's matrix
(denoted + and  in
Figure 10). For each problem, the
amount of time required to solve the given IA network was
recorded. As mentioned earlier, each IA network was
preprocessed with a path consistency algorithm before
backtracking search. The timings include this preprocessing
time. The experiments indicate that the speedup by using the
SA decomposition method can be up to three-fold over the
SI method. As well,
the SA decomposition method was able to solve larger
problems before running out of space (n = 250 versus n = 175).
The NB decomposition method gives exactly the same result as for
the SA method on these problems because of the structure of the
constraints.
We also tested
all three methods on a set of random problems drawn from
S(100, p), where p = 1, 3/4, 1/2, and 1/8.
In these experiments,
the SA and NB methods were consistently
twice as fast as the SI method.
As well, the NB method showed no advantage over the SA method
on these problems. This is surprising as the branching factor, and
hence the size of the search space, is smaller for the NB
method than for the SA method.
in
Figure 10). For each problem, the
amount of time required to solve the given IA network was
recorded. As mentioned earlier, each IA network was
preprocessed with a path consistency algorithm before
backtracking search. The timings include this preprocessing
time. The experiments indicate that the speedup by using the
SA decomposition method can be up to three-fold over the
SI method. As well,
the SA decomposition method was able to solve larger
problems before running out of space (n = 250 versus n = 175).
The NB decomposition method gives exactly the same result as for
the SA method on these problems because of the structure of the
constraints.
We also tested
all three methods on a set of random problems drawn from
S(100, p), where p = 1, 3/4, 1/2, and 1/8.
In these experiments,
the SA and NB methods were consistently
twice as fast as the SI method.
As well, the NB method showed no advantage over the SA method
on these problems. This is surprising as the branching factor, and
hence the size of the search space, is smaller for the NB
method than for the SA method.

Figure 10: Effect of decomposition method on average time (sec.) of
backtracking algorithm. Each data point is the average of 100
tests on random instances of IA networks drawn from
B(n); the coefficient of variation (standard deviation /
average) for each set of 100 tests is bounded by
0.15

Figure 11: Effect of variable and value ordering heuristics on time
(sec.) of backtracking algorithm. Each curve represents 100
tests on random instances of IA networks drawn from
S(100, 1/4) where the tests are ordered by time taken to solve
the instance. The backtracking algorithm used the SA
decomposition method.
The second set of experiments, summarized in Figure 11, examined the effect on the execution time of the backtracking algorithm of heuristically ordering the variables and the values in the domains of the variables before backtracking search begins. For variable ordering, all six permutations of the cardinality, constraint, and weight heuristics were tried as the primary, secondary, and tertiary sorting keys, respectively. As a basis of comparison, the experiments included the case of no heuristics. Figure 11 shows approximate cumulative frequency curves for some of the experimental results. Thus, for example, we can read from the curve representing heuristic value ordering and best heuristic variable ordering that approximately 75% of the tests completed within 20 seconds, whereas with random value and variable ordering only approximately 5% of the tests completed within 20 seconds. We can also read from the curves the 0, 10, ..., 100 percentiles of the data sets (where the value of the median is the 50 th percentile or the value of the 50 th test). The curves are truncated at time = 1800 (1/2 hour), as the backtracking search was aborted when this time limit was exceeded.
In our experiments we found that S(100, 1/4) represents a particularly difficult class of problems and it was here that the different heuristics resulted in dramatically different performance, both over the no heuristic case and also between the different heuristics. With no value ordering, the best heuristic for variable ordering was the combination constraintedness/weight/cardinality where constraintedness is the primary sorting key and the remaining keys are used to break subsequent ties. Somewhat surprisingly, the best heuristic for variable ordering changes when heuristic value ordering is incorporated. Here the combination weight/constraintedness/cardinality works much better. This heuristic together with value ordering is particularly effective at ``flattening out'' the distribution and so allowing a much greater number of problems to be solved in a reasonable amount of time. For S(100, p), where p = 1, 3/4, 1/2, and 1/8, the problems were much easier and all but three of the hundreds of tests completed within 20 seconds. In these problems, the heuristic used did not result in significantly different performance.
In summary, the experiments indicate that by changing the decomposition method we are able to solve larger problems before running out of space (n = 250 vs n = 175 on a machine with 8 megabytes; see Figure 10). The experiments also indicate that good heuristic orderings can be essential to being able to find a consistent scenario of an IA network in reasonable time. With a good heuristic ordering we were able to solve much larger problems before running out of time (see Figure 11). The experiments also provide additional evidence for the efficacy of Ladkin and Reinefeld's [16,17] algorithm. Nevertheless, even with all of our improvements, some problems still took a considerable amount of time to solve. On consideration, this is not surprising. After all, the problem is known to be NP-complete.
