Path consistency or transitive closure algorithms [1,19,20] are important for temporal reasoning. Allen [2] shows that a path consistency algorithm can be used as a heuristic test for whether an IA network is consistent (sometimes the algorithm will report that the information is consistent when really it is not). A path consistency algorithm is useful also in a backtracking search for a consistent scenario where it can be used as a preprocessing algorithm [19,16] and as an algorithm that can be interleaved with the backtracking search (see the next section; [21,16]). In this section, we examine methods for speeding up a path consistency algorithm.
The idea behind the path consistency algorithm is the following.
Choose any three vertices i, j, and k in the network. The
labels on the edges (i, j) and (j, k) potentially constrain
the label on the edge (i, k) that completes the triangle. For
example, consider the three vertices Stack(A,B), On(A,B), and
Goal in Figure 2a.
From Stack(A,B) {m} On(A,B) and On(A,B) {di} Goal
we can deduce that Stack(A,B) {b} Goal and therefore can
change the label on that edge from I, the set of all basic
relations, to the singleton set {b}.
To perform this deduction, the algorithm uses the operations of
set intersection ( ) and composition (
) and composition ( ) of labels and
checks whether
) of labels and
checks whether 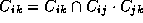 , where
, where
 is the label on edge (i, k). If
is the label on edge (i, k). If  is updated,
it may further constrain other labels, so (i, k) is added to a
list to be processed in turn, provided that the edge is not
already on the list. The algorithm iterates until no more such
changes are possible.
A unary operation, inverse, is also used in the algorithm. The
inverse of a label is the inverse of each of its elements (see
Figure 1 for the inverses of the basic relations).
is updated,
it may further constrain other labels, so (i, k) is added to a
list to be processed in turn, provided that the edge is not
already on the list. The algorithm iterates until no more such
changes are possible.
A unary operation, inverse, is also used in the algorithm. The
inverse of a label is the inverse of each of its elements (see
Figure 1 for the inverses of the basic relations).
We designed and experimentally evaluated techniques for improving
the efficiency of a path consistency algorithm. Our starting
point was the variation on Allen's [2] algorithm shown
in Figure 3. For an implementation of the algorithm to
be efficient, the intersection and composition operations on
labels must be efficient (Steps 5 & 10). Intersection was made
efficient by implementing the labels as bit vectors. The
intersection of two labels is then simply the logical AND of two
integers. Composition is harder to make efficient.
Unfortunately, it is impractical to implement the composition of
two labels using table lookup as the table would need to be of
size 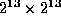 , there being
, there being  possible
labels.
possible
labels.

Figure 3: Path consistency algorithm for IA networks
We experimentally compared two practical methods for composition
that have been proposed in the literature.
Allen [2] gives a method for composition which uses a
table of size 13  13. The table gives the composition of
the basic relations
(see [2] for the table).
The composition of two labels is computed by a nested loop that
forms the union of the pairwise composition of the basic
relations in the labels.
Hogge [14] gives a method for composition which uses
four tables of size
13. The table gives the composition of
the basic relations
(see [2] for the table).
The composition of two labels is computed by a nested loop that
forms the union of the pairwise composition of the basic
relations in the labels.
Hogge [14] gives a method for composition which uses
four tables of size
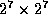 ,
,
 ,
,
 , and
, and
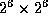 .
The composition of two labels is computed by taking the union of
the results of four array references (H. Kautz independently
devised a similar scheme).
In our experiments, the implementations of the two methods
differed only in how composition was computed. In both, the
list, L, of edges to be processed was implemented using a
first-in, first-out policy (i.e., a stack).
.
The composition of two labels is computed by taking the union of
the results of four array references (H. Kautz independently
devised a similar scheme).
In our experiments, the implementations of the two methods
differed only in how composition was computed. In both, the
list, L, of edges to be processed was implemented using a
first-in, first-out policy (i.e., a stack).
We also experimentally evaluated methods for reducing the number of composition operations that need to be performed. One idea we examined for improving the efficiency is to avoid the computation when it can be predicted that the result will not constrain the label on the edge that completes the triangle. Three such cases we identified are shown in Figure 4. Another idea we examined, as first suggested by Mackworth [19], is that the order that the edges are processed can affect the efficiency of the algorithm. The reason is the following. The same edge can appear on the list, L, of edges to be processed many times as it progressively gets constrained. The number of times a particular edge appears on the list can be reduced by a good ordering. For example, consider the edges (3, 1) and (3, 5) in Figure 2a. If we process edge (3, 1) first, edge (3, 2) will be updated to {o,oi,s,si,d,di,f,fi,eq} and will be added to L (k = 2 in Steps 5-9). Now if we process edge (3, 5), edge (3, 2) will be updated to {o,s,d} and will be added to L a second time. However, if we process edge (3, 5) first, (3, 2) will be immediately updated to {o,s,d} and will only be added to L once.
Three heuristics we devised for ordering the edges are shown in Figure 9. The edges are assigned a heuristic value and are processed in ascending order. When a new edge is added to the list (Steps 9 & 14), the edge is inserted at the appropriate spot according to its new heuristic value. There has been little work on ordering heuristics for path consistency algorithms. Wallace and Freuder [29] discuss ordering heuristics for arc consistency algorithms, which are closely related to path consistency algorithms. Two of their heuristics cannot be applied in our context as the heuristics assume a constraint satisfaction problem with finite domains, whereas IA networks are examples of constraint satisfaction problems with infinite domains. A third heuristic (due to B. Nudel, 1983) closely corresponds to our cardinality heuristic.
All experiments were performed on a Sun 4/25 with 12 megabytes of memory. We report timings rather than some other measure such as number of iterations as we believe this gives a more accurate picture of whether the results are of practical interest. Care was taken to always start with the same base implementation of the algorithm and only add enough code to implement the composition method, new technique, or heuristic that we were evaluating. As well, every attempt was made to implement each method or heuristic as efficiently as we could.
Given our implementations, Hogge's method for composition was found to be more efficient than Allen's method for both the benchmark problem and the random instances (see Figures 5-8). This much was not surprising. However, with the addition of the skipping techniques, the two methods became close in efficiency. The skipping techniques sometimes dramatically improved the efficiency of both methods. The ordering heuristics can improve the efficiency, although here the results were less dramatic. The cardinality heuristic and the constraintedness heuristic were also tried for ordering the edges. It was found that the cardinality heuristic was just as costly to compute as the weight heuristic but did not out perform it. The constraintedness heuristic reduced the number of iterations but proved too costly to compute. This illustrates the balance that must be struck between the effectiveness of a heuristic and the additional overhead the heuristic introduces.
For S(n, p), the skipping techniques and the weight
ordering heuristic together can result in up to a ten-fold
speedup over an already highly optimized implementation using
Hogge's method for composition. The largest improvements in
efficiency occur when the IA networks are sparse (p is
smaller). This is encouraging for it appears that the problems
that arise in planning and molecular biology are also sparse.
For B(n) and Benzer's matrix, the speedup is approximately
four-fold. Perhaps most importantly, the execution times
reported indicate that the path consistency algorithm, even
though it is an O( ) algorithm, can be used on
practical-sized problems.
In Figure 8, we show how well the
algorithms scale up. It can be seen that the algorithm that
includes the weight ordering heuristic out performs all others.
However, this algorithm requires much space and the largest
problem we were able to solve was with 500 intervals.
The algorithms that included only the skipping techniques were
able to solve much larger problems before running out of space
(up to 1500 intervals) and here the constraint was the time it
took to solve the problems.
) algorithm, can be used on
practical-sized problems.
In Figure 8, we show how well the
algorithms scale up. It can be seen that the algorithm that
includes the weight ordering heuristic out performs all others.
However, this algorithm requires much space and the largest
problem we were able to solve was with 500 intervals.
The algorithms that included only the skipping techniques were
able to solve much larger problems before running out of space
(up to 1500 intervals) and here the constraint was the time it
took to solve the problems.
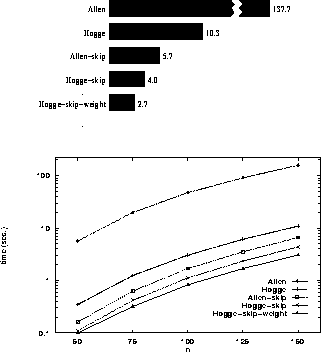
Figure 6: Effect of heuristics on average time (sec.) of path
consistency algorithms. Each data point is the average of 100
tests on random instances of IA networks drawn from
B(n); the coefficient of variation (standard deviation /
average) for each set of 100 tests is bounded by
0.20
Figure 5: Effect of heuristics on time (sec.) of path consistency
algorithms applied to Benzer's matrix
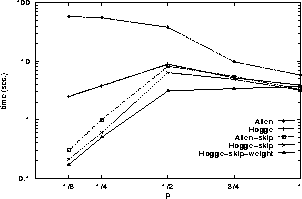
Figure 7: Effect of heuristics on average time (sec.) of path
consistency algorithms. Each data point is the average of 100
tests on random instances of IA networks drawn from
S(100, p); the coefficient of variation (standard deviation /
average) for each set of 100 tests is bounded by
0.25

Figure 8: Effect of heuristics on average time (sec.) of path
consistency algorithms. Each data point is the average of 10
tests on random instances of IA networks drawn from
S(n, 1/4) and
B(n); the coefficient of variation (standard deviation /
average) for each set of 10 tests is bounded by
0.35
