


Next: Explicit Solution in the
Up: Calculating Rule Vectors using
Previous: Optimizing in the Setting
As previously argued in Theorem 4, minimizing 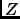 in the setting of Schapire
in the setting of Schapire 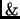 Singer (1998) can be done optimally, but at the expense of complex optimization procedures, with large complexities. One can wonder whether such procedures, to optimize only the computation of
Singer (1998) can be done optimally, but at the expense of complex optimization procedures, with large complexities. One can wonder whether such procedures, to optimize only the computation of 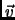 (a small part of WIDC), are really well worth the adaptation to our setting, in which more values are authorized. We are now going to show that a much simpler combinatorial procedure, with comparatively very low complexity, can bring optimal results in fairly general situations. The most simple way to describe most of these situations is to make the following assumption on the examples:
(a small part of WIDC), are really well worth the adaptation to our setting, in which more values are authorized. We are now going to show that a much simpler combinatorial procedure, with comparatively very low complexity, can bring optimal results in fairly general situations. The most simple way to describe most of these situations is to make the following assumption on the examples:
- (
 )
)
- Each example used to compute has only one ``1'' in its class vector.
A careful reading of assumption () reveals that it implies that each example belongs to exactly one class, but it does not prevent an observation to be element of more than one class, as long as different examples sharing the same observation have different classes (the ``1'' of the class vectors is in different positions among these examples). Therefore, even if it does not integrate the most general features of the ranking loss setting, our assumption still authorizes to consider problems with non zero Bayes optimum. This is really interesting, as many commonly used datasets fall into the category of our assumption, as for example many datasets of the UCI repository of Machine Learning database [Blake et al.1998]. Finally, even if the assumption does not hold, we show that in many of the remaining (interesting) cases, our approximation algorithm is asymptotically optimal, that is, finds solutions closer to the minimal value of as 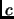 increases.
increases.
Suppose for now that () holds. Our objective is to calculate the vector of some monomial  . We use the shorthands
. We use the shorthands
 to denote the sum of weights of the examples satisfying and belonging respectively to classes
to denote the sum of weights of the examples satisfying and belonging respectively to classes
 . We want to minimize as proposed in eq. (3). Suppose without loss of generality that
. We want to minimize as proposed in eq. (3). Suppose without loss of generality that
otherwise, reorder the classes so that they verify this assertion. Given only three possible values for each component of , the testing of all 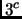 possibilities for is exponential and time-consuming. But we can propose a very fast approach. We have indeed
possibilities for is exponential and time-consuming. But we can propose a very fast approach. We have indeed
Proof: See the Appendix.

Thus, the optimal does not belong to a set of cardinality , but to a set of cardinality  . Our algorithm is then straightforward: simply explore this set of elements, and keep the vector having the lowest value of . Note that this combinatorial algorithm has the advantage to be adaptable to more general settings in which
. Our algorithm is then straightforward: simply explore this set of elements, and keep the vector having the lowest value of . Note that this combinatorial algorithm has the advantage to be adaptable to more general settings in which  particular values are authorized for the components of , for any fixed not necessarily equal to 3. In that case, the complexity is larger, but limited to
particular values are authorized for the components of , for any fixed not necessarily equal to 3. In that case, the complexity is larger, but limited to
 .
.
There are slightly more general settings in which our algorithm remains optimal, in particular when we can certify  ,
,
 . Here,
. Here,  denotes the sum of weights of the examples belonging at least to class
denotes the sum of weights of the examples belonging at least to class  , and
, and  denotes the sum of weights of the examples belonging at least to class , and not belonging at least to class
denotes the sum of weights of the examples belonging at least to class , and not belonging at least to class  . This shows that even for some particular multilabel cases, our approximation algorithm can remain optimal. One can wonder if the optimality is preserved in the unrestricted multilabel framework. We now show that, if optimality is not preserved, we can still prove the quality of our algorithm for general multilabel cases, showing asymptotic optimality as increases.
. This shows that even for some particular multilabel cases, our approximation algorithm can remain optimal. One can wonder if the optimality is preserved in the unrestricted multilabel framework. We now show that, if optimality is not preserved, we can still prove the quality of our algorithm for general multilabel cases, showing asymptotic optimality as increases.
Our approximation algorithm is run in the multilabel case by transforming the examples as follows: each example  for which
for which
 is transformed into
is transformed into 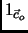 examples, having the same description
examples, having the same description 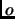 , and only one ``1'' in their vector, in such a way that we span the
``1'' of the original example. Their weight is the one of the original example, divided by . We then run our algorithm on this new set of examples satisfying assumption ().
, and only one ``1'' in their vector, in such a way that we span the
``1'' of the original example. Their weight is the one of the original example, divided by . We then run our algorithm on this new set of examples satisfying assumption ().
Now, suppose that for any example , we have
 for some
for some 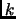 . There are two interesting vectors we use. The first one is
. There are two interesting vectors we use. The first one is  , the optimal vector (or an optimal vector) minimizing over the original set of examples, the second one is , the vector we find minimizing over the transformed set of examples. What we want is to estimate the quality of with respect to the optimal value of over the original set of examples,
, the optimal vector (or an optimal vector) minimizing over the original set of examples, the second one is , the vector we find minimizing over the transformed set of examples. What we want is to estimate the quality of with respect to the optimal value of over the original set of examples,  using our notation. The following theorem gives an answer to this problem, by quantifying its convergence towards .
using our notation. The following theorem gives an answer to this problem, by quantifying its convergence towards .
Proof: See the Appendix.
Therefore, in the set of all problems for which for some  ,
,  , we obtain
, we obtain
 , and our bound converges to the optimum as increases in this class of problems. By means of words, our simple approximation algorithm is quite efficient for problems with large number of classes. Note that using a slightly more involved proof, we could have reduced the constant ``
, and our bound converges to the optimum as increases in this class of problems. By means of words, our simple approximation algorithm is quite efficient for problems with large number of classes. Note that using a slightly more involved proof, we could have reduced the constant `` '' factor in Theorem 6 to the slightly smaller ``
'' factor in Theorem 6 to the slightly smaller `` ''. Now, to fix the ideas, the following subsection displays the explicit (and simple) solution when there are only two classes.
''. Now, to fix the ideas, the following subsection displays the explicit (and simple) solution when there are only two classes.
Next: Explicit Solution in the
Up: Calculating Rule Vectors using
Previous: Optimizing in the Setting
©2002 AI Access Foundation and Morgan Kaufmann Publishers. All rights reserved.