 |
Mihai Budiu -- mihaib+@cs.cmu.edu
http://www.cs.cmu.edu/~mihaib/
mai 2001
Primele calculatoare construite erau foarte diferite de cele de astăzi. Nu mă refer aici la dimensiuni şi capacitate (care depind doar de tehnologie), ci la structura lor fundamentală. Acele calculatoare erau construite pentru a rezolva o singură problemă; nu erau universale. Ele constau dintr-o colecţie de unităţi funcţionale, care puteau face calcule simple. ``Programatorii'' aveau sarcina de a conecta unităţile funcţionale între ele cu sîrme, pe care le înfigeau manual în tot felul de mufe. De exemplu, dacă vroiau să calculeze (a+b)2, programatorii luau o unitate care făcea adunări şi una care făcea înmulţiri şi le cuplau ca în figura 1.
|
În anii '40 în domeniul calculatoarelor intră în scenă un genial matematician, pe nume John von Neumann. von Neumann analizează starea de fapt a calculatoarelor şi scrie în 1945 un raport intitulat ``First Draft of a Report on the EDVAC'' (Prima ciornă a unui raport despre EDVAC), în care sugerează o arhitectura revoluţionară. În această arhitectură, programul nu mai este reprezentat de felul în care sunt cuplate unităţile funcţionale, ci este stocat în memorie, fiind descris folosind un limbaj numit cod-maşină. În cod-maşină, operaţiile de executat sunt codificate sub forma unor numere numite instrucţiuni. Programul de executat este descris printr-un şir de instrucţiuni, care se execută consecutiv.
Pe lîngă unităţile funcţionale care fac operaţii aritmetice, calculatorul mai are o unitate de control, care citeşte instrucţiunile programului şi care trimite semnale între unităţile funcţionale pentru a executa aceste instrucţiuni. Rezultatele intermediare sunt stocate în memorie. Această arhitectură se numeşte ``von Neumann''. Dacă nu sunteţi impresionaţi de această viziune radicală, este pentru că marea majoritate a calculatoarelor din ziua de azi sunt bazate pe această arhitectură; noţiunea de limbaj-maşină, şi cea înrudită, de limbaj de programare, folosite pentru descrierea programelor, sunt concepte foarte naturale pentru toţi cei care manipulează calculatoarele.
Se cuvine menţionat faptul că ideea de a descrie un program folosind un limbaj (şi nu prin conexiuni între unităţi funcţionale) este mai veche; în 1936 Alan Turing folosise noţiunea de ``maşină Turing universală'' pentru a descrie un calculator universal, care poate executa orice program. Programele erau stocate în memoria calculatorului, reprezentate ca şiruri de numere.
Spuneam că marea majoritate a calculatoarelor digitale construite astăzi au o arhitectură von Neumann. Dar nu toate; există încă ``calculatoare'' bazate pe arhitectura veche, în care unităţile funcţionale sunt legate între ele prin sîrme şi nu există un program stocat în memorie.
Modelul von Neumann are o virtute excepţională: flexibilitatea. Folosind acelaşi hardware putem executa oricîte programe, toate diferite între ele. Preţul care trebuie însă plătit este performanţa: unele operaţiuni nu se pot descrie foarte eficient prin instrucţiunile disponibile, şi s-ar putea implementa mult mai bine direct în hardware; figura 2 prezintă un astfel de exemplu extrem.
 |
Ca atare, atunci cînd este nevoie de performanţă deosebită, sau cînd flexibilitatea nu este foarte importantă, inginerii construiesc în continuare calculatoare specializate. De exemplu, ruterele de mare viteză de pe coloana vertebrală a Internetului trebuie să proceseze pachetele cu informaţii la viteze uluitoare (au la dispoziţie doar cîteva zeci de nano-secunde pentru fiecare pachet). Ca atare, unele din funcţiile de clasificare şi manipulare ale pachetului sunt implementate direct în hardware, într-un algoritm fixat. Chiar dacă performanţa nu este critică, atunci cînd algoritmul de procesare este foarte bine standardizat, este adesea mai ieftin de folosit un astfel circuit specializat, numit ASIC (Application-Specific Integrated Circuit). Chiar şi într-un calculator obişnuit se găsesc de obicei multe astfel de circuite pentru manipularea perifericelor: plăci de reţea, controlere de magistrală, etc.
În articolul meu anterior din NetReport am discutat despre o posibilă evoluţie a tehnologiilor electronice, nanotehnologiile, care ne vor permite să construim circuite digitale cu miliarde de porţi logice. În acel articol am sugerat că aceste circuite imense vor putea fi folosite cel mai eficient sub formă de hardware reconfigurabil. Hardwareul reconfigurabil este un model de calcul foarte asemănător cu cel de acum cincizeci de ani: constă dintr-o ``mare'' de porţi logice universale, care pot fi programate individual pentru a implementa orice funcţie logică, şi două reţele: una care leagă porţile între ele, şi care poate fi configurată în felurite moduri pentru a lega şi dezlega porţile, şi una de configuraţie, care este folosită pentru a transporta informaţiile de configurare spre porţi şi spre cealaltă reţea.
Folosind hardware reconfigurabil putem sintetiza circuite specifice fiecărei aplicaţii; de data asta, însă, în loc de a conecta unităţile funcţionale manual, le cuplăm în mod electronic, schimbînd felul în care sunt cuplate porţile logice.
În articolul de faţă voi arăta discuta mai pe larg cum se poate transforma un program într-un circuit şi ce fel de proprietăţi are acest nou model de execuţie.
Ideea de a descrie hardware folosind programe nu este de loc nouă; de fapt circuitele integrate digitale sunt construite chiar în acest fel: circuitul de construit este descris într-un limbaj special de programare, numit Hardware Description Language. Circuitul astfel descris este apoi prelucrat de o suită complicată de programe CAD (Computer-Aided Design), care optimizează circuitul, îl transformă în operaţii elementare, le plasează pe o suprafaţă plană şi le conectează prin sîrme. În faza de proiectare, circuitul descris într-un HDL poate fi simulat, pentru testare şi depanare.
La ora actuală există două limbaje foarte importante de descriere a hardware-ului, care au fiecare susţinătorii lor aprigi; unul dintre ele se numeşte VHDL iar celălalt Verilog. VHDL este prescurtarea a două prescurtări: Vhsic HDL, unde VHSIC înseamnă ``Very High Speed Integrated Circuits''. Verilog vine de la ``VERifying LOGic'', dar limbajul este folosit nu numai pentru a simula şi verifica circuite logice (cum a fost conceput iniţial, şi după cum arată numele său), ci şi pentru a le proiecta şi implementa (sinteza de hardware; hardware synthesis).
Cele două limbaje sunt relativ similare ca putere de expresie, dar incompatibile între ele. Sunt de asemenea destul de diferite de celelalte limbaje obişnuite de programare: în limbajele HDL programatorul exprimă un circuit ca o colecţie de sub-circuite care operează în paralel (paralelismul este explicit în program). Variabilele sunt semnale electrice, iar operaţiile descriu unităţi funcţionale. Nu există funcţii recursive, structuri de date complicate sau manipulare dinamică a memoriei (malloc/new/free).
Verilog şi VHDL sunt foarte potrivite pentru a descrie circuite, însă sunt puţin potrivite pentru felul în care gîndesc oamenii. În general, oamenii au probleme în a-şi imagina mai multe procese care se petrec concurent şi comunică între ele; din cauza asta calculatoarele paralele nu au avut prea mult succes, şi tot din cauza asta programarea aplicaţiilor cu mai multe fire de execuţie (threads) este un exerciţiu de disciplină şi nervi de fier.
Ca atare, de multă vreme unele grupuri de cercetare încearcă să folosească limbaje mai simple şi mai naturale (de genul Pascal/C) pentru a descrie hardware. (Dacă limbajele acestea nu vi se par naturale, înseamnă că nu aţi încercat să descrieţi un sistem complex în Verilog!).
Tentativa de a genera hardware din limbaje obişnuite de programare se loveşte de mai multe obstacole. În primul rînd, tehnologia pentru extragerea paralelismului dintr-un program scris într-un limbaj ``secvenţial'' (ca C sau Fortran) este nesatisfăcătoare; ori paralelismul este principalul avantaj al unui model de execuţie în hardware.
În al doilea rînd, limbajele de genul C sau Fortran folosesc tot felul de construcţii care nu au un corespondent direct în hardware, cum ar fi funcţii recursive, memorie alocată dinamic, sau structuri de date complicate. În ce fel se pot traduce acestea în hardware într-un mod eficient este un subiect activ de cercetare.
În cele ce urmează voi ilustra cum se pot traduce în hardware operaţiile fundamentale ale unui limbaj de programare.
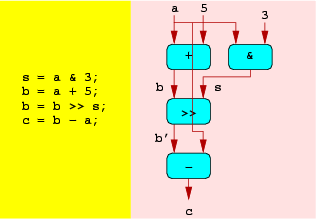
Pentru a traduce o operaţiune simplă în hardware, asociem variabilele cu ``sîrmele'', şi operaţiile cu unităţi funcţionale, după cum am anticipat şi mai devreme. Figura 1 ilustrează o astfel de transformare.
În limbajele de nivel înalt valorile sunt stocate în variabile; în codul maşină ele sunt atribuite unor regiştri, sau sunt stocate în memorie. Cînd avem de-a face cu un bloc de instrucţiuni consecutive care manipulează doar regiştri, le putem traduce în hardware transformînd fiecare registru într-o sîrmă, ca în figura 3.
 |
În limbajele de nivel înalt avem construcţii care selectează între diferite instrucţiuni care urmează să se execute, cum ar fi if-then-else. Pentru a le traduce pe acestea în hardware avem mai multe alternative. În figura 4 ilustrăm o posibilitate care exploatează la maximum paralelismul dintre instrucţiuni, executînd simultan părţile then şi else, şi selectînd doar rezultatele necesare.
 |
Acest gen de execuţie se numeşte speculativă, pentru că execută mai mult decît este strict necesar şi selectează numai ceea ce e necesar la sfîrşit. Şi microprocesoarele moderne folosesc o formă de execuţie speculativă, pe care am descris-o mai demult într-un articol din PC Report despre predicţia salturilor.
Una dintre cele mai puternice trăsături ale limbajelor de nivel înalt este capacitatea de a manipula matrici, care se bazează pe posibilitatea de a adresa memoria în mod indirect. Cu alte cuvinte, citim conţinutul unei celule de memorie a cărei adresă a fost calculată.
Accesele indirecte nu pot fi transformate pur şi simplu în sîrme; trebuie să folosim memorii hardware pentru a stoca matrici. În plus, atunci cînd avem cod executat în mod speculativ, trebuie să fim atenţi să nu executăm decît accesele la memorie corecte, pentru că altfel vom ``strica'' conţinutul memoriei.
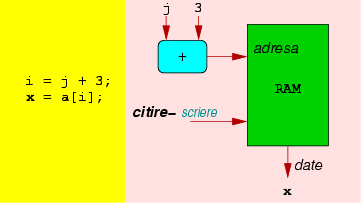 |
Figura 5 ilustrează implementarea unei bucăţi de cod care conţine accese la memorie.
Lucrurile devin mai interesante atunci cînd avem de executat bucle. Circuitul pe care-l implementăm nu mai este un simplu circuit combinatorial, în care semnalul se propagă într-un singur sens. El devine un circuit secvenţial, cu o buclă de feed-back. Bucla de feed-back trebuie să fie întreruptă de un registru controlat de un ceas, care sincronizează propagarea tuturor semnalelor din buclă.
 |
Figura 6 ilustrează o posibilă implementare a unei bucăţi de cod care conţine o buclă.
Cînd avem un program compus din mai multe proceduri, fiecare procedură poate fi implementată ca un circuit separat. Procedura curentă, în curs de execuţie, corespunde circuitului activ. Controlul este transmis între proceduri prin semnale care activează procedura chemată.
O problemă ceva mai complicată este că atunci cînd procedura chemată se termină, trebuie să sară la o bucată de cod diferită de fiecare dată (la chemătorul ei). Acest lucru poate fi realizat în mai multe feluri; de exemplu, fiecare procedură primeşte un parametru suplimentar, care este chemătorul său; pentru terminarea procedurii, se poate sintetiza o bucată de hardware care selectează dintre toţi chemătorii posibili bazat pe valoarea acestui parametru şi-i trimite un mesaj cînd procedura curentă şi-a terminat execuţia.
Această implementare nu funcţionează pentru procedurile recursive, care mai au nevoie şi de o stivă; deocamdată nu avem la-ndemînă o soluţie eficientă pentru a trata astfel de cazuri.
Pentru a estima impactul unui asemenea model de calcul asupra performanţei am făcut un studiu preliminar, care face o mulţime de asumpţii simplificatoare. Sperăm că modelul real de calcul nu va da rezultate substanţial diferite de idealizarea noastră.
Cel mai ``idealizat'' aspect al analizei noastre constă în cantitatea de informaţie pe care am folosit-o despre program şi zonele de memorie pe care le foloseşte: am presupus că ştim exact ce adrese de memorie vor fi accesate de fiecare instrucţiune de citire şi scriere din memorie. Această informaţie a fost colectată executînd programul modificat pentru a colecta informaţii despre propria sa comportare (un astfel de program se numeşte instrumentat).
Figura 7 arată un astfel de program desfăşurat şi aşezat în plan.
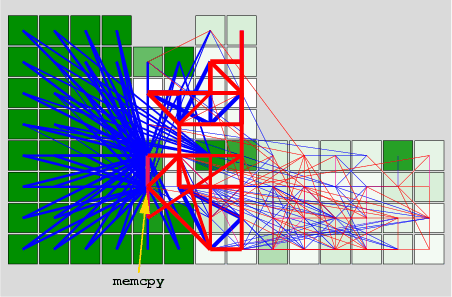 |
Fiecare program este reprezentat sub forma unui graf, în care nodurile sunt instrucţiuni sau memorii şi în care muchiile sunt transfer de execuţie între instrucţiuni sau accese la memorie. Toate programele pe care le-am analizat1 au trăsături foarte similare:
Analizînd graful din figură am descoperit că una dintre cele două stele este în corpul funcţiei memcpy. Dacă ne gîndim puţin, vom realiza că acest lucru este foarte natural: toate structurile de date ale programului care sunt copiate vor fi atinse de această funcţie.
Dacă am luat un program şi l-am ``întins'' pe o suprafaţă, întrebarea următoare este: ``cît de repede merge''? Pentru a putea răspunde, trebuie să precizăm alte cîteva lucruri despre modelul nostru computaţional:
Pornind de la acest model am evaluat performanţa programelor. Rezultatele au fost amestecate. Am căutat apoi metode de a îmbunătăţi performanţa prin transformări simple.
Primul obiectiv asupra căruia ne-am îndreptat atenţia au fost ``stelele''; acestea sunt detrimentale performanţei, pentru că, avînd mulţi vecini, unii dintre aceştia vor fi în mod necesar plasaţi la distanţă mare de centru, deci vor fi accesaţi foarte greu.
Ne-am întrebat: nu am putea cumva să ``spargem'' o stea în bucăţi, în aşa fel încît să facem două stele mai mici? Răspunsul este: da, şi chiar foarte simplu. Tot ce trebuie făcut pentru programul din figură este să duplicăm codul funcţiei memcpy şi să aranjăm ca din locuri diferite să fie chemate copii diferite. O tehnică foarte simplă pentru a realiza acest lucru se numeşte în compilatoare ``inlining'', în care funcţia chemată este inserată textual în codul chemătorului.
După ce am aplicat această transformare, am obţinut graful din figura 8.
 |
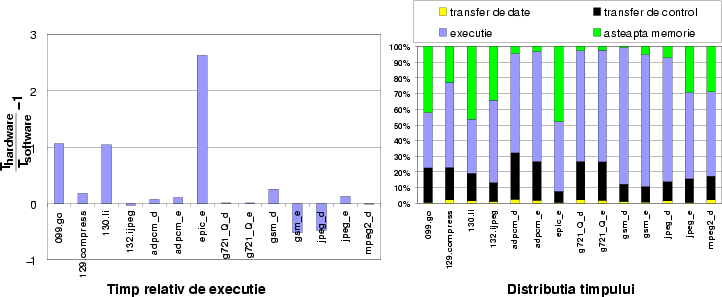
Rezultatele au fost destul de interesante. Am comparat performanţa acestor programe cu execuţia lor pe un microprocesor Alpha 21164 la 500 Mhz. Am presupus că în implementarea spaţială vom putea executa o operaţie pe ciclu de ceas şi că vom putea folosi aceeaşi frecvenţă de ceas cu Alpha.
În medie programele noastre funcţionează ceva mai puţin de 2 ori mai încet decît pe Alpha, dar unele dintre ele merg mai rapid, după cum se vede în figura 9, în stînga. Graficul din dreapta arată cum îşi petrece timpul fiecare din programe.
 |
Acest text ilustrează cercetările noastre preliminare în domeniul modelului spaţial de execuţie; foarte multe lucruri mai rămîn de făcut. Rezultatele noastre sunt însă încurajatoare: avem o metodologie care ne permite să compilăm programe destul de complicate iar performanţa nu este substanţial degradată faţă de modelele de calcul convenţionale.
Va trebui însă să dezvoltăm o grămadă de tehnici noi, plecînd de la construcţia hardware-ului reconfigurabil însuşi, trecînd prin metode de compilare şi scule de simulare mai sofisticate, care iau în considerare mai multe detalii despre arhitectura reală a unui astfel de sistem.
Articole ale mele anterioare din PC Report: