 |
Perplexity is a measure of average branching factor and can be used to measure how well an n-gram predicts the next juncture type in the test set. If N is the order of the n-gram and Q is the number of junctures in the test set, the perplexity B can be calculated from the entropy H by:
| B = 2H | (8) |
where
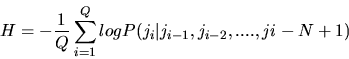 |
(9) |
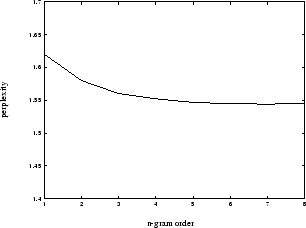
N-grams can be estimated from simple frequency counts of the data. Figure 4 shows how perplexity of a phrase break model of juncture types break and non-break varies as a function of n-gram order. The differences between the various phrase-break models are not large, but it can be seen that the 6-gram has a perplexity of 1.54 compared to the unigram case of about 1.62. It is common in language modelling to use smoothing to account for rare and unseen cases. We recalculated our phrase-break model parameters using 3 types of smoothing: a fixed floor for unseen cases; Good-Turing smoothing, which alters the probabilities of rarely seen cases as well as unseen cases; and back-off smoothing whereby the values for rare n-grams are computed from the n-1-grams equivalents. None of the types of smoothing had a significant effect on the perplexity or indeed the overall results. In practice we use the simplest type of smoothing where unseen n-grams are given a frequency count of 1 during training.
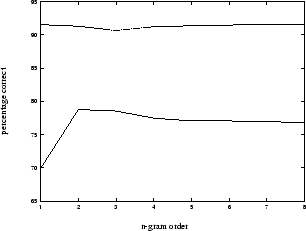
Figure 5 and table 5 show how the order of the n-gram affects overall performance. The most noticeable effect is the big increase in performance between the unigram phrase-break model and the rest, which are fairly similar. This result is due to the phrase-break model assigning a very low probability (0.03) for a break given a preceding break compared with a probability of 0.2 for the same sequence from the unigram. The higher order n-grams perform slightly better than the bigram in terms of junctures-correct and juncture-insertions. In table 5 the 7-gram performs the best. In most of our experiments n-grams of order 6 and 7 had consistently better results than the other n-grams, but the difference was often slight. Figure 4 also shows that the perplexity of n-grams of about this order is slightly lower than for the others.