Before we can start thinking about algorithms for learning to behave optimally, we have to decide what our model of optimality will be. In particular, we have to specify how the agent should take the future into account in the decisions it makes about how to behave now. There are three models that have been the subject of the majority of work in this area.
The finite-horizon model is the easiest to think about; at a given moment in time, the agent should optimize its expected reward for the next h steps:
![]()
it need not worry about what will happen after that. In this and
subsequent expressions, ![]() represents the scalar reward received
t steps into the future. This model can be used in two ways. In
the first, the agent will have a non-stationary policy; that is, one
that changes over time. On its first step it will take what is termed
a h-step optimal action. This is defined to be the best action
available given that it has h steps remaining in which to act and
gain reinforcement. On the next step it will take a (h-1)-step
optimal action, and so on, until it finally takes a 1-step optimal
action and terminates. In the second, the agent does
receding-horizon control, in which it always takes the h-step
optimal action. The agent always acts according to the same policy,
but the value of h limits how far ahead it looks in choosing its
actions. The finite-horizon model is not always appropriate. In many
cases we may not know the precise length of the agent's life in
advance.
represents the scalar reward received
t steps into the future. This model can be used in two ways. In
the first, the agent will have a non-stationary policy; that is, one
that changes over time. On its first step it will take what is termed
a h-step optimal action. This is defined to be the best action
available given that it has h steps remaining in which to act and
gain reinforcement. On the next step it will take a (h-1)-step
optimal action, and so on, until it finally takes a 1-step optimal
action and terminates. In the second, the agent does
receding-horizon control, in which it always takes the h-step
optimal action. The agent always acts according to the same policy,
but the value of h limits how far ahead it looks in choosing its
actions. The finite-horizon model is not always appropriate. In many
cases we may not know the precise length of the agent's life in
advance.
The infinite-horizon discounted model takes the long-run reward of the
agent into account, but rewards that are received in the future are
geometrically discounted according to discount factor ![]() , (where
, (where
![]() ):
):
![]()
We can interpret ![]() in several ways. It can be seen as an
interest rate, a probability of living another step, or as a
mathematical trick to bound the infinite sum. The model is
conceptually similar to receding-horizon control, but the discounted
model is more mathematically tractable than the finite-horizon model.
This is a dominant reason for the wide attention this model has
received.
in several ways. It can be seen as an
interest rate, a probability of living another step, or as a
mathematical trick to bound the infinite sum. The model is
conceptually similar to receding-horizon control, but the discounted
model is more mathematically tractable than the finite-horizon model.
This is a dominant reason for the wide attention this model has
received.
Another optimality criterion is the average-reward model, in which the agent is supposed to take actions that optimize its long-run average reward:
![]()
Such a policy is referred to as a gain optimal policy; it can be seen as the limiting case of the infinite-horizon discounted model as the discount factor approaches 1 [14]. One problem with this criterion is that there is no way to distinguish between two policies, one of which gains a large amount of reward in the initial phases and the other of which does not. Reward gained on any initial prefix of the agent's life is overshadowed by the long-run average performance. It is possible to generalize this model so that it takes into account both the long run average and the amount of initial reward than can be gained. In the generalized, bias optimal model, a policy is preferred if it maximizes the long-run average and ties are broken by the initial extra reward.
Figure 2 contrasts these models of optimality by
providing an environment in which changing the model of optimality
changes the optimal policy. In this example, circles represent the
states of the environment and arrows are state transitions. There is
only a single action choice from every state except the start state,
which is in the upper left and marked with an incoming arrow. All
rewards are zero except where marked. Under a finite-horizon model
with h=5, the three actions yield rewards of +6.0, +0.0, and
+0.0, so the first action should be chosen; under an
infinite-horizon discounted model with ![]() , the three choices
yield +16.2, +59.0, and +58.5 so the second action should be
chosen; and under the average reward model, the third action should be
chosen since it leads to an average reward of +11. If we change h
to 1000 and
, the three choices
yield +16.2, +59.0, and +58.5 so the second action should be
chosen; and under the average reward model, the third action should be
chosen since it leads to an average reward of +11. If we change h
to 1000 and ![]() to 0.2, then the second action is optimal for the
finite-horizon model and the first for the infinite-horizon discounted
model; however, the average reward model will always prefer the best
long-term average. Since the choice of optimality model and
parameters matters so much, it is important to choose it carefully in
any application.
to 0.2, then the second action is optimal for the
finite-horizon model and the first for the infinite-horizon discounted
model; however, the average reward model will always prefer the best
long-term average. Since the choice of optimality model and
parameters matters so much, it is important to choose it carefully in
any application.
The finite-horizon model is appropriate when the agent's lifetime is known; one important aspect of this model is that as the length of the remaining lifetime decreases, the agent's policy may change. A system with a hard deadline would be appropriately modeled this way. The relative usefulness of infinite-horizon discounted and bias-optimal models is still under debate. Bias-optimality has the advantage of not requiring a discount parameter; however, algorithms for finding bias-optimal policies are not yet as well-understood as those for finding optimal infinite-horizon discounted policies.
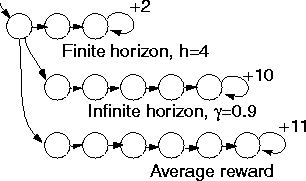
Figure 2: Comparing models of optimality. All unlabeled arrows produce
a reward of zero.