In the standard reinforcement-learning model, an agent is connected to its environment via perception and action, as depicted in Figure 1. On each step of interaction the agent receives as input, i, some indication of the current state, s, of the environment; the agent then chooses an action, a, to generate as output. The action changes the state of the environment, and the value of this state transition is communicated to the agent through a scalar reinforcement signal, r. The agent's behavior, B, should choose actions that tend to increase the long-run sum of values of the reinforcement signal. It can learn to do this over time by systematic trial and error, guided by a wide variety of algorithms that are the subject of later sections of this paper.
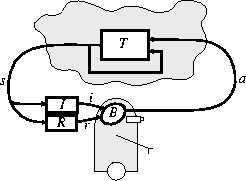
Figure 1: The standard reinforcement-learning model.
Formally, the model consists of
An intuitive way to understand the relation between the agent and its environment is with the following example dialogue.
| Environment: | You are in state 65. You have 4 possible actions. |
| Agent: | I'll take action 2. |
| Environment: | You received a reinforcement of 7 units. You are now in state 15. You have 2 possible actions. |
| Agent: | I'll take action 1. |
| Environment: | You received a reinforcement of -4 units. You are now in state 65. You have 4 possible actions. |
| Agent: | I'll take action 2. |
| Environment: | You received a reinforcement of 5 units. You are now in state 44. You have 5 possible actions. |
|
| |
The agent's job is to find a policy ![]() , mapping states to actions,
that maximizes some long-run measure of reinforcement. We expect, in
general, that the environment will be non-deterministic; that is, that
taking the same action in the same state on two different occasions
may result in different next states and/or different reinforcement
values. This happens in our example above: from state 65, applying
action 2 produces differing reinforcements and differing states on two
occasions. However, we assume the environment is stationary; that is,
that the probabilities of making state transitions or receiving
specific reinforcement signals do not change over time.
, mapping states to actions,
that maximizes some long-run measure of reinforcement. We expect, in
general, that the environment will be non-deterministic; that is, that
taking the same action in the same state on two different occasions
may result in different next states and/or different reinforcement
values. This happens in our example above: from state 65, applying
action 2 produces differing reinforcements and differing states on two
occasions. However, we assume the environment is stationary; that is,
that the probabilities of making state transitions or receiving
specific reinforcement signals do not change over time.
Reinforcement learning differs from the more widely studied problem of supervised learning in several ways. The most important difference is that there is no presentation of input/output pairs. Instead, after choosing an action the agent is told the immediate reward and the subsequent state, but is not told which action would have been in its best long-term interests. It is necessary for the agent to gather useful experience about the possible system states, actions, transitions and rewards actively to act optimally. Another difference from supervised learning is that on-line performance is important: the evaluation of the system is often concurrent with learning.
Some aspects of reinforcement learning are closely related to search and planning issues in artificial intelligence. AI search algorithms generate a satisfactory trajectory through a graph of states. Planning operates in a similar manner, but typically within a construct with more complexity than a graph, in which states are represented by compositions of logical expressions instead of atomic symbols. These AI algorithms are less general than the reinforcement-learning methods, in that they require a predefined model of state transitions, and with a few exceptions assume determinism. On the other hand, reinforcement learning, at least in the kind of discrete cases for which theory has been developed, assumes that the entire state space can be enumerated and stored in memory--an assumption to which conventional search algorithms are not tied.