![\includegraphics[height=1.4in]{figs/manifold_plus.eps}](img29.png) |
Ideally, dimensionality reduction involves no information loss--all aspects of the data can be recovered equally well from the low-dimensional representation as from the high-dimensional one. In practice, though, we will see that we can use lossy representations of the belief (that is, representations that may not allow the original data or beliefs to be recovered without error) and still get good control. But, we will also see that finding such representations of probability distributions will require a careful trade-off between preserving important aspects of the distributions and using as few dimensions as possible. We can measure the quality of our representation by penalizing reconstruction errors with a loss function [CDS02]. The loss function provides a quantitative way to measure errors in representing the data, and different loss functions will result in different low-dimensional representations.
One of the most common forms of dimensionality reduction is Principal Components Analysis [Jol86]. Given a set of data, PCA finds the linear lower-dimensional representation of the data such that the variance of the reconstructed data is preserved. Intuitively, PCA finds a low-dimensional hyperplane such that, when we project our data onto the hyperplane, the variance of our data is changed as little as possible. A transformation that preserves variance seems appealing because it will maximally preserve our ability to distinguish between beliefs that are far apart in Euclidean norm. As we will see below, however, Euclidean norm is not the most appropriate way to measure distance between beliefs when our goal is to preserve the ability to choose good actions.
We first assume we have a data set of ![]() beliefs
beliefs
![]() , where each belief
, where each belief ![]() is in
is in
![]() , the
high-dimensional belief space. We write these beliefs as column
vectors in a matrix
, the
high-dimensional belief space. We write these beliefs as column
vectors in a matrix
![]() , where
, where
![]() . We use PCA to compute a low-dimensional
representation of the beliefs by factoring
. We use PCA to compute a low-dimensional
representation of the beliefs by factoring ![]() into the matrices
into the matrices ![]() and
and ![]() ,
,
Figure 7 shows a toy problem that we can use to evaluate
the success of PCA at finding low-dimensional representations. The
abstract model has a two-dimensional state space: one dimension of
position along one of two circular corridors, and one binary variable
that determines which corridor we are in. States
![]() inclusive correspond to one corridor, and states
inclusive correspond to one corridor, and states
![]() correspond to the other. The reward is at a known
position that is different in each corridor; therefore, the agent
needs to discover its corridor, move to the appropriate position, and
declare it has arrived at the goal. When the goal is declared the
system resets (regardless of whether the agent is actually at the
goal). The agent has 4 actions:
correspond to the other. The reward is at a known
position that is different in each corridor; therefore, the agent
needs to discover its corridor, move to the appropriate position, and
declare it has arrived at the goal. When the goal is declared the
system resets (regardless of whether the agent is actually at the
goal). The agent has 4 actions: left, right,
sense_corridor, and declare_goal. The observation and
transition probabilities are given by discretized von Mises distributions
[MJ00,SK02], an exponential family distribution defined over
![]() . The von Mises distribution is a ``wrapped'' analog of a
Gaussian; it accounts for the fact that the two ends of the corridor
are connected. Because the sum of two von Mises variates is another
von Mises variate, and because the product of two von Mises
likelihoods is a scaled von Mises likelihood, we can guarantee that
the true belief distribution is always a von Mises distribution over
each corridor after each action and observation.
. The von Mises distribution is a ``wrapped'' analog of a
Gaussian; it accounts for the fact that the two ends of the corridor
are connected. Because the sum of two von Mises variates is another
von Mises variate, and because the product of two von Mises
likelihoods is a scaled von Mises likelihood, we can guarantee that
the true belief distribution is always a von Mises distribution over
each corridor after each action and observation.
This instance of the problem consists of 200 states, with 4 actions and 102 observations. Actions 1 and 2 move the controller left and right (with some von Mises noise) and action 3 returns an observation that uniquely and correctly identifies which half of the maze the agent is in (the top half or the bottom half). Observations returned after actions 1 and 2 identify the current state modulo 100: the probability of each observation is a von Mises distribution with mean equal to the true state (modulo 100). That is, these observations indicate approximately where the agent is horizontally.
This maze is interesting because it is relatively large by POMDP standards (200 states) and contains a particular kind of uncertainty--the agent must use action 3 at some point to uniquely identify which half of the maze it is in; the remaining actions result in observations that contain no information about which corridor the agent is in. This problem is too large to be solved by conventional POMDP value iteration, but structured such that heuristic policies will also perform poorly.
![\includegraphics[width=\picheight]{figs/sample1.ps}](img55.png)
![\includegraphics[width=\picheight]{figs/sample2.ps}](img56.png)
![\includegraphics[width=\picheight]{figs/sample3.ps}](img57.png)
![\includegraphics[width=\picheight]{figs/sample6.ps}](img58.png)
|
We collected a data set of 500 beliefs and assessed the performance of
PCA on beliefs from this problem. The data were collected using a
hand-coded controller, alternating at random between exploration
actions and the MDP solution, taking as the current state the
maximum-likelihood state of the belief. Figure 8
shows ![]() sample beliefs from this data set. Notice that each of these
beliefs is essentially two discretized von Mises distributions with
different weights, one for each half of the maze. The starting belief
state is the left-most distribution in Figure 8:
equal probability on the top and bottom corridors, and position along
the corridor following a discretized von Mises distribution with
concentration parameter 1.0 (meaning that
sample beliefs from this data set. Notice that each of these
beliefs is essentially two discretized von Mises distributions with
different weights, one for each half of the maze. The starting belief
state is the left-most distribution in Figure 8:
equal probability on the top and bottom corridors, and position along
the corridor following a discretized von Mises distribution with
concentration parameter 1.0 (meaning that
![]() state
state![]() falls to
falls to
![]() of its maximum value when we move
of its maximum value when we move ![]() of the way around the
corridor from the most likely state).
of the way around the
corridor from the most likely state).
Figure 9 examines the performance of PCA on
representing the beliefs in this data set by computing the average error
between the original beliefs ![]() and their reconstructions
and their reconstructions
![]() .3 In Figure 9(a) we see the
average squared error (squared
.3 In Figure 9(a) we see the
average squared error (squared ![]() ) compared to the number of bases, and in
Figure 9(b), we see the average Kullbach-Leibler (KL)
divergence. The KL divergence between a belief
) compared to the number of bases, and in
Figure 9(b), we see the average Kullbach-Leibler (KL)
divergence. The KL divergence between a belief ![]() and its reconstruction
and its reconstruction
![]() from the low-dimensional representation
from the low-dimensional representation ![]() is given by
is given by
![\includegraphics[width=3in]{figs/toy-l2.ps}](img69.png)
[Average Squared L-2 Error] |
![\includegraphics[width=3in]{figs/toy-kl.ps}](img70.png)
[Average KL Divergence] |
Unfortunately, PCA performs poorly at representing probability distributions. Despite the fact that probability distributions in the collected data set have only 3 degrees of freedom, the reconstruction error remains relatively high until somewhere between 10 and 15 basis functions. If we examine the reconstruction of a sample belief, we can see the kinds of errors that PCA is making. Figure 10 shows a sample belief (the solid line) and its reconstruction (the dotted line). Notice that the reconstructed belief has some strange artifacts: it contains ringing (multiple small modes), and also is negative in some regions. PCA is a purely geometric process; it has no notion of the original data as probability distributions, and is therefore free to generate reconstructions of the data that contain negative numbers or do not sum to 1.
Notice also that the PCA process is making its most significant errors in the low-probability regions of the belief. This is particularly unfortunate because real-world probability distributions tend to be characterized by compact masses of probability, surrounded by large regions of zero probability (e.g., Figure 4a). What we therefore need to do is modify PCA to ensure the reconstructions are probability distributions, and improve the representation of sparse probability distributions by reducing the errors made on low-probability events.
The question to be answered is what loss functions are available instead of the sum of squared errors, as in equation (2). We would like a loss function that better reflects the need to represent probability distributions.
![\includegraphics[height=1.25in]{figs/toy_problem.eps}](img54.png)
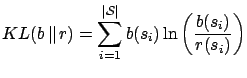
![\includegraphics[width=3in]{figs/toy-example.no-norm.ps}](img71.png)