 Slide 1: Reconfigurable Computing Intro
Slide 1: Reconfigurable Computing Intro
 Slide 2: Admin
Slide 2: Admin
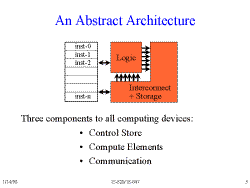 Slide 3: An Abstract Architecture
Slide 3: An Abstract Architecture
 Slide 4: Hardware
Slide 4: Hardware
This slide represents one end of the spectrum of computing devices.
Note that the lack of a control store means that custom hardware is not
general-purpose. All computing is done in the connections or 'space',
and not in 'time'. (The exception to this is state machines.)
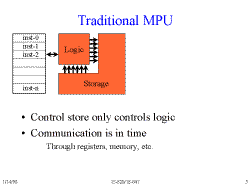 Slide 5: Traditional MPU
Slide 5: Traditional MPU
The other end of the spectrum: general-purpose processors which perform
computation in time, using regfiles or memory to maintain connections
between operations.
 Slide 6: Variations on MPU
Slide 6: Variations on MPU
 Slide 7: Reconfigurable Computing
Slide 7: Reconfigurable Computing
The primary difference between this picture and the previous one is that
in reconfigurable computing, the control store affects compute
and communicate. In other words, computation occurs in both time
and space. In slide 6, note that the
control store only affected the compute portion.
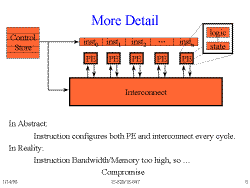 Slide 8: More Detail
Slide 8: More Detail
The PE's listed here are an abstraction; they include processing logic
as well as any state (e.g. a register) that might exist. What we would
like is for each instruction word to reconfigure both the PE and the
interconnect; however, these instruction words become unweildy very
quickly. Since we don't have the bandwidth or the wires, we have to
make compromises.
 Slide 9: RC Compromises
Slide 9: RC Compromises
When we discuss 'reducing frequency' (bullet #2), note that most
reconfigurable devices only load once because the load time is so high.
'Granularity' (bullet #4) refers to fine- or coarse-grained devices;
fine-grained devices (like the CAL chip) have small PEs of few inputs,
and coarse-grained devices have larger PEs with many inputs.
 Slide 10: The CAL Chip
Slide 10: The CAL ChipWhat global lines exist in this reconfigurable device?
Giving the PEs the choice of operating as a latch saves the designer
from using multiple PEs to build a latch out of gates. This also helps
reduce latch timing problems, such as metastability.
 Slide 11: The CAL Function Block
Slide 11: The CAL Function Block
The rightmost multiplexor allows the CAL functional block to act as a
latch, using input X1 as a clock.
 Slide 12: CAL Architecture
Slide 12: CAL Architecture
Partial reconfiguration is possible in this architecture because of the
direct connections. We are able to ensure that the portion of the
fabric that is executing right now can be isolated from the portion that
is being reconfigured.
 Slide 13: Rent's Rule
Slide 13: Rent's Rule
Rent's Rule is all about locality. It shows that most of the wires in a
reconfigurable device are close together (i.e. inside the PE), with few
wires that connect blocks to one another (and also to the outside
world). In the CAL chip, p is around 0.5. This can be a problem if you
try and partition large algorithms over multiple chips, since you have
very little interconnection between chips. As mentioned in the Gray and
Kean paper, they used a 3x3 grid of chips for DES incryption, while the
gas particle simulation took 104 chips. Modern processors have a p
value of around 0.7. Rent's Rule also helps to describe some measure of
efficency in a chip: how much of the fabric is actually usable before
routing becomes a problem? More routing resources can make more of the
fabric usable, but take up more room between PEs.
 Slide 14: RC Design Space
Slide 14: RC Design SpaceLogic Block Architecture (bullet #2) really means PE architecture. Choices today include LUTs (LookUp Tables), MUXes (like the CAL chip), MPUs, or universal block. Universal block architecture is a collection of gates in each PE which can be connected to produce some desired logic function.
An "n:1 LUT" refers to a lookup table with n inputs, 1 output, and a 2^n bit RAM that is addressed by the inputs. The primary advantage to a LUT is that any signal can be directed to any input of your LUT, so long as the RAM values are programmed correctly. This allows more flexability in defining your function, even if some LUT inputs are limited to certain signals in the fabric. This sort of input switching can't be done with universal blocks.
Programmability (bullet #4) refers to how often and how quickly
programming can be accomplished. In the CAL chip, all connections are
local; thus, it is possible to section off a part of the chip and
reconfigure it while other parts of the same chip are still operating.
By contrast, most Xilinx chips (e.g. the 4000 series) must be shut down
to be reconfigured, and the entire fabric must be reconfigured at once.
 Slide 15: Interconnect
Slide 15: Interconnect(Bullet #1) The CAL chip uses direct-connect interconnect. Xilinx and Altera parts use wire-channels. Wire-channel routing consists of channels of wires that run between each PE and cross at corners. At these corners is a block of programmable switches that control which horizontal wires connect to which vertical wires. There are many different way of laying out these switches that provide as much functionality as desired.
(Bullet #5) The routing delay can either be
variable or fixed. Altera's parts and most research groups use fixed
routing, which either means that every routing line is guaranteed to
have the same delay, or that there are certain proscribed delay groups
that each routing wire falls into. Other parts use variable routing
delays.
 Slide 16: System Interface
Slide 16: System InterfaceThe functional units and the interconnect together make up what we call the 'fabric'. The fabric sits inside some sort of system. There are four ways that the fabric can interface with the outside system:
 Slide 17: History
Slide 17: History
PAM and SPLASH-1 were the first reconfigurable devices, and they were
based on the X30xx series. PRISM, DISC, and CVH (aka PipeWrench) fall
into the Co-processor group from slide
16, while P-Risc, and Chimera are Function Unit devices. RaPiD and
RAW are coarse-grained devices. Quickturn contained a huge amount of
reconfigurable fabric and was used as a pre-fabrication logic simulator.
Matrix is a Dynamicly Reconfigurable device, which means that it could
be reconfigured on the fly while program was executing in another part
of the fabric. Devices that are shown above and to the right of the
DISC chip are not based on Xilinx parts, and represent new research in
reconfigurable design. The CAL chip eventually led to the X6200 series.
 Slide 18: Issues in RC Research/Buell
Slide 18: Issues in RC Research/Buell
The six questions that are listed here indicate a misdirection in early
reconfigurable computing research. In this class, we'll attempt to
remedy the situation, by pointing our own research in the right
direction.
 Slide 19: Are FPGAs large enough?
Slide 19: Are FPGAs large enough?Rent's rule provides a sort of natural boundary on the number of I/O wires that are available (Bullet #2). Once you have placed the fabric inside the system, you're pretty much stuck there. The number of I/Os available has been limited, or perhaps even fixed. Buell claims that inside the FPGA, you're okay, but once you start partitioning you have a problem. You may not have enough pins to communicate between pieces of fabric. There is also a large performance cliff: the smaller the fabric, the worse the performance, to the point where if the circuit does not fit performance is zero.
Class discussion
Seth claimed that virtualization is the key
to getting around the size problem. If you can swap parts of the
algorithm in and out like you can with virtual memory on a desktop
machine, then it doesn't matter how large the actual fabric is. Someone
in class reminded him that virtual memory paging is a huge performance
hit; won't swapping parts of the fabric in and out cause a large
performance drop? The difference between desktop machine virtual memory
and most FPGAs today is that at least the desktop lets you take the
performance hit. With FPGA's, it's all or nothing: see the performance
cliff above. It was also mentioned that virtualizing allows for 'upward
compatability': larger devices will allow for better performance with
the same compiled code, since they can fit more of the program on the
fabric at once. Herman noted that there will always be a demand for
larger fabric.
Also on the topic of virtualization, someone in class asked if it was
possible to time-multiplex hardware. Several suggestions were
mentioned, including holding pages of configuration that could be
swapped in and out. "You can do it," Seth exaggurated, "but it will
melt the chip."
 Slide 20: Exposing the Architecture
Slide 20: Exposing the Architecture
How much of the architecture should the programmer need to be aware of?
None. The programmer should be able to write code for the FPGA
in their own language: C++, Java, Fortran, whatever. The compiler
writer should not ever need to know everything about the reconfigurable
device's architecture. What we have in the general-purpose world is an
abstract model with parameters that compiler writers can target. We
need the same sort of model for reconfigurable devices.
 Slide 21: Programming Language/Compiler
Slide 21: Programming Language/CompilerForcing compilers to deal with the device's architecture is hopeless. The question is not "What new language will the designers have to learn in order to use this fabric?" The question should be "How can we develop a model that we can compile to?"
Class Discussion
The point brought up is that compiler
writers have been forced to do this before, but they have always found a
way to do it. Seth claims that this is because there is an abstract
model, with metrics, that exists for all general-purpose computers out
there. Once you get the right handle on the model, a compiler can be
created. Other architectures which don't fit that model very well will
tend to fall by the wayside. The key metric in the general-purpose
world is unit time: I know that (for instance) an addition will take two
cycles, a left-shift will take one cycle, and a multiply will take
eight.
We need to create an abstract machine model that we can compile to. The model should not deal with size, virtualization, reconfigurability, etc. Some abstraction of the processing elements and the interconnect should be enough to get started.
It was noted that hardware parallelism is more notable in a hardware description language like Verilog than in a high-level programming language like C++ or Java. In Verilog, you can have multiple always blocks that clearly define parallel hardware. In C or Java, you have to play with multiple threads. Will it be possible to extract parallelism from this? Seth claimed that automatic parallelism is too difficult to be relied on. It may be necessary to force programmers to learn a new programming style that will work for the new compilers; the example of Seymour Cray was given. It will be possible to write any code you like; but if you want it to run well, you have to write it like this. Seth is willling to go along with this. He also noted that there are different levels of parallelism, some of which are exploitable and some of which are not as available. As an example, someone in class pointed out that MATLAB will parallelize a loop for you, if you write a for-loop over an entire array.
In conclusion, Seth said that the goal of our new compilers (assuming a
co-processor or functional unit interface) is to take a source code file
and spit out two object files: one for the general-purpose processor,
and one for the reconfigurable fabric that is attached to it.
 Slide 22: Range of Architectures Needed?
Slide 22: Range of Architectures Needed?
The important fact here is that not all programs will work well with
reconfigurable fabric. What we need to do is decide which algorithms
are important to us, and then figure out how to perform those functions
particularly well.
 Slide 23: Where do CCMs fit in the ASIC-GP Spectrum?
Slide 23: Where do CCMs fit in the ASIC-GP Spectrum?
Reconfigurable Computing devices do not necessarily fit between ASICs
and General Purpose computing devices. Right now, GPUs offer a good
average performance over all sorts of applications, while CCMs have a
thin, very high peak that spans a small selection of applications. What
we would like to do is increase the range of applications that CCMs can
perform well, and slightly increase the performance of those that they
can't. In order to acquire this generality, it might be necessary to
sacrifice some of the performance gains on the applications that work
well now.
 Slide 24: Research Issues
Slide 24: Research Issues
On the other side of the coin, what happens when the fabric has nothing to do? Can you turn it into extra processor space, more cache, more registers, or anything else? Memory hierarchy will become a problem, much like vector processors, once we take the first few steps. We will have problems with bandwith for fast reconfiguration, espically as fabric gets larger and instruction words get longer.