(Very) Quick summary of recent papers
Language processing: We use naturalistic neuroimaging experiments and encoding models to study language comprehension. We built on our 2014 work in aligning neural network language models with brain activity by showing that increasing the alignment with brain activity can lead to better NLP performance, and by directly fine-tuning language models with brain activity recordings. We have also used naturalistic experimentation and encoding models to show that language comprehension difficulty recruits the language network and not multiple demand regions, to show that syntactic information is distributed in the language network in places that also process semantics, and to show that a naturalistic context leads to much more broad representations of word meaning than more simple contexts. We have proposed the use of post-hoc computational controls, which have revealed that the anterior and posterior temporal lobes are predicted by new meaning that arises from combining words, but that this relationship is only visible in fMRI and not MEG. Further, we show that the encoding models we build can be used to perform in silico replication experiments that combine the interpretability of controlled experiments with the generalizability and broad scope of natural stimulus experiments. Finally, we propose hypotheses for what types of language input is processed differently by language models and the brain, and validate these hypotheses by showing that fine-tuning on relevant tasks makes the language model more aligned with the brain.
Vision: We have studied the effect of the training task of a convolutional neural network (CNN) on its alignment with brain activity and used it to derive relationships between different computer vision tasks from the perspective of their brain alignment, and to show that training CNNs with language supervision and with high data diversity leads to powerful models of the higher visual cortex. We have also constructed powerful hypothesis-neutral models of high-level visual cortex by training CNNs end-to-end to predict fMRI activity and used them to provide strong evidence of categorical selectivity, as well as to showcase spatial preferences of different brain regions. We have shown that higher-visual cortex shows biases for low-level features related to preferred categories, and have identified a new region in the ventral stream that processes food. Further, we have focused on characterizing features that are important for the visual system, by focusing on the representation of mid-level features, investigating the representation of object size and uncovering the spatial features most important for individual voxels. Finally, we have worked on generating optimal images for different brain regions using a diffusion model as well as generating the captions of the optimal images for each voxel, with both methods providing a way to hone into the semantic selectivity of sub-areas of the visual system.
Methods: We believe that naturalistic experiments and computational modeling are promising tools for investigating brain function. We have proposed multiple extensions to encoding models such as the use of stacking to combine multiple feature spaces and specific instantiations of variance partitioning to test more precise hypotheses and the use of data from multiple subjects to denoise MEG responses. In older work, we have shown that the spatial pattern of regularization parameters learned by cross-validation of many types of encoding models closely follows the pattern of prediction accuracy. We have also extended encoding models by proposing approaches to compare the learned representations between two brain regions and more confidently make conclusions about the effect of the stimulus on brain activity. Finally, we have proposed an approach for incorporating tasks effects into a computational model as an attention mechanism.
Health and real-world application: We have shown that encoding models, beyond being useful for identifying commonalities amongst subjects, can also be used to identify individual differences that predict behavior and clinical diagnoses. We have also shown that the MEG data of an individual can be used to identify them and that this identification ability is maximized during a task and in areas engaged in that task. In a more clinical setting, we have worked on making machine learning useful for classifying intra-operative neuromonitoring signals to prevent nerve damage. Finally, we have proposed a transformer model for motor BCI data that is pretrained on neural spiking data from different subjects, sessions and experimental tasks, and is rapidly adaptable to downstream decoding tasks.
Aligning representations from artificial networks and
real brains


Success in AI is often defined as achieving human level performance on tasks such as text or scene understanding. To perform like the human brain, is it useful for neural networks to have representations that are similar to brain representations?
In these projects, we use brain activity recordings to interpret neural network representations, to attempt to find heuristics to improve them, and even to change the weights learned by networks to make them more brain like. The results promise an exciting research direction.
The spatial representation of language sub-processes

In this project, we use functional Magnetic Resonance Imaging (fMRI) to record the brain activity of subjects while they read an unmodified chapter of a popular book. We model the measured brain activity as a function of the content of the text being read. Our model is able to extrapolate to predict brain activity for novel passages of text - beyond those on which it has been trained. Not only can our model be used for decoding what passage of text was being read from brain activity, but it can also report which type of information about the text (syntax, semantic properties, narrative events etc.) is modulating the activity of every brain region. Using this model, we found that the different regions that are usually associated with language appear to be processing different types of linguistic information. We were able to build detailed reading representations maps, in which each voxel is labeled by the type of information the model suggests it is processing.
Our approach is important in many ways. We are able not only to detect where language processing increases brain activity, but to also reveal what type of information is encoded in each one of the regions that are classically reported as responsive to language. From just one experiment, we can reproduce a mutiple findings. Had we chosen to follow the classical method, each of our results would have required its own experiment. This approach could make neuroimaging much more flexible. If a researcher develops a new reading theory after running an experiment, they would annotate the stimulus text accordingly, and test the theory against the previously recorded data without having to collect new experimental data.
The time-line of meaning construction

To study the sub-word dynamics of story reading, we turned to Magnetoencephalography (MEG), which records brain activity at a time resolution of one millisecond. We recorded the MEG activity when the subjects undergo the same naturalistic task of reading a complex chapter from a popular novel. We were interested in identifying the different stages of continuous meaning construction when subjects read a text. We noticed the similarity between neural network language models which can ``read" a text word by word and predict the next word in a sentence, and the human brain. Both the models and the brain have to maintain a representation of the previous context, they have to represent the features of the incoming word and integrate it with the previous context before moving on to the next word.
We used the neural network language model to detect these different processes in brain data. Our novel results include a suggested time-line of how the brain updates its representation of context. They also demonstrate the incremental perception of every new word starting early in the visual cortex, moving next to the temporal lobes and finally to the frontal regions. Furthermore, the results suggest the integration process occurs in the temporal lobes after the new word has been perceived.
L. Wehbe, A. Vaswani, K. Knight, T. Mitchell
Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP, long paper).
supporting website pdf conference talk video bibtex
Abstract: Many statistical models for natural language processing exist, including context-based neural networks that (1) model the previously seen context as a latent feature vector, (2) integrate successive words into the context using some learned representation (embedding), and (3) compute output probabilities for incoming words given the context. On the other hand, brain imaging studies have suggested that during reading, the brain (a) continuously builds a context from the successive words and every time it encounters a word it (b) fetches its properties from memory and (c) integrates it with the previous context with a degree of effort that is inversely proportional to how probable the word is. This hints to a parallelism between the neural networks and the brain in modeling context (1 and a), representing the incoming words (2 and b) and integrating it (3 and c). We explore this parallelism to better understand the brain processes and the neural networks representations. We study the alignment between the latent vectors used by neural networks and brain activity observed via Magnetoencephalography (MEG) when subjects read a story. For that purpose we apply the neural network to the same text the subjects are reading, and explore the ability of these three vector representations to predict the observed word-by-word brain activity.
Our novel results show that: before a new word i is read, brain activity is well predicted by the neural network latent representation of context and the predictability decreases as the brain integrates the word and changes its own representation of context. Secondly, the neural network embedding of word i can predict the MEG activity when word i is presented to the subject, revealing that it is correlated with the brain's own representation of word i. Moreover, we obtain that the activity is predicted in different regions of the brain with varying delay. The delay is consistent with the placement of each region on the processing pathway that starts in the visual cortex and moves to higher level regions. Finally, we show that the output probability computed by the neural networks agrees with the brain's own assessment of the probability of word i, as it can be used to predict the brain activity after the word i's properties have been fetched from memory and the brain is in the process of integrating it into the context.
L. Wehbe, B. Murphy, P. Talukdar, A. Fyshe, A. Ramdas, T. Mitchell
PLOS ONE, 2014.
supporting website (data) journal website pdf supplementary material bibtex
Abstract: Story understanding involves many perceptual and cognitive subprocesses, from perceiving individual words, to parsing sentences, to understanding the relationships among the story characters. We present an integrated computational model of reading that incorporates these and additional subprocesses, simultaneously discovering their fMRI signatures. Our model predicts the fMRI activity associated with reading arbitrary text passages, well enough to distinguish which of two story segments is being read with 74% accuracy. This approach is the first to simultaneously track diverse reading subprocesses during complex story processing and predict the detailed neural representation of diverse story features, ranging from visual word properties to the mention of different story characters and different actions they perform. We construct brain representation maps that replicate many results from a wide range of classical studies that focus each on one aspect of language processing, and offers new insights on which type of information is processed by different areas involved in language processing. Additionally, this approach is promising for studying individual differences: it can be used to create single subject maps that may potentially be used to measure reading comprehension and diagnose reading disorders.
G. Sudre, D. Pomerleau, M. Palatucci, L. Wehbe, A. Fyshe, R. Salmelin and T. Mitchell
NeuroImage, 2012.
 journal website pdf bibtex
journal website pdf bibtex
We present a methodological approach employing magnetoencephalography (MEG) and machine learning techniques to investigate the flow of perceptual and semantic information decodable from neural activity in the half second during which the brain comprehends the meaning of a concrete noun. Important information about the cortical location of neural activity related to the representation of nouns in the human brain has been revealed by past studies using fMRI. However, the temporal sequence of processing from sensory input to concept comprehension remains unclear, in part because of the poor time resolution provided by fMRI. In this study, subjects answered 20 questions (e.g. is it alive?) about the properties of 60 different nouns prompted by simultaneous presentation of a pictured item and its written name. Our results show that the neural activity observed with MEG encodes a variety of perceptual and semantic features of stimuli at different times relative to stimulus onset, and in different cortical locations. By decoding these features, our MEG-based classifier was able to reliably distinguish between two different concrete nouns that it had never seen before. The results demonstrate that there are clear differences between the time course of the magnitude of MEG activity and that of decodable semantic information. Perceptual features were decoded from MEG activity earlier in time than semantic features, and features related to animacy, size, and manipulability were decoded consistently across subjects. We also observed that regions commonly associated with semantic processing in the fMRI literature may not show high decoding results in MEG. We believe that this type of approach and the accompanying machine learning methods can form the basis for further modeling of the flow of neural information during language processing and a variety of other cognitive processes.
L. Wehbe, A. Ramdas, R. C. Steorts, C. R. Shalizi
Annals of Applied Statistics, 2015.
 pdf
journal website
arXiv
bibtex
pdf
journal website
arXiv
bibtex
Abstract: Functional neuroimaging measures how the brain responds to complex stimuli. However, sample sizes are modest, noise is substantial, and stimuli are high-dimensional. Hence, direct estimates are inherently imprecise and call for regularization. We compare a suite of approaches which regularize via shrinkage: ridge regression, the elastic net (a generalization of ridge regression and the lasso), and a hierarchical Bayesian model based on small-area estimation (SAE) ideas. The SAE approach draws heavily on borrowing strength from related areas as to make estimates more precise. We contrast regularization with spatial smoothing and combinations of smoothing and shrinkage. All methods are tested on functional magnetic resonance imaging data from multiple subjects participating in two different experiments related to reading, for both predicting neural response to stimuli and decoding stimuli from responses. Interestingly, cross validation (CV) automatically picks very low/high regularization parameters in regions where the classification accuracy is high/low, indicating that CV is a good tool for identification of relevant voxels for each feature. However, surprisingly, all the regularization methods work equally well, suggesting that beating basic smoothing and shrinkage will take not just clever methods, but careful modeling.
L. Wehbe*, A. Ramdas* (equal contribution)
Proceedings of the 2015 International Joint Conference on Artificial Intelligence (IJCAI, oral presentation) .
 pdf
arXiv
bibtex
pdf
arXiv
bibtex
Abstract: This paper deals with the problem of nonparametric independence testing, a fundamental decision-theoretic problem that asks if two arbitrary (possibly multivariate) random variables X,Y are independent or not, a question that comes up in many fields like causality and neuroscience. While quantities like correlation of X,Y only test for (univariate) linear independence, natural alternatives like mutual information of X,Y are hard to estimate due to a serious curse of dimensionality. A recent approach, avoiding both issues, estimates norms of an operator in Reproducing Kernel Hilbert Spaces (RKHSs). Our main contribution is strong empirical evidence that by employing shrunk operators when the sample size is small, one can attain an improvement in power at low false positive rates. We analyze the effects of Stein shrinkage on a popular test statistic called HSIC (Hilbert-Schmidt Independence Criterion). Our observations provide insights into two recently proposed shrinkage estimators, SCOSE and FCOSE - we prove that SCOSE is (essentially) the optimal linear shrinkage method for estimating the true operator; however, the non-linearly shrunk FCOSE usually achieves greater improvements in test power. This work is important for more powerful nonparametric detection of subtle nonlinear dependencies for small samples.
A. Fyshe, L. Wehbe, P. Talukdar, B. Murphy and T. Mitchell
Proceedings of the 2015 Conference of the North American Chapter of the ACL, chosen for oral presentation (NAACL 2015).

pdf bibtex
Abstract: Vector Space Models (VSMs) of Semantics are useful tools for exploring the semantics of single words, and the composition of words to make phrasal meaning. While many methods can estimate the meaning (i.e. vector) of a phrase, few do so in an interpretable way. We introduce a new method (CNNSE) that allows word and phrase vectors to adapt to the notion of composition. Our method learns a VSM that is both tailored to support a chosen semantic composition operation, and whose resulting features have an intuitive interpretation. Interpretability allows for the exploration of phrasal semantics, which we leverage to analyze performance on a behavioral task.
A. Fyshe, G. Sudre, L. Wehbe, N. Rafidi, T. M. Mitchell
Human Brain Mapping, 2019.
 Journal
bioRXiv
bibtex
Journal
bioRXiv
bibtex
Abstract: As a person reads, the brain performs complex operations to create higher order semantic representations from individual words. While these steps are effortless for competent readers, we are only beginning to understand how the brain performs these actions. Here, we explore semantic composition using magnetoencephalography (MEG) recordings of people reading adjective-noun phrases presented one word at a time. We track the neural representation of semantic information over time, through different brain regions. Our results reveal several novel findings: 1) the neural representation of adjective semantics observed during adjective reading is reactivated after phrase reading, with remarkable consistency, 2) a neural representation of the adjective is also present during noun presentation, but this neural representation is the reverse of that observed during adjective presentation 3) the neural representation of adjective semantics are oscillatory and entrained to alpha band frequencies. We also introduce a new method for analyzing brain image time series called Time Generalized Averaging. Taken together, these results paint a picture of information flow in the brain as phrases are read and understood.
L. Wehbe, A. Fyshe, T. Mitchell
Human Language: from Genes and Brains to Behavior, MIT Press, 2019 .
book
Abstract: People have long been curious about how the brain represents what it knows. What does the brain do when it recalls a concept, and what does it mean to understand a sentence? We explore the brain's representation of the meaning of words, and how the brain integrates linguistic context into sentence understanding. Taking inspiration from previous work in computational linguistics, we define word meaning in terms of numerical representations called word vectors. Combining these word vector representations with machine learning algorithms, we train computational models that map from observed neural activity to these vector representations of meaning. This approach enables us to detect brain representations of a wide variety of linguistic stimuli, even stimuli beyond those used to train the model. This capability to detect the representation of novel stimuli opens up a whole new world of experimental design wherein we can cover highly diverse stimuli, including experiments where there is no repetition of stimuli at all. We present case studies demonstrating the use of this approach to analyze comprehension of adjective-noun phrases, and reading of entire stories. We close by looking to the future of cognitive neuroscience under these more permissive experimental conditions.
B. Murphy, L. Wehbe, A. Fyshe
Language, Cognition, and Computational Models, Cambridge University Press, 2018 .

book
Abstract: In this paper we review recent computational approaches to the study of language with neuroimaging data. Recordings of brain activity have long played a central role in furthering our understanding of how human language works, with researchers usually choosing to focus tightly on one aspect of the language system. This choice is driven both by the complexity of that system, and by the noise and complexity in neuroimaging data itself. State-of-the-art computational methods can help in two respects: in teasing more information from recordings of brain activity and by allowing us to test broader and more articu- lated theories and detailed representations of language tasks. In this chapter we rst set the scene with a succinct review of neuroimaging techniques and what they have taught us about language processing in the brain. We then describe how recent work has used machine learn- ing methods with brain data and computational models of language to investigate how words and phrases are processed. We nish by intro- ducing emerging naturalistic paradigms that combine authentic lan- guage tasks (e.g., reading or listening to a story) with rich models of lexical, sentential, and suprasentential representations to enable an all- round view of language processing.
H. Chen, C. Hu, L. Wehbe and S. Lin.
Proceedings of the 2019 Conference of the North American Chapter of the ACL (NAACL), oral presentation.

pdf bibtex
Abstract: Unsupervised document representation learning is an important task providing pre-trained features for NLP applications. Unlike most previous work which learn the embedding based on self-prediction of the surface of text, we explicitly exploit the inter-document information and directly model the relations of documents in embedding space with a discriminative network and a novel objective. Extensive experiments on both small and large public datasets show the competitiveness of the proposed method. In evaluations on standard document classification, our model has errors that are relatively 5 to 13% lower than state-of the-art unsupervised embedding models. The reduction in error is even more pronounced in scarce label setting.
M. Toneva and L. Wehbe .
Neural Information Processing Systems (NeurIPS) 2019.
arXiv bibtex
Abstract: Neural network models for NLP are typically implemented without the explicit encoding of language rules and yet they are able to break one performance record after another. Despite much work, it is still unclear what the representations learned by these networks correspond to. We propose here a novel approach for interpreting neural networks that relies on the only processing system we have that does understand language: the human brain. We use brain imaging recordings of subjects reading complex natural text to interpret word and sequence embeddings from 4 recent NLP models - ELMo, USE, BERT and Transformer-XL. We study how their representations differ across layer depth, context length, and attention type. Our results reveal differences in the context-related representations across these models. Further, in the transformer models, we find an interaction between layer depth and context length, and between layer depth and attention type. We finally use the insights from the attention experiments to alter BERT: we remove the learned attention at shallow layers, and show that this manipulation improves performance on a wide range of syntactic tasks. Cognitive neuroscientists have already begun using NLP networks to study the brain, and this work closes the loop to allow the interaction between NLP and cognitive neuroscience to be a true cross-pollination.
A. Wang, M. Tarr and L. Wehbe.
Neural Information Processing Systems (NeurIPS) 2019.
bioRxiv bibtex
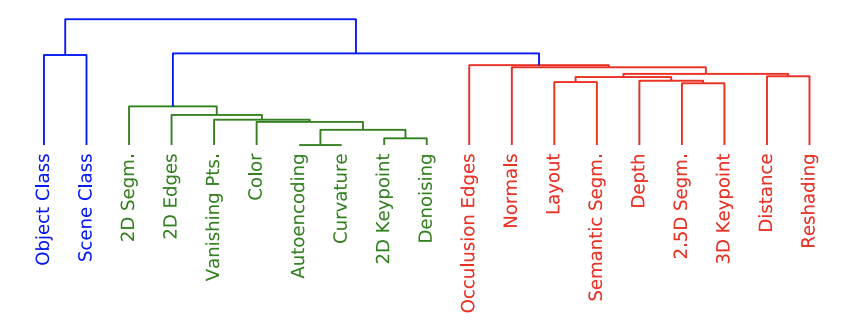
Abstract: Convolutional neural networks (CNNs) trained for object recognition have been widely used to account for visually-driven neural responses in both the human and primate brains. However, because of the generality and complexity of the task of object classification, it is often difficult to make precise inferences about neural information processing using CNN representations from object classification despite the fact that these representations are effective for predicting brain activity. To better understand underlying the nature of the visual features encoded in different brain regions of the human brain, we predicted brain responses to images using fine-grained representations drawn from 19 specific computer vision tasks. Individual encoding models for each task were constructed and then applied to BOLD5000—a large-scale dataset comprised of fMRI scans collected while observers viewed over 5000 naturalistic scene and object images. Because different encoding models predict activity in different brain regions, we were able to associate specific vision tasks with each region. For example, within scene-selective brain regions, features from 3D tasks such as 3D keypoints and 3D edges explain greater variance as compared to 2D tasks—a pattern that replicates across the whole brain. Using results across all 19 task representations, we constructed a “task graph” based on the spatial layout of well-predicted brain areas from each task. We then compared the brain-derived task structure with the task structure derived from transfer learning accuracy in order to assess the degree of shared information between the two task spaces. These computationally-driven results—arising out of state-of-the-art computer vision methods—begin to reveal the task-specific architecture of the human visual system.
D. Schwartz, M. Toneva and L. Wehbe.
Neural Information Processing Systems (NeurIPS) 2019.

arXiv
Abstract: Progress in natural language processing (NLP) models that estimate representations of word sequences has recently been leveraged to improve the understanding of language processing in the brain. However, these models have not been specifically designed to capture the way the brain represents language meaning. We hypothesize that fine-tuning these models to predict recordings of brain activity of people reading text will lead to representations that encode more brain-activity-relevant language information. We demonstrate that a version of BERT, a recently introduced and powerful language model, can improve the prediction of brain activity after fine-tuning. We show that the relationship between language and brain activity learned by BERT during this fine-tuning transfers across multiple participants. We also show that fine-tuned representations learned from both magnetoencephalography (MEG) and functional magnetic resonance imaging (fMRI) are better for predicting fMRI than the representations learned from fMRI alone, indicating that the learned representations capture brain-activity-relevant information that is not simply an artifact of the modality. While changes to language representations help the model predict brain activity, they also do not harm the model's ability to perform downstream NLP tasks. Our findings are notable for research on language understanding in the brain.
L. Wehbe , I. Blank, C. Shain, R. Futrell, R. Levy, T. von der Malsburg, N. Smith, E. Gibson, E. Fedorenko.
Cerebral Cortex, 2021.

journal pdf bibtex
Abstract: What role do domain-general executive functions play in human language comprehension? To address this question, we examine the relationship between behavioral measures of comprehension and neural activity in the domain-general "multiple demand" (MD) network, which has been linked to constructs like attention, working memory, inhibitory control, and selection, and implicated in diverse goal-directed behaviors. Specifically, fMRI data collected during naturalistic story listening are compared to theory-neutral measures of online comprehension difficulty and incremental processing load (reading times and eye-fixation durations). Critically, to ensure that variance in these measures is driven by features of the linguistic stimulus rather than reflecting participant- or trial-level variability, the neuroimaging and behavioral datasets were collected in non-overlapping samples. We find no behavioral-neural link in functionally localized MD regions; instead, this link is found in the domain-specific, fronto-temporal "core language network", in both left hemispheric areas and their right hemispheric homologues. These results argue against strong involvement of domain-general executive circuits in language comprehension.
A. Reddy, L. Wehbe.
Neural Information Processing Systems (NeurIPS) 2021.

NeurIPS bioRxiv
Abstract: While studying semantics in the brain, neuroscientists use two approaches. One is to identify areas that are correlated with semantic processing load. Another is to find areas that are predicted by the semantic representation of the stimulus words. However, in the domain of syntax, most studies have focused only on identifying areas correlated with syntactic processing load. One possible reason for this discrepancy is that representing syntactic structure in an embedding space such that it can be used to model brain activity is a non-trivial computational problem. Another possible reason is that it is unclear if the low signal-to-noise ratio of neuroimaging tools such as functional Magnetic Resonance Imaging (fMRI) can allow us to reveal correlates of complex (and perhaps subtle) syntactic representations. In this study, we propose novel multi-dimensional features that encode information about the syntactic structure of sentences. Using these features and fMRI recordings of participants reading a natural text, we model the brain representation of syntax. First, we find that our syntactic structure-based features explain additional variance in the brain activity of various parts of the language system, even after controlling for complexity metrics that capture processing load. At the same time, we see that regions well-predicted by syntactic features are distributed in the language system and are not distinguishable from those processing semantics.
S. Wu, A. Ramdas and L. Wehbe.
Communications Biology, 2022.

journal bioRxiv
Abstract: Neuroimaging tools have been widely adopted to study the anatomical and functional properties of the brain. Magnetoencephalography (MEG), a neuroimaging method prized for its high temporal resolution, records magnetic field changes due to brain activity and has been used to study the cognitive processes underlying various tasks. As the research community increasingly embraces the principles of open science, a growing amount of MEG data has been published online. However, the prevalence of MEG data sharing may pose unforeseen privacy issues. We argue that an individual may be identified from a segment of their MEG recording even if their data has been anonymized. From our standpoint, individual identifiability is closely related to individual variability of brain activity, which is itself a widely studied scientific topic. In this paper, we propose three interpretable spatial, temporal, and frequency MEG featurizations that we term brainprints (brain fingerprints). We show using multiple datasets that these brainprints can accurately identify individuals, and we reveal consistent components of these brainprints that are important for identification. We also investigate how identification accuracy varies with respect to the abundance of data, the level of preprocessing, and the state of the brain. Our findings pinpoint how individual variability expresses itself through MEG, a topic of scientific interest, while raising ethical concerns about the unregulated sharing of brain data, even if anonymized.
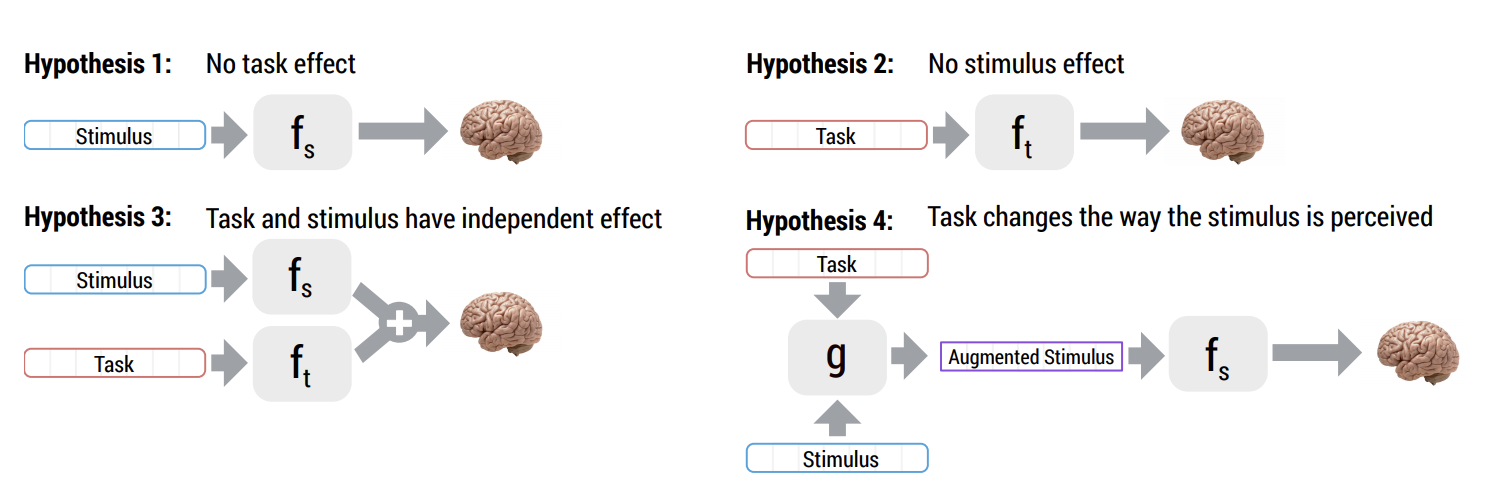
M. Toneva, O. Stretcu, B. Poczos, L. Wehbe, T. Mitchell
Neural Information Processing Systems (NeurIPS) 2020.
neurips arXiv
Abstract: How meaning is represented in the brain is still one of the big open questions in neuroscience. Does a word (e.g., bird) always have the same representation, or does the task under which the word is processed alter its representation (answering "can you eat it?" versus "can it fly?")? The brain activity of subjects who read the same word while performing different semantic tasks has been shown to differ across tasks. However, it is still not understood how the task itself contributes to this difference. In the current work, we study Magnetoencephalography (MEG) brain recordings of participants tasked with answering questions about concrete nouns. We investigate the effect of the task (i.e. the question being asked) on the processing of the concrete noun by predicting the millisecond-resolution MEG recordings as a function of both the semantics of the noun and the task. Using this approach, we test several hypotheses about the task-stimulus interactions by comparing the zero-shot predictions made by these hypotheses for novel tasks and nouns not seen during training. We find that incorporating the task semantics significantly improves the prediction of MEG recordings, across participants. The improvement occurs 475-550ms after the participants first see the word, which corresponds to what is considered to be the ending time of semantic processing for a word. These results suggest that only the end of semantic processing of a word is task-dependent, and pose a challenge for future research to formulate new hypotheses for earlier task effects as a function of the task and stimuli.
M. Toneva, T. Mitchell, L. Wehbe
Nature Computational Science, 2022.

journal bioRxiv view
Abstract: To study a core component of human intelligence---our ability to combine the meaning of words---neuroscientists look for neural correlates of meaning composition, such as brain activity proportional to the difficulty of understanding a sentence. However, little is known about the product of meaning composition—the combined meaning of words beyond their individual meaning. We term this product “supra-word meaning” and devise a computational representation for it by using recent neural network algorithms and a new technique to disentangle composed-from individual-word meaning. Using functional magnetic resonance imaging, we reveal that hubs that are thought to process lexical-level meaning also maintain supra-word meaning, suggesting a common substrate for lexical and combinatorial semantics. Surprisingly, we cannot detect supra-word meaning in magnetoencephalography, which suggests that composed meaning is maintained through a different neural mechanism than synchronized firing. This sensitivity difference has implications for past neuroimaging results and future wearable neurotechnology.
X. Zha, L. Wehbe, R. Sclabassi, Z. Mace, Y. Liang, A. Yu, J. Leonardo, B. Cheng, T. Hillman, D. Chen, C. Riviere
IEEE Transactions on Medical Robotics and Bionics, 2020.
journal website bibtex
Abstract: Objective: Intraoperative neurophysiological monitoring (IONM) is the use of electrophysiological methods during certain high-risk surgeries to assess the functional integrity of nerves in real time and alert the surgeon to prevent damage. However, the efficiency of IONM in current practice is limited by latency of verbal communications, inter-rater variability, and the subjective manner in which electrophysiological signals are described. Methods: In an attempt to address these shortcomings, we investigate automated classification of free-running electromyogram (EMG) waveforms during IONM. We propose a hybrid model with a convolutional neural network (CNN) component and a long short-term memory (LSTM) component to better capture complicated EMG patterns under conditions of both electrical noise and movement artifacts. Moreover, a preprocessing pipeline based on data normalization is used to handle classification of data from multiple subjects. To investigate model robustness, we also analyze models under different methods for processing of artifacts. Results: Compared with several benchmark modeling methods, CNN-LSTM performs best in classification, achieving accuracy of 89.54% and sensitivity of 94.23% in cross-patient evaluation. Conclusion: The CNN-LSTM model shows promise for automated classification of continuous EMG in IONM. Significance: This technique has potential to improve surgical safety by reducing cognitive load and inter-rater variability.
S. Ravishankar, M. Toneva, L. Wehbe. Frontiers In Computational Neuroscience , 2021.

journal
Abstract: A pervasive challenge in brain imaging is the presence of noise that hinders investigation of underlying neural processes, with Magnetoencephalography (MEG) in particular having very low Signal-to-Noise Ratio (SNR). The established strategy to increase MEG's SNR involves averaging multiple repetitions of data corresponding to the same stimulus. However, repetition of stimulus can be undesirable, because underlying neural activity has been shown to change across trials, and repeating stimuli limits the breadth of the stimulus space experienced by subjects. In particular, the rising popularity of naturalistic studies with a single viewing of a movie or story necessitates the discovery of new approaches to increase SNR. We introduce a simple framework to reduce noise in single-trial MEG data by leveraging correlations in neural responses across subjects as they experience the same stimulus. We demonstrate its use in a naturalistic reading comprehension task with 8 subjects, with MEG data collected while they read the same story a single time. We find that our procedure results in data with reduced noise and allows for better discovery of neural phenomena. As proof-of-concept, we show that the N400m's correlation with word surprisal, an established finding in literature, is far more clearly observed in the denoised data than the original data. The denoised data also shows higher decoding and encoding accuracy than the original data, indicating that the neural signals associated with reading are either preserved or enhanced after the denoising procedure.
F. Deniz*, C. Tseng*, L. Wehbe, T. Dupre la Tour, J. Gallant.
Journal of Neuroscience, 2023.

journal bioRxiv
Abstract: The meaning of words in natural language depends crucially on context. However, most neuroimaging studies of word meaning use isolated words and isolated sentences with little context. Because the brain may process natural language differently from how it processes simplified stimuli, there is a pressing need to determine whether prior results on word meaning generalize to natural language. fMRI was used to record human brain activity while four subjects (two female) read words in four conditions that vary in context: narratives, isolated sentences, blocks of semantically similar words, and isolated words. We then compared the signal-to-noise ratio (SNR) of evoked brain responses, and we used a voxelwise encoding modeling approach to compare the representation of semantic information across the four conditions. We find four consistent effects of varying context. First, stimuli with more context evoke brain responses with higher SNR across bilateral visual, temporal, parietal, and prefrontal cortices compared to stimuli with little context. Second, increasing context increases the representation of semantic information across bilateral temporal, parietal, and prefrontal cortices at the group level. In individual subjects, only natural language stimuli consistently evoke widespread representation of semantic information. Third, context affects voxel semantic tuning. Finally, models estimated using stimuli with little context do not generalize well to natural language. These results show that context has large effects on the quality of neuroimaging data and on the representation of meaning in the brain. Thus, neuroimaging studies that use stimuli with little context may not generalize well to the natural regime.
J. Williams, L. Wehbe.
in review.

arXiv
Abstract: Similar to how differences in the proficiency of the cardiovascular and musculoskeletal system predict an individual's athletic ability, differences in how the same brain region encodes information across individuals may explain their behavior. However, when studying how the brain encodes information, researchers choose different neuroimaging tasks (e.g., language or motor tasks), which can rely on processing different types of information and can modulate different brain regions. We hypothesize that individual differences in how information is encoded in the brain are task-specific and predict different behavior measures. We propose a framework using encoding-models to identify individual differences in brain encoding and test if these differences can predict behavior. We evaluate our framework using task functional magnetic resonance imaging data. Our results indicate that individual differences revealed by encoding-models are a powerful tool for predicting behavior, and that researchers should optimize their choice of task and encoding-model for their behavior of interest.
M. Toneva*, J. Williams*, A. Bollu, C. Dann, L. Wehbe.
Proceedings of the Conference on Causal Learning and Reasoning (CLeaR) 2022.

conference arXiv
Abstract: To study information processing in the brain, neuroscientists manipulate experimental stimuli while recording participant brain activity. They can then use encoding models to find out which brain "zone" (e.g. which region of interest, volume pixel or electrophysiology sensor) is predicted from the stimulus properties. Given the assumptions underlying this setup, when stimulus properties are predictive of the activity in a zone, these properties are understood to cause activity in that zone.
In recent years, researchers have used neural networks to construct representations that capture the diverse properties of complex stimuli, such as natural language or natural images. Encoding models built using these high-dimensional representations are often able to significantly predict the activity in large swathes of cortex, suggesting that the activity in all these brain zones is caused by stimulus properties captured in the representation. It is then natural to ask: "Is the activity in these different brain zones caused by the stimulus properties in the same way?" In neuroscientific terms, this corresponds to asking if these different zones process the stimulus properties in the same way.
Here, we propose a new framework that enables researchers to ask if the properties of a stimulus affect two brain zones in the same way. We use simulated data and two real fMRI datasets with complex naturalistic stimuli to show that our framework enables us to make such inferences. Our inferences are strikingly consistent between the two datasets, indicating that the proposed framework is a promising new tool for neuroscientists to understand how information is processed in the brain.
M. Khosla, L. Wehbe.
in review.

bioRxiv
Abstract: Investigation of the visual system has mainly relied on a-priori hypotheses to restrict experimental stimuli or models used to analyze experimental data. Hypotheses are an essential part of scientific inquiry, but an exclusively hypothesis-driven approach might lead to confirmation bias towards existing theories and away from novel discoveries not predicted by them. This paper uses a hypothesis-neutral computational approach to study four high-level visual regions of interest (ROIs) selective to faces, places, letters, or body parts. We leverage the unprecedented scale and quality of the Natural Scenes Dataset to constrain neural network models of these ROIs with functional Magnetic Resonance Imaging (fMRI) measurements. We show that using only the stimulus images and the associated activity in an ROI, we are able to train from scratch a neural network that can predict the activity in each voxel of that ROI with an accuracy that beats state-of-the-art models. Moreover, once trained, the ROI-specific networks can reveal what kinds of functional properties emerge spontaneously in their training. Strikingly, despite no category-level supervision, the units in the trained networks act strongly as detectors for semantic concepts like ‘faces’ or ‘words’, thereby providing sub-stantial pieces of evidence for categorical selectivity in these visual areas. Importantly, this selectivity is maintained when training the networks with selective deprivations in the training diet, by excluding images that contain their preferred category. The resulting selectivity in the trained networks strongly suggests that the visual areas do not function as exclusive category detectors but are also sensitive to visual patterns that are typical to their preferred categories, even in the absence of these categories. Finally, we show that our response-optimized networks have distinct functional properties. Together, our findings suggest that response-optimized models combined with model interpretability techniques can serve as a powerful and unifying computational framework for probing the nature of representations and computations in the brain.
M. Henderson, M. Tarr, L. Wehbe.
Journal of Vision, 2023.

journal bioRxiv
Abstract: Representations of visual and semantic information can overlap in human visual cortex, with the same neural populations exhibiting sensitivity to low-level features (orientation, spatial frequency, retinotopic position), and high-level semantic categories (faces, scenes). It has been hypothesized that this relationship between low-level visual and high-level category neural selectivity reflects natural scene statistics, such that neurons in a given category-selective region are tuned for low-level features or spatial positions that are diagnostic of the region’s preferred category. To address the generality of this “natural scene statistics” hypothesis, as well as how well it can account for responses to complex naturalistic images across visual cortex, we performed two complementary analyses. First, across a large set of rich natural scene images, we demonstrated reliable associations between low-level (Gabor) features and high-level semantic dimensions (indoor-outdoor, animacy, real-world size), with these relationships varying spatially across the visual field. Second, we used a large-scale fMRI dataset (the Natural Scenes Dataset) and a voxelwise forward encoding model to estimate the feature and spatial selectivity of neural populations throughout visual cortex. We found that voxels in category-selective visual regions exhibit systematic biases in their feature and spatial selectivity which are consistent with their hypothesized roles in category processing. We further showed that these low-level tuning biases are largely independent of viewed image category. Together, our results are consistent with a framework in which low-level feature selectivity contributes to the computation of high-level semantic category information in the brain.
N. Jain, A. Wang, M. Henderson, R. Lin, J. Prince, M. Tarr, L. Wehbe.
Communications Biology, 2023.

journal github data bioRxiv
Abstract: Visual cortex contains regions of selectivity for domains of ecological importance. Food is an evolutionarily critical category whose visual heterogeneity may make the identification of selectivity more challenging. We investigate neural responsiveness to food using natural images combined with large-scale human fMRI. Leveraging the improved sensitivity of modern designs and statistical analyses, we identify two food-selective regions in the ventral visual cortex. Our results are robust across 8 subjects from the Natural Scenes Dataset (NSD), multiple independent image sets and multiple analysis methods. We then test our findings of food selectivity in an fMRI “localizer” using grayscale food images. These independent results confirm the existence of food selectivity in ventral visual cortex and help illuminate why earlier studies may have failed to do so. Our identification of food-selective regions stands alongside prior findings of functional selectivity and adds to our understanding of the organization of knowledge within the human visual system.
M. Henderson, M. Tarr, L. Wehbe.
Journal of Neuroscience, 2023.

journal bioRxiv
Abstract: Mid-level visual features, such as contour and texture, provide a computational link between low- and high-level visual representations. While the detailed nature of mid-level representations in the brain is not yet fully understood, past work has suggested that a texture statistics model (P-S model; Portilla and Simoncelli, 2000) is a candidate for predicting neural responses in areas V1-V4 as well as human behavioral data. However, it is not currently known how well this model accounts for the responses of higher visual cortex regions to natural scene images. To examine this, we constructed single voxel encoding models based on P-S statistics and fit the models to fMRI data from human subjects (male and female) from the Natural Scenes Dataset (Allen et al., 2021). We demonstrate that the texture statistics encoding model can predict the held-out responses of individual voxels in early retinotopic areas as well as higher-level category-selective areas. The ability of the model to reliably predict signal in higher visual cortex voxels suggests that the representation of texture statistics features is widespread throughout the brain, potentially playing a role in higher-order processes like object recognition. Furthermore, we use variance partitioning analyses to identify which features are most uniquely predictive of brain responses, and show that the contributions of higher-order texture features increases from early areas to higher areas on the ventral and lateral surface of the brain. These results provide a key step forward in characterizing how mid-level feature representations emerge hierarchically across the visual system.
A. Wang, K. Kay, T. Naselaris, M. Tarr, L. Wehbe.
Nature Machine Intelligence, 2023.

journal view bioRxiv
We hypothesize that high-level visual representations contain more than the representation of individual categories: they represent complex semantic information inherent in scenes that is most relevant for interaction with the world. Consequently, multimodal models such as Contrastive Language-Image Pre-training (CLIP) which construct image embeddings to best match embeddings of image captions should better predict neural responses in visual cortex, since image captions typically contain the most semantically relevant information in an image for humans. We extracted image features using CLIP, which encodes visual concepts with supervision from natural language captions. We then used voxelwise encoding models based on CLIP features to predict brain responses to real-world images from the Natural Scenes Dataset. CLIP explains up to R2 = 78% of variance in stimulus-evoked responses from individual voxels in the held out test data. CLIP also explains greater unique variance in higher-level visual areas compared to models trained only with image/label pairs (ImageNet trained ResNet) or text (BERT). Visualizations of model embeddings and Principal Component Analysis (PCA) reveal that, with the use of captions, CLIP captures both global and fine-grained semantic dimensions represented within visual cortex. Based on these novel results, we suggest that human understanding of their environment form an important dimension of visual representation.
S. Jain, V. Vo, L. Wehbe, A. Huth.
Neurobiology of Language, 2024.

journal
Abstract: Language neuroscience currently relies on two major experimental paradigms: controlled experiments using carefully hand-designed stimuli, and natural stimulus experiments. These approaches have complementary advantages which allow them to address distinct aspects of the neurobiology of language, but each approach also comes with drawbacks. Here we discuss a third paradigm—in silico experimentation using deep learning-based encoding models—that has been enabled by recent advances in cognitive computational neuroscience. This paradigm promises to combine the interpretability of controlled experiments with the generalizability and broad scope of natural stimulus experiments. We show four examples of simulating language neuroscience experiments in silico and then, discuss both the advantages and caveats of this approach.
P. Herholz, E. Fortier, M. Toneva, N. Farrugia, L. Wehbe, V. Borghesani.
Neurons, Behavior, Data analysis, and Theory, 2023.
 journal
journal Abstract: Real-world generalization, e.g., deciding to approach a neverseen-before animal, relies on contextual information as well as previous experiences. Such a seemingly easy behavioral choice requires the interplay of multiple neural mechanisms, from integrative encoding to category-based inference, weighted differently according to the circumstances. Here, we argue that a comprehensive theory of the neuro-cognitive substrates of real-world generalization will greatly benefit from empirical research with three key elements. First, the ecological validity provided by multimodal, naturalistic paradigms. Second, the model stability afforded by deep sampling. Finally, the statistical rigor granted by predictive modeling and computational controls.
R. Lin, T. Naselaris, K. Kay, L. Wehbe.
Neuroimage, 2024.
 journal bioRxiv github
Abstract:
Relating brain activity associated with a complex stimulus to different properties of that stimulus is a powerful approach for constructing functional brain maps. However, when stimuli are naturalistic, their properties are often correlated (e.g., visual and semantic features of natural images, or different layers of a convolutional neural network that are used as features of images). Correlated properties can act as confounders for each other and complicate the interpretability of brain maps, and can impact the robustness of statistical estimators. Here, we present an approach for brain mapping based on two proposed methods: stacking different encoding models and structured variance partitioning. Our stacking algorithm combines encoding models that each use as input a feature space that describes a different stimulus attribute. The algorithm learns to predict the activity of a voxel as a linear combination of the outputs of different encoding models. We show that the resulting combined model can predict held-out brain activity better or at least as well as the individual encoding models. Further, the weights of the linear combination are readily interpretable; they show the importance of each feature space for predicting a voxel. We then build on our stacking models to introduce structured variance partitioning, a new type of variance partitioning that takes into account the known relationships between features. Our approach constrains the size of the hypothesis space and allows us to ask targeted questions about the similarity between feature spaces and brain regions even in the presence of correlations between the feature spaces. We validate our approach in simulation, showcase its brain mapping potential on fMRI data, and release a Python package. Our methods can be useful for researchers interested in aligning brain activity with different layers of a neural network, or with other types of correlated feature spaces.
journal bioRxiv github
Abstract:
Relating brain activity associated with a complex stimulus to different properties of that stimulus is a powerful approach for constructing functional brain maps. However, when stimuli are naturalistic, their properties are often correlated (e.g., visual and semantic features of natural images, or different layers of a convolutional neural network that are used as features of images). Correlated properties can act as confounders for each other and complicate the interpretability of brain maps, and can impact the robustness of statistical estimators. Here, we present an approach for brain mapping based on two proposed methods: stacking different encoding models and structured variance partitioning. Our stacking algorithm combines encoding models that each use as input a feature space that describes a different stimulus attribute. The algorithm learns to predict the activity of a voxel as a linear combination of the outputs of different encoding models. We show that the resulting combined model can predict held-out brain activity better or at least as well as the individual encoding models. Further, the weights of the linear combination are readily interpretable; they show the importance of each feature space for predicting a voxel. We then build on our stacking models to introduce structured variance partitioning, a new type of variance partitioning that takes into account the known relationships between features. Our approach constrains the size of the hypothesis space and allows us to ask targeted questions about the similarity between feature spaces and brain regions even in the presence of correlations between the feature spaces. We validate our approach in simulation, showcase its brain mapping potential on fMRI data, and release a Python package. Our methods can be useful for researchers interested in aligning brain activity with different layers of a neural network, or with other types of correlated feature spaces.
A. Luo, M. Henderson, L. Wehbe*, Michael J Tarr*.
Neural Information Processing Systems (NeurIPS), 2023. Chosen for oral presentation.
 paper
arXiv Abstract:
A long standing goal in neuroscience has been to elucidate the functional organization of the brain. Within higher visual cortex, functional accounts have remained relatively coarse, focusing on regions of interest (ROIs) and taking the form of selectivity for broad categories such as faces, places, bodies, food, or words. Because the identification of such ROIs has typically relied on manually assembled stimulus sets consisting of isolated objects in non-ecological contexts, exploring functional organization without robust a priori hypotheses has been challenging. To overcome these limitations, we introduce a data-driven approach in which we synthesize images predicted to activate a given brain region using paired natural images and fMRI recordings, bypassing the need for category-specific stimuli. Our approach -- Brain Diffusion for Visual Exploration ("BrainDiVE") -- builds on recent generative methods by combining large-scale diffusion models with brain-guided image synthesis. Validating our method, we demonstrate the ability to synthesize preferred images with appropriate semantic specificity for well-characterized category-selective ROIs. We then show that BrainDiVE can characterize differences between ROIs selective for the same high-level category. Finally we identify novel functional subdivisions within these ROIs, validated with behavioral data. These results advance our understanding of the fine-grained functional organization of human visual cortex, and provide well-specified constraints for further examination of cortical organization using hypothesis-driven methods.
paper
arXiv Abstract:
A long standing goal in neuroscience has been to elucidate the functional organization of the brain. Within higher visual cortex, functional accounts have remained relatively coarse, focusing on regions of interest (ROIs) and taking the form of selectivity for broad categories such as faces, places, bodies, food, or words. Because the identification of such ROIs has typically relied on manually assembled stimulus sets consisting of isolated objects in non-ecological contexts, exploring functional organization without robust a priori hypotheses has been challenging. To overcome these limitations, we introduce a data-driven approach in which we synthesize images predicted to activate a given brain region using paired natural images and fMRI recordings, bypassing the need for category-specific stimuli. Our approach -- Brain Diffusion for Visual Exploration ("BrainDiVE") -- builds on recent generative methods by combining large-scale diffusion models with brain-guided image synthesis. Validating our method, we demonstrate the ability to synthesize preferred images with appropriate semantic specificity for well-characterized category-selective ROIs. We then show that BrainDiVE can characterize differences between ROIs selective for the same high-level category. Finally we identify novel functional subdivisions within these ROIs, validated with behavioral data. These results advance our understanding of the fine-grained functional organization of human visual cortex, and provide well-specified constraints for further examination of cortical organization using hypothesis-driven methods.
J. Ye, J. Collinger, L. Wehbe, R. Gaunt.
Neural Information Processing Systems (NeurIPS), 2023.
 paper
bioRxiv code Abstract:
The neural population spiking activity recorded by intracortical brain-computer interfaces (iBCIs) contain rich structure. Current models of such spiking activity are largely prepared for individual experimental contexts, restricting data volume to that collectable within a single session and limiting the effectiveness of deep neural networks (DNNs). The purported challenge in aggregating neural spiking data is the pervasiveness of context-dependent shifts in the neural data distributions. However, large scale unsupervised pretraining by nature spans heterogeneous data, and has proven to be a fundamental recipe for successful representation learning across deep learning. We thus develop Neural Data Transformer 2 (NDT2), a spatiotemporal Transformer for neural spiking activity, and demonstrate that pretraining can leverage motor BCI datasets that span sessions, subjects, and experimental tasks. NDT2 enables rapid adaptation to novel contexts in downstream decoding tasks and opens the path to deployment of pretrained DNNs for iBCI control. Code: https://github.com/joel99/context_general_bci .
paper
bioRxiv code Abstract:
The neural population spiking activity recorded by intracortical brain-computer interfaces (iBCIs) contain rich structure. Current models of such spiking activity are largely prepared for individual experimental contexts, restricting data volume to that collectable within a single session and limiting the effectiveness of deep neural networks (DNNs). The purported challenge in aggregating neural spiking data is the pervasiveness of context-dependent shifts in the neural data distributions. However, large scale unsupervised pretraining by nature spans heterogeneous data, and has proven to be a fundamental recipe for successful representation learning across deep learning. We thus develop Neural Data Transformer 2 (NDT2), a spatiotemporal Transformer for neural spiking activity, and demonstrate that pretraining can leverage motor BCI datasets that span sessions, subjects, and experimental tasks. NDT2 enables rapid adaptation to novel contexts in downstream decoding tasks and opens the path to deployment of pretrained DNNs for iBCI control. Code: https://github.com/joel99/context_general_bci .
G. Sarch, M. Tarr, K. Fragkiadaki*, L. Wehbe*.
Neural Information Processing Systems (NeurIPS), 2023.
 paper
bioRxiv
paper
bioRxiv Abstract: The alignment between deep neural network (DNN) features and cortical responses currently provides the most accurate quantitative explanation for higher visual areas [1, 2, 3, 4]. At the same time, these model features have been critiqued as uninterpretable explanations, trading one black box (the human brain) for another (a neural network). In this paper, we train networks to directly predict, from scratch, brain responses to images from a large-scale dataset of natural scenes [5]. We then employ “network dissection” [6], a method used for enhancing neural network interpretability by identifying and localizing the most significant features in images for individual units of a trained network, and which has been used to study category selectivity in the human brain [7]. We adapt this approach to create a hypothesis-neutral model that is then used to explore the tuning properties of specific visual regions beyond category selectivity, which we call “brain dissection”. We use brain dissection to examine a range of ecologically important, intermediate properties, including depth, surface normals, curvature, and object relations and find consistent feature selectivity differences across sub-regions of the parietal, lateral, and ventral visual streams. For example, in the three scene-selective network we find that RSC prefers far depths and in-plane horizontal surface normals, while OPA and PPA prefer near and mid depths and vertical surface normals, indicating a change in the spatial coordinate system used for scene representations across RSC and OPA/PPA. Such findings contribute to a deeper, more fine-grained understanding of the functional characteristics of human visual cortex when viewing natural scenes. Project website: https://brain-dissection.github.io/.
A. Luo, M. Henderson, M. Tarr, L. Wehbe.
International Conference on Learning Representations (ICLR), 2024.
 paper
paper Abstract: Understanding the functional organization of higher visual cortex is a central focus in neuroscience. Past studies have primarily mapped the visual and semantic selectivity of neural populations using hand-selected stimuli, which may potentially bias results towards pre-existing hypotheses of visual cortex functionality. Moving beyond conventional approaches, we introduce a data-driven method that generates natural language descriptions for images predicted to maximally activate individual voxels of interest. Our method -- Semantic Captioning Using Brain Alignments ("BrainSCUBA") -- builds upon the rich embedding space learned by a contrastive vision-language model and utilizes a pre-trained large language model to generate interpretable captions. We validate our method through fine-grained voxel-level captioning across higher-order visual regions. We further perform text-conditioned image synthesis with the captions, and show that our images are semantically coherent and yield high predicted activations. Finally, to demonstrate how our method enables scientific discovery, we perform exploratory investigations on the distribution of "person" representations in the brain, and discover fine-grained semantic selectivity in body-selective areas. Unlike earlier studies that decode text, our method derives voxel-wise captions of semantic selectivity. Our results show that BrainSCUBA is a promising means for understanding functional preferences in the brain, and provides motivation for further hypothesis-driven investigation of visual cortex.
Y. Zhou, E. Liu, G. Neubig, M. Tarr, L. Wehbe.
Neural Information Processing Systems (NeurIPS), 2024.
 paper presentation arXiv
paper presentation arXiv Abstract: Do machines and humans process language in similar ways? Recent research has hinted at the affirmative, showing that human neural activity can be effectively predicted using the internal representations of language models (LMs). Although such results are thought to reflect shared computational principles between LMs and human brains, there are also clear differences in how LMs and humans represent and use language. In this work, we systematically explore the divergences between human and machine language processing by examining the differences between LM representations and human brain responses to language as measured by Magnetoencephalography (MEG) across two datasets in which subjects read and listened to narrative stories. Using an LLM-based data-driven approach, we identify two domains that LMs do not capture well: social/emotional intelligence and physical commonsense. We validate these findings with human behavioral experiments and hypothesize that the gap is due to insufficient representations of social/emotional and physical knowledge in LMs. Our results show that fine-tuning LMs on these domains can improve their alignment with human brain responses.
A. Luo, J. Yeung, R. Zawar, S. Dewan, M. Henderson, L. Wehbe*, M. Tarr*.
International Conference on Learning Representations (ICLR), 2025.
 paper
paper Abstract: We introduce BrainSAIL (Semantic Attribution and Image Localization), a method for linking neural selectivity with spatially distributed semantic visual concepts in natural scenes. BrainSAIL leverages recent advances in large-scale artificial neural networks, using them to provide insights into the functional topology of the brain. To overcome the challenge presented by the co-occurrence of multiple categories in natural images, BrainSAIL exploits semantically consistent, dense spatial features from pre-trained vision models, building upon their demonstrated ability to robustly predict neural activity. This method derives clean, spatially dense embeddings without requiring any additional training, and employs a novel denoising process that leverages the semantic consistency of images under random augmentations. By unifying the space of whole-image embeddings and dense visual features and then applying voxel-wise encoding models to these features, we enable the identification of specific subregions of each image which drive selectivity patterns in different areas of the higher visual cortex. This provides a powerful tool for dissecting the neural mechanisms that underlie semantic visual processing for natural images. We validate BrainSAIL on cortical regions with known category selectivity, demonstrating its ability to accurately localize and disentangle selectivity to diverse visual concepts. Next, we demonstrate BrainSAIL's ability to characterize high-level visual selectivity to scene properties and low-level visual features such as depth, luminance, and saturation, providing insights into the encoding of complex visual information. Finally, we use BrainSAIL to directly compare the feature selectivity of different brain encoding models across different regions of interest in visual cortex. Our innovative method paves the way for significant advances in mapping and decomposing high-level visual representations in the human brain.
M. Henderson, M. Tarr, L. Wehbe.
Trends in Neurosciences, 2025.
 journal
journal Abstract: Several recent studies, enabled by advances in neuroimaging methods and large-scale datasets, have identified areas in human ventral visual cortex that respond more strongly to food images than to images of many other categories, adding to our knowledge about the broad network of regions that are responsive to food. This finding raises important questions about the evolutionary and developmental origins of a possible food-selective neural population, as well as larger questions about the origins of category-selective neural populations more generally. Here, we propose a framework for how visual properties of food (particularly color) and nonvisual signals associated with multimodal reward processing, social cognition, and physical interactions with food may, in combination, contribute to the emergence of food selectivity. We discuss recent research that sheds light on each of these factors, alongside a broader account of category selectivity that incorporates both visual feature statistics and behavioral relevance.