Jaspreet Bhatia
jbhatia@cs.cmu.edu
4208 Wean Hall, Carnegie Mellon University

|
Semantic Incompleteness in Privacy Goals [Paper] This work is supported by NSF Frontier Award #1330596 and NSF CAREER Award #1453139. |

|
Privacy Goal Mining [Paper] This work is supported by NSF Frontier Award #1330596. For more details about this project, please visit our Usable Privacy Project Website. |
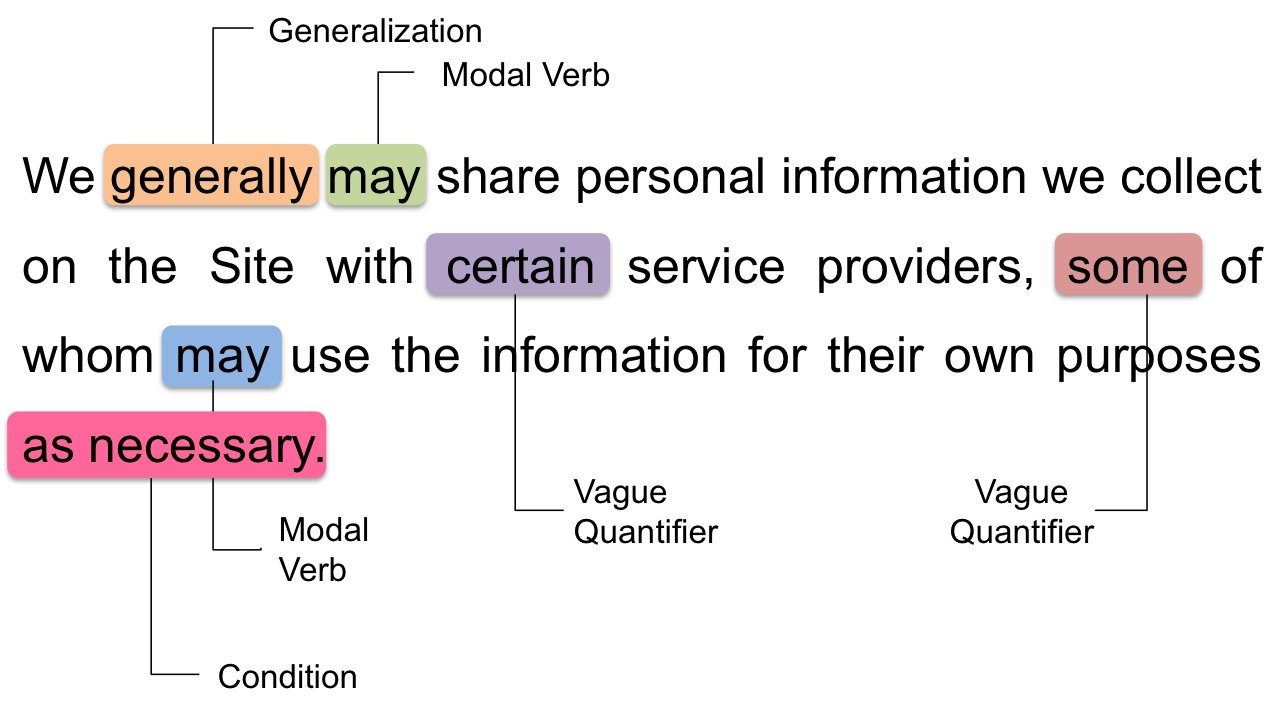
|
Vagueness in Privacy Policies [Paper] This work is supported by NSF Award #1330596, NSF Award #1330214 and NSA Award #141333. |

|
Empirical Measurement of Perceived Privacy Risk [Paper] This work is supported by NSF Award CNS‐1330596, NSA Award #141333, and ONR Award #N00244‐16‐1‐0006 |