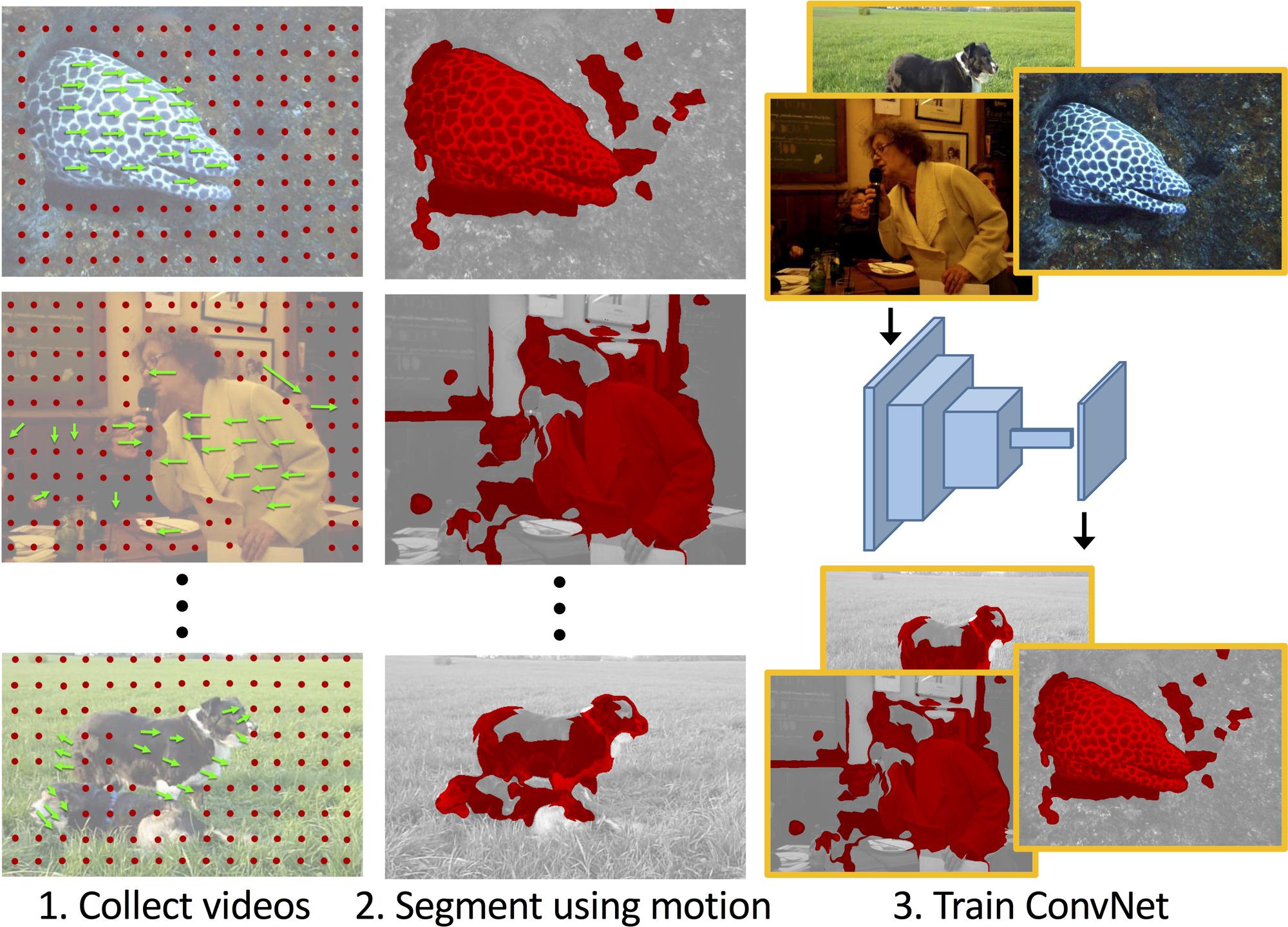
|
|
|
|
|
|
Bharath Hariharan |
|
|
|
|
|
Unsupervised Learning [GitHub] |
uNLC Code [GitHub] |
Python Optical Flow [GitHub] |
|
README [click here] |
Video Frames [Download Tar 45GB] |
Unsupervised Segments [Download Tar 22GB] |
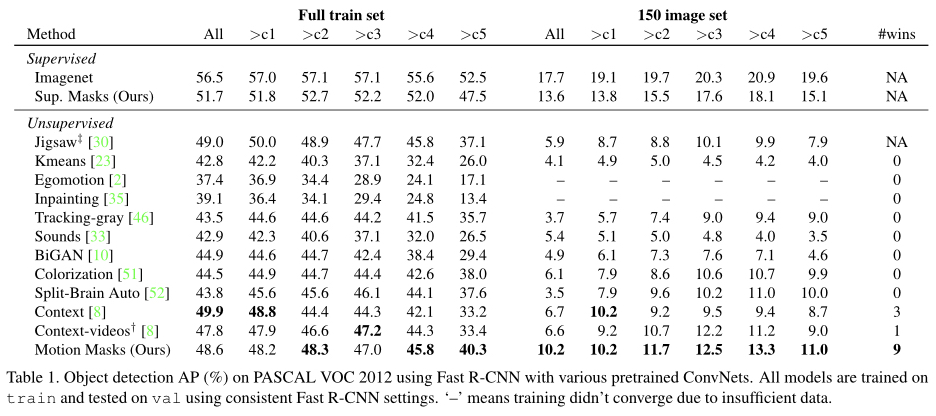 |
 |
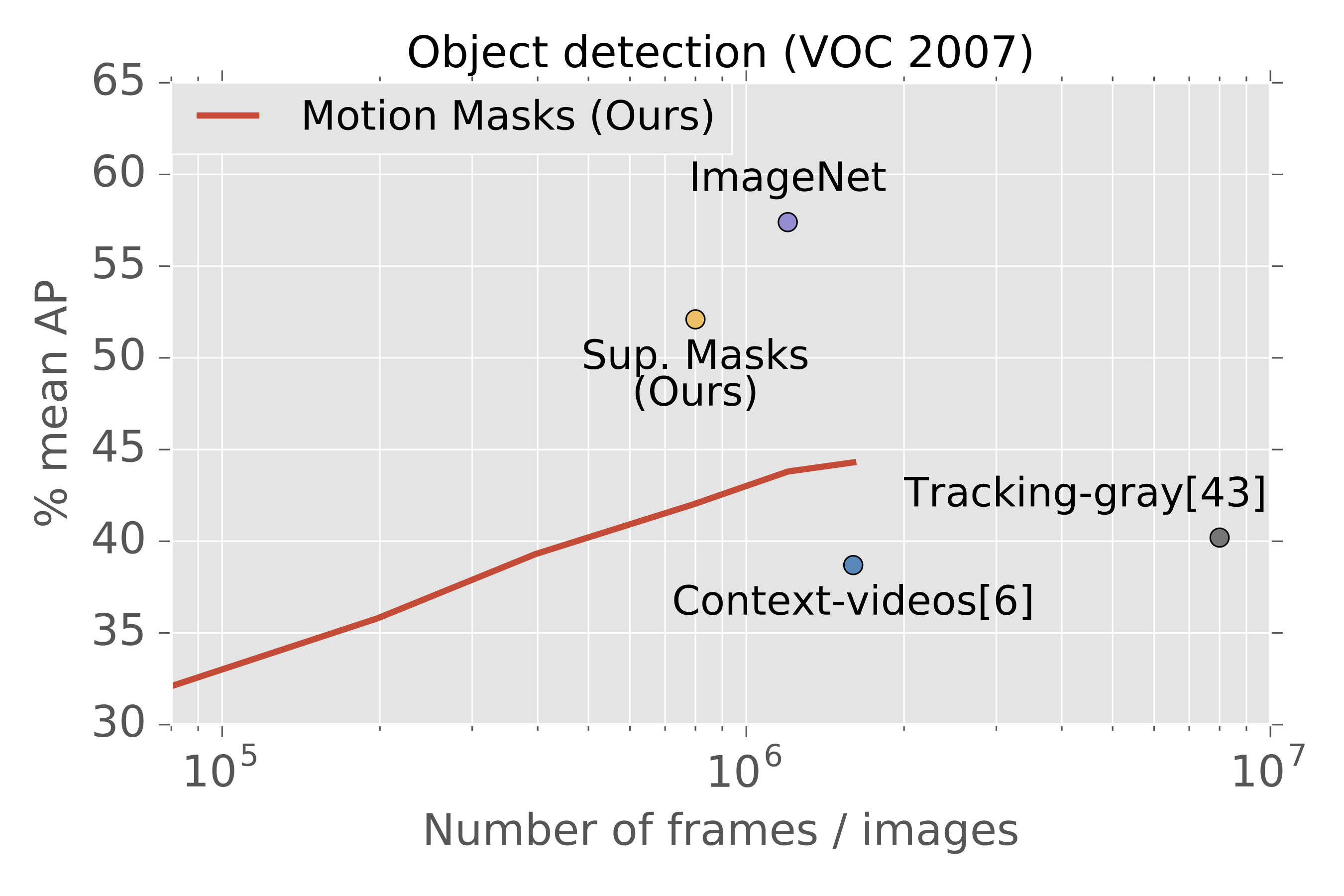 |

|
Citation |
|
@inproceedings{pathakCVPR17learning,
Author = {Pathak, Deepak and
Girshick, Ross and
Doll{\'a}r, Piotr and
Darrell, Trevor and
Hariharan, Bharath},
Title = {Learning Features
by Watching Objects Move},
Booktitle = {CVPR},
Year = {2017}
}
|
Acknowledgements |