The policy iteration algorithm manipulates the policy directly, rather than finding it indirectly via the optimal value function. It operates as follows:
choose an arbitrary policy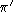
loop
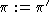
compute the value function of policy
:
solve the linear equations
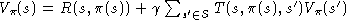
improve the policy at each state:

until
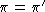
The value function of a policy is just the expected infinite discounted reward that will be gained, at each state, by executing that policy. It can be determined by solving a set of linear equations. Once we know the value of each state under the current policy, we consider whether the value could be improved by changing the first action taken. If it can, we change the policy to take the new action whenever it is in that situation. This step is guaranteed to strictly improve the performance of the policy. When no improvements are possible, then the policy is guaranteed to be optimal.
Since there are at most ![]() distinct policies,
and the sequence of policies improves at each step, this algorithm
terminates in at most an exponential number of
iterations [90]. However, it is an important open
question how many iterations policy iteration takes in the worst case.
It is known that the running time is pseudopolynomial and that for any
fixed discount factor, there is a polynomial bound in the total size
of the MDP [66].
distinct policies,
and the sequence of policies improves at each step, this algorithm
terminates in at most an exponential number of
iterations [90]. However, it is an important open
question how many iterations policy iteration takes in the worst case.
It is known that the running time is pseudopolynomial and that for any
fixed discount factor, there is a polynomial bound in the total size
of the MDP [66].