One way, then, to find an optimal policy is to find the optimal value
function. It can be determined by a simple iterative algorithm
called value iteration that can be shown to converge to the correct
![]() values [10, 13].
values [10, 13].
initialize V(s) arbitrarilyloop until policy good enough
loop for

loop for
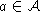

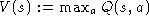
end loop
end loop
It is not obvious when to stop the value iteration algorithm. One
important result bounds the performance of the current greedy policy
as a function of the Bellman residual of the current value
function [134]. It says that if the maximum difference
between two successive value functions is less than ![]() , then
the value of the greedy policy, (the policy obtained by choosing, in
every state, the action that maximizes the estimated discounted
reward, using the current estimate of the value function) differs from
the value function of the optimal policy by no more than
, then
the value of the greedy policy, (the policy obtained by choosing, in
every state, the action that maximizes the estimated discounted
reward, using the current estimate of the value function) differs from
the value function of the optimal policy by no more than ![]() at any state. This provides an effective stopping
criterion for the algorithm. Puterman [90] discusses
another stopping criterion, based on the span semi-norm, which
may result in earlier termination. Another important result is that
the greedy policy is guaranteed to be optimal in some finite number of
steps even though the value function may not have
converged [13]. And in practice, the greedy policy is
often optimal long before the value function has converged.
at any state. This provides an effective stopping
criterion for the algorithm. Puterman [90] discusses
another stopping criterion, based on the span semi-norm, which
may result in earlier termination. Another important result is that
the greedy policy is guaranteed to be optimal in some finite number of
steps even though the value function may not have
converged [13]. And in practice, the greedy policy is
often optimal long before the value function has converged.
Value iteration is very flexible. The assignments to V need not be done in strict order as shown above, but instead can occur asynchronously in parallel provided that the value of every state gets updated infinitely often on an infinite run. These issues are treated extensively by Bertsekas [16], who also proves convergence results.
Updates based on Equation 1 are known as full backups since they make use of information from all possible successor states. It can be shown that updates of the form
![]()
can also be used as long as each pairing of a and s is updated
infinitely often, s' is sampled from the distribution T(s,a,s'),
r is sampled with mean R(s,a) and bounded variance, and the
learning rate ![]() is decreased slowly. This type of sample
backup [111] is critical to the operation of the model-free
methods discussed in the next section.
is decreased slowly. This type of sample
backup [111] is critical to the operation of the model-free
methods discussed in the next section.
The computational complexity of the value-iteration algorithm with
full backups, per iteration, is quadratic in the number of states and
linear in the number of actions. Commonly, the transition
probabilities T(s,a,s') are sparse. If there are on average a
constant number of next states with non-zero probability then the cost
per iteration is linear in the number of states and linear in the
number of actions. The number of iterations required to reach the
optimal value function is polynomial in the number of states and the
magnitude of the largest reward if the discount factor is held
constant. However, in the worst case the number of iterations grows
polynomially in ![]() , so the convergence rate slows
considerably as the discount factor approaches 1 [66].
, so the convergence rate slows
considerably as the discount factor approaches 1 [66].