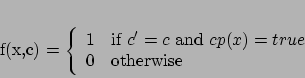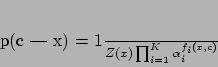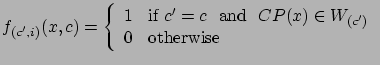Next: Description of Features Up: WSD Methods Previous: Comparison with Knowledge-based Methods
Maximum Entropy modeling provides a framework for integrating information for classification from many heterogeneous information sources manning99foundations,berger96. ME probability models have been successfully applied to some NLP tasks, such as POS tagging or sentence-boundary detection Ratnaparkhi1998.
The WSD method used in this work is based on conditional ME models. It has been implemented using a supervised learning method that consists of building word-sense classifiers using a semantically annotated corpus. A classifier obtained by means of an ME technique consists of a set of parameters or coefficients which are estimated using an optimization procedure. Each coefficient is associated with one feature observed in the training data. The goal is to obtain the probability distribution that maximizes the entropy--that is, maximum ignorance is assumed and nothing apart from the training data is considered. One advantage of using the ME framework is that even knowledge-poor features may be applied accurately; the ME framework thus allows a virtually unrestricted ability to represent problem-specific knowledge in the form of features Ratnaparkhi1998.
Let us assume a set of contexts ![]() and a set of classes
and a set of classes ![]() . The
function
. The
function
![]() chooses the class
chooses the class ![]() with the
highest conditional probability in the context
with the
highest conditional probability in the context ![]() :
:
![]() . Each feature is calculated by a function
that is associated with a specific class
. Each feature is calculated by a function
that is associated with a specific class ![]() , and it takes the
form of equation (2), where
, and it takes the
form of equation (2), where ![]() represents some
observable characteristic in the context4. The
conditional probability
represents some
observable characteristic in the context4. The
conditional probability ![]() is defined by equation
(3), where
is defined by equation
(3), where ![]() is the parameter or weight
of the feature
is the parameter or weight
of the feature ![]() ,
, ![]() is the number of features defined, and
is the number of features defined, and
![]() is a normalization factor that ensures that the sum of all
conditional probabilities for this context is equal to 1.
is a normalization factor that ensures that the sum of all
conditional probabilities for this context is equal to 1.
The learning module produces the classifiers for each word using a corpus that is syntactically and semantically annotated. The module processes the learning corpus in order to define the functions that will apprise the linguistic features of each context.
For example, consider that we want to build a classifier for the noun interest using the POS label of the previous word as a feature and we also have the the following three examples from the training corpus:

The learning module performs a sequential processing of this
corpus, looking for the pairs ![]() POS-label, sense
POS-label, sense![]() . Then, the
following pairs are used to define three functions (each context
has a vector composed of three features).
. Then, the
following pairs are used to define three functions (each context
has a vector composed of three features).
adjective,#1
We can define another type of feature by merging the POS occurrences by sense:
adjective,verb},#1
This form of defining the pairs means a reduction of feature space because all information (of some kind of linguistic data, e.g., POS label at position -1) about a sense is contained in just one feature. Obviously, the form of the feature function 2 must be adapted to Equation 4. Thus,
We will refer to the feature function expressed by Equation 4 as ``collapsed features''. The previous Equation 2 we call ``non-collapsed features''. These two feature definitions are complementary and can be used together in the learning phase.
Due to the nature of the disambiguation task, the number of times that a feature generated by the first type of function (``non-collapsed'') is activated is very low, and the feature vectors have a large number of null values. The new function drastically reduces the number of features, with a minimal degradation in the evaluation results. In this way, more and new features can be incorporated into the learning process, compensating the loss of accuracy.
Therefore, the classification module carries out the disambiguation of new contexts using the previously stored classification functions. When ME does not have enough information about a specific context, several senses may achieve the same maximum probability and thus the classification cannot be done properly. In these cases, the most frequent sense in the corpus is assigned. However, this heuristic is only necessary for a minimum number of contexts or when the set of linguistic attributes processed is very small.