Freund and Shapire [1996] suggested that the sometimes poor performance of Boosting results from overfitting the training set since later training sets may be over-emphasizing examples that are noise (thus creating extremely poor classifiers). This argument seems especially pertinent to Boosting for two reasons. The first and most obvious reason is that their method for updating the probabilities may be over-emphasizing noisy examples. The second reason is that the classifiers are combined using weighted voting. Previous work [Sollich Krogh1996] has shown that optimizing the combining weights can lead to overfitting while an unweighted voting scheme is generally resilient to overfitting. Friedman et al. [ 1998] hypothesize that Boosting methods, as additive models, may see increases in error in those situations where the bias of the base classifier is appropriate for the problem being learned. We test this hypothesis in our second set of results presented in this section.
To evaluate the hypothesis that Boosting may be prone to overfitting we
performed a set of experiments using the four ensemble neural network methods.
We introduced 5%, 10%, 20%, and 30% noise2 into four different
data sets.
At each level we created five different noisy data sets,
performed a 10-fold cross validation on each, then averaged
over the five results.
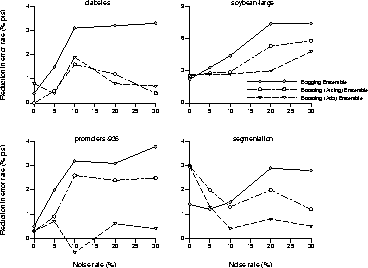
In Figure 10 we show the reduction in error
rate for each of the ensemble methods compared to using a single
neural network classifier.
These results demonstrate that as the noise level grows, the
efficacy of the Simple and Bagging ensembles generally increases while
the Arcing and Ada-Boosting ensembles gains in performance are much smaller (or may
actually decrease).
Note that this effect is more extreme for Ada-Boosting which supports our
hypothesis that Ada-Boosting is more affected by noise.
This suggests that Boosting's poor performance for certain data sets
may be partially explained by overfitting noise.
 |
To further demonstrate the effect of noise on Boosting we created several sets of
artificial data specifically designed to mislead Boosting methods.
For each data set we created a simple hyperplane concept based on a set of
the features (and also included some irrelevant features).
A set of random points were then generated and labeled based on which side
of the hyperplane they fell.
Then a certain percentage of the points on one side of the hyperplane were
mislabeled as being part of the other class.
For the experiments shown below we generated five data sets where the concept
was based on two linear features, had four irrelevant features, and
20% of the data was mislabeled.
We trained five ensembles of neural networks (perceptrons) for each data set
and averaged the ensembles' predictions.
Thus these experiments involve learning in situations where the
original bias of the learner (a single hyperplane produced by a
perceptron) is appropriate for the problem, and as Friedman et al.
[1998] suggest, using an additive model may harm performance.
Figure 11 shows the resulting error rates
for Ada-Boosting, Arcing, and Bagging by the number of networks
being combined in the ensemble.
 |
This conclusion dovetails nicely with Schapire et al.'s [1997] recent discussion where they note that the effectiveness of a voting method can be measured by examining the margins of the examples. (The margin is the difference between the number of correct and incorrect votes for an example.) In a simple resampling method such as Bagging, each resulting classifier focuses on increasing the margin for as many of the examples as possible. But in a Boosting method, later classifiers focus on increasing the margins for examples with poor current margins. As Schapire et al. [1997] note, this is a very effective strategy if the overall accuracy of the resulting classifier does not drop significantly. For a problem with noise, focusing on misclassified examples may cause a classifier to focus on boosting the margins of (noisy) examples that would in fact be misleading in overall classification.