A Tour-Giving Learning Robot that Follows People
Daniel Nikovski, Dimitris Margaritis, and Roseli Romero
Tracking and following the movement of people is a basic capability in
human-robot interaction. The general problem of tracking an object is
known to be difficult and usually features that are particular to the
object are hard-coded in the recognition system to make operation
robust. The specific problem we are addressing -- learning to
recognize and follow a particular person -- is even harder, because
those features cannot be hard-coded and have to be extracted
autonomously.
Robots that give tours in museums presently move on a prespecified
route and people that want to take the tour have to follow them, even
if they want to take a different route. We are trying to build a
system that will let the robot follow a person and adjust its
narrative accordingly. This would make the behavior of the robot
appear more intelligent and flexible and would give more freedom and
convenience to museum visitors.
People following is a relatively complex behavior that relies on
several faculties of lower level: motion estimation, feature tracking,
face detection, sensor fusion, reasoning under uncertainty,
navigation, and obstacle avoidance. Previous approaches have used
different methods for providing these capabilities and integrating
them into a whole system.
The most common techniques used to track people are motion and face
detection. Motion estimation can be done by spatio-temporal filtering
and/or background subtraction, as reported by McKenna. Face detection
is commonly done with a neural network or some other pattern
recognizer; many successful systems have been reported, but a face
tracker is of very limited use if the robot will be following people
and rarely seeing their faces.
Other approaches to people tracking include detecting the color of
people's clothing, or attaching bar codes to them, as reported by
Kortenkamp. Azarbayejani and Pentland proposed a method for 3D
recovery of people's motion by means of connecting blobs of pixels of
the same color. Flinchbaugh introduces a motion graph to describe the
significant events caused by moving people in a scene. Dean et
al. used a temporal Bayesian network on a mobile robot to track
people; however, this system was not adaptive to a particular person.
We also use a temporal Bayesian network for reasoning and sensor
fusion under uncertainty. Sonar and visual input are integrated over
multiple time slices in a probabilistic framework. The two sensor
modalities complement each other in order to detect reliably a person
around the robot. Sonar detection is not specific to the person that
has to be tracked and in general has low predictive likelihood. As a
result, the robot often confuses people with chairs and other objects
of similar shape and size. Visual recognition, on the other hand, is
much more reliable and can be tuned to detect only the particular
person that has to be followed [1]. However, the field of view of the
camera is only about a sixth of the space surrounding the robot, while
the sonar detector spans all of it. By combining the two sensors, we
hope to be able to use the sonar for an initial estimate of the
location of the person and the camera for precise verification. In
addition, we plan to use other modalities such as hearing the sound of
clapping hands or whistling, etc.
The sonar detector is designed by hand and uses hard-coded rules
to decide if a person is present around the robot by analyzing
the edges in the sonar image and estimating the size of the
corresponding objects. The predictive likelihood of the detector
has been determined from experimental data and entered into
a temporal Bayesian network.
The visual detector, which is still under development, uses a decision
tree to determine if a person is present in the visual field of the
robot. The input to the decision tree consists of color histograms of
blocks of the image, properly labeled as positive and negative
examples. We are currently working on a method for autonomous labeling
of the data, based on silhouette detection from the optical flow in
the sequence of images. If successful, people would be able to
``introduce themselves'' to the robot before they start the tour,
so that the robot can follow exactly them and not other visitors.
We are still in the experimental stage, trying to put together a
system that uses sonars and vision. If successful, we will add other
sensors and new detectors. Another direction is to implement a general
system for reasoning in temporal Bayesian networks, which can model
conditional dependencies between readings, broken sensors, and
intermediate diagnostic states. Learning better state evolution
models from experience is another topic we are exploring
[2]. Yet another very interesting problem is the autonomous
construction of temporal Bayesian networks from sensory data -- not
only adjusting probability tables, but also inferring the structure of
the network. If a robot can do this on its own, it would be able to
build an optimal representation of the problem domain, adapted to the
tasks it has to solve.
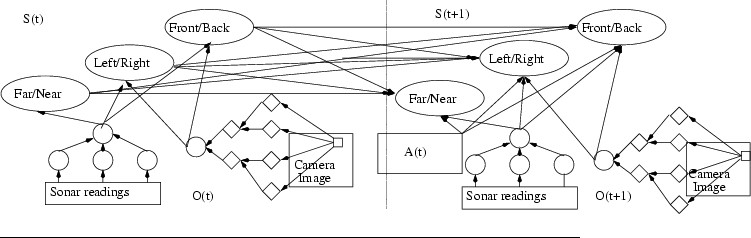
Figure:
A temporal Bayesian network is used for reasoning under uncertaintly
about the position of the person being tracked. The network has to
time slices with identical structure, and an action node A(t). Each
time slice has state nodes, which represent the position of the person
with respect to the robot in a distributed manner -- as beliefs over
truth assignments to the propositions with states True/Far,
Left/Right, Front/Back. Evidence for the truth of each of these
propositions comes from detectors that monitor sonar and visual data.
The sonar detector is a hand-coded decision routine that analyzes
sonar readings, while the visual detector is a decision tree that is
built adaptively from training data extracted from color histograms of
subimages that are taken from a picture of the person to be followed.
 |
- 1
-
Dimitris Margaritis and Sebastian Thrun.
Learning to locate an object in 3d space from a sequence of images.
1998.
Submitted to ICML'98.
- 2
-
Daniel Nikovski.
Learning stationary temporal probabilistic networks.
1998.
Accepted at CONALD'98.
This document was generated using the
LaTeX2HTML translator Version 98.1p1 release (March 2nd, 1998).
The translation was performed on 1998-04-19.