TL;DR
Some organizations and people are inaccurately labeling their systems as "self-driving". A true self-driving DBMS automatically (1) decides what actions to use to optimize itself, (2) decides when to deploy those actions, and (3) learns from those actions — all without any human intervention.People are always leaving me in my life. One may think that it is just the life of a professor where students graduate and go off to have great careers. But it has been happening to me well before I started at CMU. One good example of this was when I was taking my required physical education class as an undergraduate. I decided to expand my horizon and sign up for Massage: Holistic Therapy. Since I wanted to avoid massaging somebody that was the embodiment of RIT's notable lax male hygiene standards, I purposely showed up five minutes late so that I could choose who I sat next to. I did this because I knew that people would partner with whom ever was closest to them. I don't remember the name of the girl that I partnered with, but she was friendly and seemed to have a habit of showering daily. Over the next 10 weeks, we massaged each other in a strictly educational manner. But then one day she stopped coming to class[1] and I had to massage sweaty men.
These painful memories have returned because my machine learning (ML) friends keep leaving CMU. First it was the venerable Alex Smola leaving for Amazon. Now it is the buttery Geoff Gordon leaving for Microsoft Research. I enjoyed collaborating with Alex and Geoff, and their departure burns like that time I drank a half gallon of milk while eating hot steamed crabs. Nevertheless, my DB squad is moving forward.
The reason I bring this up is because ML for databases is a hot research topic. Not just for my group, but in industry as well. And I don't mean running TensorFlow inside of the DBMS to access the database more quickly. Rather, I mean using ML to automate a DBMS's run time operations and physical design. I have called this new class of research self-driving databases[2]. This has been the focal point of my research on the Peloton DBMS for the last two years. Others have applied (incorrectly, in my opinion) this term to their own work or systems.
Thus, in this article, I provide my definition of a self-driving DBMS. To properly contrast this new work with previous efforts, I begin by discussing the last 40 years of research on autonomous database systems.
Self-Adaptive Databases (1970-1990s)
The idea of using a DBMS to remove the burden of data management from application developers was one of the original selling points of the relational model and declarative programming languages (e.g., SQL) from the 1970s. With this approach, a developer only writes a query that specifies what data they want to access. It is then up to the DBMS to find the most efficient way to execute that query; the developer does not worry about what algorithm to use, how to store and retrieve data, or how to safely interleave operations that update data. The DBMS knows the most about the database and how it is accessed, so therefore it is always in the best position to make these decisions.
In this same vein, organizations ideally want a DBMS to pick an overall strategy for their application that handles all aspects of managing and optimizing their database. These were called self-adaptive systems in the 1970s. The high-level idea of how these early systems worked is essentially how modern tools work today: (1) the system collects metrics on how the application accesses data and then (2) it searches for what change to make to improve performance based on a cost model.
The early self-adaptive DBMSs focused on physical database design, in particular index selection. In fact, my advisor's advisor wrote one of the first papers on automatic index selection in 1976. Others working on this problem at this time include IBM, Berkeley, and CMU. This trend continued into the 1980s (e.g., IBM's DBDSGN project for System R).
In addition to index selection, the other widely studied database design problem was database partitioning. Again, my adviser's adviser wrote one of the first papers on this topic in 1979. The need for automatic database partitioning and data placement methods became more prevalent in the 1990s with the rise of distributed / parallel DBMSs. The key papers on this topic were from (1) DeWitt's group at Wisconsin and (2) Toronto/IBM.
Self-Tuning Databases (1990s-2000s)
I consider the late 1990s and the 2000s as the "golden era" of autonomous DBMSs. This was the second wave of research on what became called "self-tuning" (also "auto-tuning") database systems. At the forefront of this movement was the seminal work at Microsoft Research with the AutoAdmin project. They built advisor tools that helped the DBA select the optimal indexes, materialized views, and partitioning schemes for their workload. The key contribution from AutoAdmin was the development of the what-if API. With this, the tuning tools create virtual catalog entries for potential design decisions (e.g., an index to add) and then use the query optimizer's cost model to determine the benefit of that decision. In other words, you tell the optimizer that the database has an index even though it really does not, and then see if the optimizer selects that index for each query to determine whether adding that index is a good idea. This allows the tools to use the existing DBMS's cost model estimates rather than having to create a second external (and therefore likely inaccurate) cost model to make design decisions. The other major database vendors had similar self-tuning physical design projects (e.g., IBM's DB2 Designer), but Microsoft was the most prolific.
The 2000s also saw the beginning of research on automating knob configuration. Such knobs allow the DBA to control various aspects of the DBMS's run-time behavior. For example, they can set how much memory the system allocates for data caching versus the transaction log buffer. Unlike physical design tools, configuration tools cannot use the built-in cost models of query optimizers. This is because these models generate estimates on the amount of work to execute a particular query and are intended to compare alternative query execution strategies in a fixed execution environment.
All of the major DBMS vendors have their own proprietary knob tuning tools that vary in the amount of automation that they support. In the early 2000s, IBM released the DB2 Performance Wizard that asks the DBA questions about their application (e.g., whether it is OLTP or OLAP) and then provides knob settings based on their answers. IBM later released a version of DB2 with a self-tuning memory manager that uses heuristics to determine how to allocate the DBMS's memory to its internal components. Oracle developed a similar system to identify bottlenecks due to misconfiguration. Later versions of Oracle include a SQL analyzer tool that estimates the impact of configuration modifications. This approach has also been used with Microsoft SQL Server.
Using all of the above tools is still a manual process: the DBA provides a sample workload and then the tool suggests one or more actions to improve performance. It is still up to the DBA to decide whether those suggestions are correct and when to deploy them. IBM recognized that requiring a human expert to make these final decisions was problematic, thus they launched an initiative on building autonomic components for DB2. The most well-known of these were the LEarning Optimizer (LEO) and Self-Adaptive Set of Histograms (SASH). The basic idea is simple: the DBMS's cost model makes estimations when selecting a query plan based on statistics that it collects. Then as the system executes the query, it checks whether those estimates match with the real data. If not, then the system has a feedback loop mechanism to provide the cost model with corrections. This seems like exactly what one would want in a system, but I have yet to meet any DB2 DBA that says that it worked as advertised. I have been told by at least three DBAs that they always turn off this feature whenever they first deployed a new DB2 database[3].
The idea of removing the need for humans has also been explored for some aspects of physical design. Most notable is the great database cracking work from Stratos Ideros.
Cloud Databases (early 2010s)
The next chapter in autonomous systems came about with the rise of cloud computing. Automation is more necessary in such cloud platforms because of their scale and complexity. All of the cloud providers use custom tools to control deployments at the operator-level (e.g., tenant placement). Microsoft appears to be again leading research in this area. Their Azure service models resource utilization of DBMS containers from internal telemetry data and automatically adjusts allocations to meet QoS and budget constraints. I have not seen or heard of anything with the same level of sophistication from the other cloud database vendors.
There are also controllers for applications to perform black-box provisioning in the cloud. Others have employed using the same receding-horizon controller model that is used in self-driving vehicles, but they only perform modify the number of machines used in the cluster.
Running in the cloud provides a unique operating environment that the previous research efforts did not have to consider. Since compute and storage resources are now "infinite", the DBMS can in theory scale up/down and in/out almost instantly. Contrast this with a traditional on-premise deployment, where provisioning a new machine can take weeks or even months. I think that the dominant trend in future distributed DBMS design will be shared-disk architectures. Decoupling the compute nodes from the storage allows for interesting design choices that are not easily done in a shared-nothing architecture. Amazon, Google, Microsoft, and Snowflake will be leaders this pushing this model for cloud DBMSs in new and interesting ways[4]. The cloud providers will be at the forefront of this because they control the whole stack. That means that they can push DBMS-specific logic up into the networking layer and down in the storage layer in ways that vendors that simply run inside of their platform are not able to do. For example, Amazon Aurora embeds logic about transaction writes into the EBS storage layer.
Self-Driving Databases (late 2010s)
Self-driving cars are a hot area. There are several start-ups in Pittsburgh working on this problem with crazy valuations. That of course means that there is a lot of hype. People are applying the term "self-driving" to other things. I'm of course guilty doing this for databases. But while there is an established definition for what it means to have a self-driving automobile, there is not an equivalent for DBMSs.
In my opinion, there are three things that DBMS must support to be considered completely self-driving:
- The ability to automatically select actions to improve some objective function (e.g., throughput, latency, cost). This selection also includes how many resources to use to apply an action.
- The ability to automatically choose when to apply an action.
- The ability to automatically learn from its actions and refine its decision making process.
An action in this context is a change to the DBMS in one of the following three categories: (1) a change to the database's physical design (e.g., add/drop an index), (2) a change to the DBMS's knob configuration (e.g., allocate more/less memory to the DBMS's log buffer), or (3) a change to the DBMS's physical resources (e.g., add/remove a node in the cluster). The problem choosing how to apply an action is part of the action selection process. For example, the DBMS could choose to build a new index using one thread if resources are limited, or it could choose to use four threads if it needs to build that index more quickly.
You should now understand why I started off with the history of the research on autonomous databases. With a few exceptions, all of the previous work is focused on solving the first problem. There are a few tools that attempt to solve part of the second problem and to the best of my knowledge nobody has solved the last one. But these are what make a self-driving DBMS difficult. The DBMS must know when it should do deploy an action and whether that action helped. This is more than identifying that Sunday morning is when demand is low so therefore the system can optimize itself more aggressively. The system must have a sense of what the workload will look like in the future and plan accordingly. Without this forecasting, the DBMS is equivalent to a self-driving car that is only able to view the road behind it. The car can see all of the children that it ran over in the past but it is not able to predict the future children and avoid them in the road ahead.
What makes these forecasts a challenging problem is that the environment is always changing. The hardware can change based on action. The workload can change based on the time of the day, day of the week, or month of year. The queries' resource usage can change based on the physical database design. My convivial Ph.D. student Lin Ma has published a SIGMOD'18 paper on how to forecast workloads independently of these issues in a self-driving DBMS. His new forecasting framework, called the QueryBot 5000, clusters queries based on their arrival rates (instead of physical resources or logical SQL features). It then uses a ensemble of recurrent neural networks, linear regression, and kernel regression to generate forecasts at different horizons (e.g., 10 minutes, 1 hour, 1 day) and different intervals (e.g., every minute, every 10 minutes). This is the first important step in our effort to build a true self-driving DBMS.
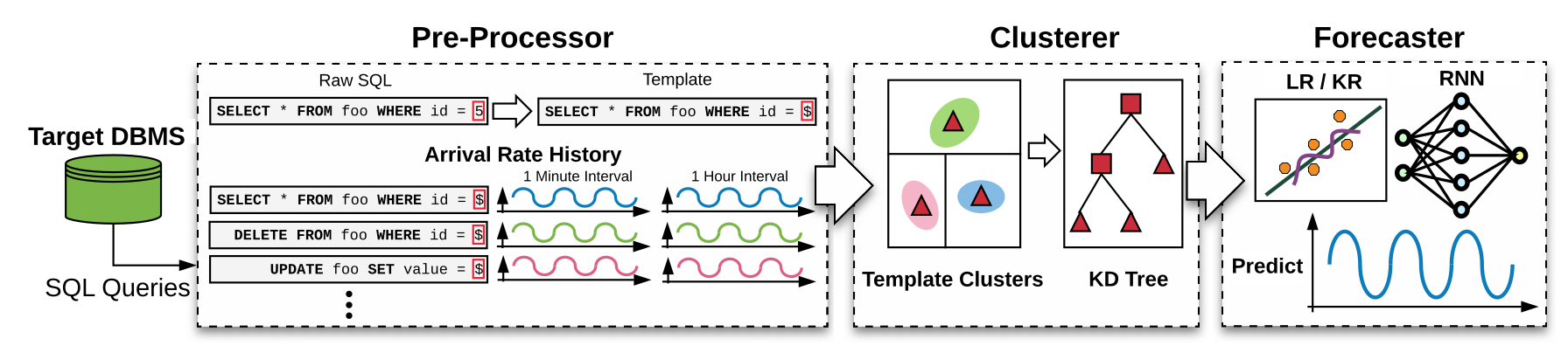
Our next step is to build the reinforcement learning (RL) models that can use the QueryBot 5000's forecasts to select useful actions. The hard research problem is how to observe the benefit of an action. Again, the environment is always changing so we have to figure out how to isolate that variability from our observation.
Oracle Self-Driving Database
Now you may be wondering about Oracle's announcement in September 2017 that they have the world's first self-driving DBMS. From what I can tell from watching their marketing videos, talking with people in the know, and reading early evaluations, it looks that Oracle's self-driving offering uses their existing deployment and tuning tools that they developed in the previous two decades. In other words, they are hosting databases with their existing cloud DBMS and self-tuning tools; the end user does not have to run these tools manually. For example, they automate provisioning by scaling out the DBMS. This is triggered when the system fails to meet SLAs and thus is likely based on rules and heuristics (i.e., "if performance below some threshold, then add a new node").
Oracle's "self-driving" DBMS in 2018 is similar to IBM's proof-of-concept for DB2 from 2008. Similar to how I think Oracle's system works, IBM's system used DB2's existing tools in an external controller and monitor that triggered a change whenever a resource threshold was surpassed (e.g., the number of deadlocks). This prototype still required a human DBA to select tuning optimizations and to occasionally restart the DBMS. So Oracle's DBMS is more sophisticated in that regard, but both systems still only react to problems after they occur because they lack forecasting.
Oracle touts that their autonomous data warehouse is able to perform automatic query tuning and optimization (skip to 1:15). This is Oracle's new adaptive query optimization feature. The gist of how this works is that the DBMS generates a new query plan during execution if it notices that the real data does not match its estimates. This is method is a combination of (1) IBM's LEO where the DBMS can update the optimizer with observed statistics during query execution and (2) INGRES' adaptive query processing technique from the 1970s. Oracle is not the only system that supports this feature; Microsoft added it to SQL Server 2017.
I also suspect that Oracle's autonomous DBMS can automatically builds indexes for slow queries since you cannot manually create indexes. Again, this is likely using Oracle's existing database design tools and not new ML techniques. Using ML and/or RL for query optimization is something that my research group is investigating. I also have heard rumors that both Microsoft Research and Berkeley have separate projects looking into this problem as well.
Given this, I contend that Oracle's purported "autonomous data warehouse" is not a complete self-driving DBMS. It is a reactionary system. That is, it only looks at what is happening right now or what has happened in the past, and is unable to perform long-term planning. Oracle is likely using forecasting models for provisioning resources for the data center as a whole, but it does not tune your database according to your specific application's expected workload patterns and shifts.
I emailed Larry Ellison to talk about this with him but he did not get back to me. Larry never responds to my emails.
Is a True Self-Driving Databases Even Possible?
This brings up the question of whether it is even possible to have a completely autonomous DBMS that is able to achieve performance as good or better than one that is manually maintained by a human for all possible workloads. I think that the answer is 'yes' but definitely not for a while. In the same way that self-driving cars will be good enough for mundane daily driving but inadequate for more complex driving scenarios (e.g., rally racing), I think that self-driving DBMSs will be good enough for most application scenarios. For the most complex situations, you will probably still need a human. But self-driving DBMSs will enable humans to deploy some optimizations that would not otherwise be possible. Think of it like TAS for databases.
There is also the philosophical question of if a system like Oracle's autonomous DBMS is fast enough to react to any changes without forecasting, then can that be considered the same as a self-driving DBMS? That is, if the system is able to react quickly enough to changing workloads then it does not need to have the predictive forecasting capabilities that I said was necessary for it to be self-driving. From the human's perspective, it looks as if it is able to handle everything on its own as if it had forecasting. For the types of optimizations that Oracle is targeting in their first release, this might be true. But where forecasting will matter the most and where a true self-driving DBMS will have the advantage is for capacity planning.
The advent of "serverless" deployments is also an interesting topic for self-driving DBMSs. I am going to hold off on discussing these environments for when I talk about engineering for autonomous operation.
Other Academic Projects
Beyond the major vendors, there are a few other academic groups that are actively looking into autonomous DBMSs. I think it's always important to let everyone know what else is out there. Note that I would not label all of these projects as self-driving DBMSs (at least not from how I understand them):
- Deep Tune DB — Jens Dittrich and his team at Saarland University are exploring the use of RL for physical design. They have a proof-of-concept for index selection. Jens also had a previous project, called OctopusDB, that supported hybrid storage models and was influential to the design of our storage manager.
- CrimsonDB — This is also a newer project from Stratos Ideros' group at Harvard. It is part of his larger theme on self-designing systems. The main idea is that the DBMS can optimize its physical data structures according to changes in the workload and hardware.
- DBSeer — This is an external framework from Barzan Mozafari's group in Michigan. It helps a DBA diagnose problems by comparing regions in the DBMS's performance time-series data where the system was slow with regions where it behaved normally. These techniques could be used for estimating the benefit/cost of actions in a self-driving planner. Barzan also has a great VLDB'17 paper on adaptive lock scheduling for MySQL.
Footnotes
- I eventually did run into my massage partner a few years later and I asked her why she stopped coming to class. She said that got stoned one night and got a job as a psyhic hotline operator. So she was too busy to come to class anymore. I'm not sure if I believe her...
- Self-Driving Database Management Systems - Pavlo et al. (CIDR 2017)
- I would like to know more about this problem with LEO, so please email me if you know why.