My first semester as a new professor went by quickly. My seminar class was a lot of fun, and thankfully only one student got stabbed during one of our field trips to a database company in New York City that I cannot legally mention. It sounds trite, but time really does go by fast when you enjoy what you're doing.
In addition to working with my two first-year Ph.D. students, I also advised three master's students on their capstone projects for CMU's Very Large Information Systems program (soon to be renamed to the Data Science MS program). All three of them worked hard and are headed to Google in Mountain View after graduating this semester. I just want to summarize the cool stuff that they worked on.
Replication Schemes in Distributed Main Memory Database Management Systems
Student: Chaomin Yu (with Mike Stonebraker)
In this project we wanted to compare the "active-active" replication scheme that is used in VoltDB with an "active-passive" scheme. In the former, each replica executes the stored procedure for each transaction at the same time, thus there is no need to send updates or coordinate the transaction while it is running. With active-passive, the master replica executes the transaction first, and then sends the updates to the replicas after the transaction has finished executing. Note that in both cases the master has to wait for all of the replicas to return acknowledgements that they successfully updated the database on behalf of the transaction before it is allowed to return the result back to the client application. All of the transactions are also durable because VoltDB uses a form of a logical write-ahead log called command logging. We are going to ignore failure scenarios for this study.
Our hypothesis was that since OLTP transactions have such short run times on a main memory DBMS, active-active is clearly the better option because the master doesn't wait for one entire network roundtrip before it can complete the transaction.
We used the code written by Nirmesh Malviya as part of his MS thesis at MIT where he implemented ARIES-style physical logging in VoltDB 2.0 (it was obviously couple of years ago). We extended his work to implement active-passive replication where the master is able to package up and send these ARIES log messages to the slaves and then install them.
To compare the performance between the two schemes, we ran the venerable TPC-C workload on our modified version VoltDB. We used an eight partition master node with three replica nodes on the Big Data ISTC cluster at MIT. We ran the client threads on a separate node and ramped up the number of transactions that they submit per second until we saturated the cluster.


The results above show that the active-active scheme has a higher sustained throughput of almost 21,000 txn/sec where as the active-passive scheme maxes out at about 13,000 txn/sec. We also see that because the master has to wait longer to get acknowledgements from the slaves for active-passive, the latency is much higher for this scheme as well. For all of the experiments that we ran, we found that active-active is roughly 1.8x faster than active-passive.
Hybrid OLTP&OLAP Main Memory Database System
Student: Ge Gao
For this project, we tried recreating the copy-on-write snapshot technique from HyPer in H-Store. H-Store is notoriously bad at OLAP queries because they have to run as a distributed transaction that locks the entire cluster. Using HyPer's snapshot technique, when an OLAP query arrives in the system, the main DBMS process forks itself and then processes that query in the child process. Thus, it will in theory not affect the performance of the regular OLTP workload. Since the database is stored entirely in main memory, the child process will have complete copy of the database. The original HyPer paper showed that this forking is inexpensive because of copy-on-write in the OS. This is the same approach that Redis uses to write snapshots to disk.
H-Store is written in both Java and C++; the front-end transaction coordinator is in Java, the back-end execution engine is in C++. Unfortunately forking is not advised in the JVM. This is because when you fork the JVM process, only the thread that invoked the fork will be running in the child process. This means that the garbage collector and any other system threads will not be running. You also have to make sure that no thread holds a lock when you fork because you will be unable to release them in the child. Nevertheless, we decided to try it out anyway.
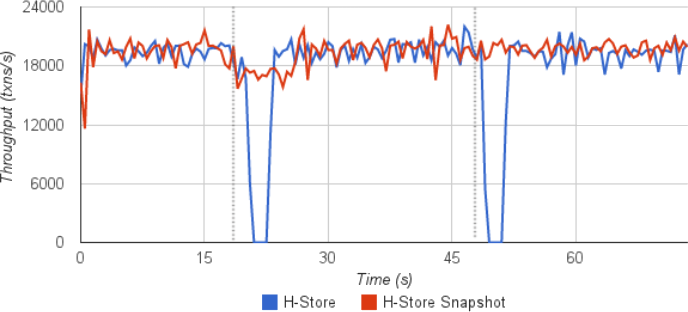
We deployed H-Store on a single node with eight partitions and executed a single-partition only variant of TPC-C. After letting the system warm up for one minute, we then issued a single OLAP query derived from TPC-H at 20 seconds and then again at 50 seconds. For one trial, we use the default version of H-Store where the query is executes as a distributed transaction. We then use Ge's modified version of H-Store that is forks the JVM when the first query arrives and then passes the request over a socket to the child process. We re-use the same child process when the second query arrives.
The results were disappointing. We found that forking the JVM turned out to actually be expensive. As shown in the graphs below, the throughput of the snapshot version of H-Store drops significantly and does not return to normal levels until after the distributed query finishes in the unmodified version. This is because the parent process is still executing transactions that insert/update tuples, and thus this means that the OS has to start copying the pages that get modified. Note that the throughput of the unmodified version of H-Store falls to zero when it executes the OLAP query because all of the partitions are locked until the query finishes.


To prove that the disappointing performance was due to the parent process updating pages, we executed a read-only version of TPC-C (i.e., just StockLevel and OrderStatus transactions) and ran the same experiments. As shown in the graphs below, the snapshot version of H-Store had much lower overhead and does not suffer the same sustained drop in performance.

So in the end, it turned out that the HyPer snapshot approach did not work well for H-Store. It was an interesting experiment though. The student spent a lot of work just trying to get forking to work properly in the JVM. We found it to be quite unstable. Of course, there are other approaches for running low-overhead distributed OLAP queries as MapReduce-like transactions in H-Store, but we didn't get a chance to try compare them in this work.
Automated Database Tuning with Online Experiment Repository
Student: Yu Su
Finally, my last student worked on building an on-line repository for our OLTP-Bench framework and then using machine learning techniques to automatically tune DBMS installations.
The repository is based off of PyPy's Codespeed framework. The user creates an account on our site and is given an upload code that they add to the OLTP-Bench config file. Then when they run a benchmark trial with the framework, it will automatically upload the performance results (i.e., throughput. latency, etc), the workload configuration, and their DBMS configuration (e.g., the contents of my.cnf). It will then make nice graphs for you and allow you to drill into the results to see timeseries information. Part of the motivation behind this was that both myself and other database PhD students have remarked about how much of a pain it is to run experiments and keep track of the results. The idea behind the website is that will make this aspect of graduate school much more easier.




The next part of the project was to use machine learning to be able to predict what kind of performance MySQL would have for a particular configuration file. We first ran a series of experiments where we permuted the InnoDB configuration knobs that have the most impact on runtime performance. For this part of the project, we used machines on Amazon EC2 and PDL's VCloud here at CMU. We then categorized each configuration as being either "good", "bad", or "okay" based on whether the throughput was one standard deviation above or below the median. We then used this data to train a Random Forest classifier using Weka.
Our results found that we were able to correctly categorize the performance of a random MySQL configuration up to 87% of the time for TPC-C and up to 78% of the time for TATP. In fact, our classifier correctly predicted that the default settings for MySQL are classified as "bad". I was pleased with this result given that we only collected a small data set.
The next step for this project is to build a more full featured version of the website and make it publicly available. In addition, we are looking to expand on the machine learning part of the project so that it can actually generate (near) optimal configurations for any possible DBMS (instead of just for MySQL).