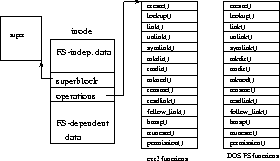
Figure 1: File System Placement in the Operating System
Mihai Budiu
April 16, 1997
This paper presents the design and implementation of a Unix-compatible file system, ext4, which uses two disk partitions to store its data. One partition is used exclusively for directory-related information, and one partition for ordinary files. The file system is developed as a modification of the Linux-ubiquitous ext2 file system. The aim is to benefit from:
This paper tries to be self-contained, and thus is a bit long. The many details are explained having in mind people who may try to replicate my experience. Some very common details (e.g. physical disk geometry) are considered well-known and not treated.
Some hints for the reviewers seem welcome: the essential sections describing my work are 1, 3.1, 4.1.5, 5, 6; one can safely read only these parts and have an image of the project.
In a world where processors and networks are faster and faster, the rate of increase of disk access speed is lagging behind. A decade has seen only a minor improvement in seek time: transfer time and rotational delay have witnessed a better improvement, due mainly to increased data density. (This is also the factor which enabled disk size to grow so fast.)
To compensate for this phenomenon considerable effort goes into squeezing every bit of performance from a file system by exploiting all kinds of idiosyncrasies of the mechanics, hardware and software. The efficiency factors targeted by file system writers are higher bandwidth and lower latency for file access.
There seems to have been at least one attempt to implement a system similar to ext4, but not in that exact form. A survey of the literature and an inquiry on comp.os.research led me to the conclusion that the attempt might prove at least insightful.
The closest match to ext4 is a three-disked file system, log-structured, which uses one disk for data, one for directory-type data and one for the log itself. It is described in [1].
Here is a summary of the methods and design alternatives that seem to be used effectively for increasing file system performance, or just the user perception of it:
Data layout policies tend to treat specially the pieces of data which are probably used in sequence, like consecutive blocks of a same file, or inodes referred by a directory. See [6].
A special form of data layout is observed in log-structured file systems, described briefly below (and more in [7]).
Observe that usually caching on the client disk is slower than caching on the server RAM, because the local area networks can provide a much higher bandwidth than the disks.
Sometimes RAID disk systems are designed to provide increased reliability, using one disk for storage of redundant information (i.e. parity). For instance, redundant RAID schemes with two disks (which are also called ``mirrored'' disks); the redundancy schemes tend to be less efficient, especially on small writes, because they have to read all the data blocks on which the redundant checksum depends.
This technique is effective only in the presence of very large caches, because it assumes most traffic is for writes; it also assumes that large writes can be make with a single disk access, allocating the new versions of the blocks contiguously.
This is why the scheme needs a garbage collector to get rid of the old versions and to compact the free space; contiguity of free space is a requisite for high write bandwidth. Garbage collection is an important source of overhead.
while (size) {
bh = allocate_buffer();
copy_data(source, bh, MIN(size, buffer_size));
size -= buffer_size;
if (size < 0) size = 0;
}
So even for a bulk write, the buffers are allocated one by one. This may not produce contiguous buffers, as the allocation routine has no hints about the previous allocations. (This code may also block in the allocate_buffer() function, so many other allocations may happen in other threads before this loop terminates.)
Thus, although the kernel knows from the beginning how much space it will need for file growth during the current system call, usual schemes fail to allocate this space contiguously, even if it is available!
Four (partial) workarounds exist:
Although this enumeration may seem overly general and unrelated to the main topic of this paper, most of the ideas are effectively used in the ext4 file system (mostly because they are inherited from its ext2 ancestor). The next section of this paper will try to prove this assertion.
Basically ext4 tries to make use of a modified type of RAID-0 technique. RAID-0 techniques transform two partitions (disks) into a single ``virtual'' partition, either by concatenating their blocks, or by interlacing them (i.e. even-numbered blocks taken from one physical partition and odd-numbered from the other). The RAID-0 has no knowledge about the file system structure, and achieves ``striping'' at the device driver level (note in passing that Linux has a RAID-0 facility, the md driver, which however has no connection to our project).
Our file system tries to take advantage of the knowledge of block contents, and splits data on two disks at a ``higher'' level.
The ext4 file system is the result of a long evolution of file system technology, which starts with the initial Unix file system, designed in the seventies by Ken Thomson. Many ideas are still basic (like inodes); a chronological description of the evolution of the Unix file systems, besides the interest in itself, will shed some light on the choices which gave rise to the design of ext4. The informed reader may skip with no loss the following paragraphs, down to the one discussing ext4.
The ``prototype'' file system remains the original Unix file system, designed by Ken Thomson. Its modularity, cleanliness, and simplicity are offset only by the, sigh, low efficiency. In a way or another, the sequent systems are all ``patches'' to the original design, and they try to squeeze a few more drops of performance by sacrificing the elegance of the design: ``if it works fast it doesn't matter if it's ugly.'' All the sequent systems provide a superset of the original interface.
The file model in UNIX is very simple: a simple byte array with a very large maximal size.
The figure 1 represents the placement of the kernel file system procedures amongst other kernel services.
Figure 1: File System Placement in the Operating
System
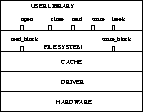
The driver (and the cache) offer access to the disk viewed like a huge block array. The file system reads and writes such blocks in one operation. Each disk partition has to hold an independent file system.
The file system uses the partition blocks in the following manner (figure 2):

Figure 2: Partition Utilization by File System
The superblock contains a description of the global parameters of the file system. Some examples are: partition size, partition mount time, number of inodes, free blocks; free inodes, file system type (``magic number'').
Next a number of blocks is allocated for storing individual file descriptions. Each file is described by an inode or information node. The number of inodes is allocated statically, at file system creation time. All relevant file attributes are kept in inodes, including a representation of the list of the blocks used by the file, (figure 3). The indirect blocks need to be present only if the size of the file is big enough (i.e. the simple indirect pointer may be NULL). This scheme has many merits; let us only observe that files with ``holes'' inside can exist.
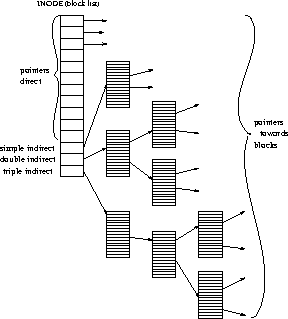
Figure 3: Block List Representation in Inodes
The directories are actually in all respects like ordinary files (i.e. they have an inode, data blocks, they grow in the same manner), but the operating system cares about the meaning of the directory contents. The directory structure is very simple: each is an array of links.
A link is a structure which associates a name (string) to an inode number. Figure 4 shows the directory structure.
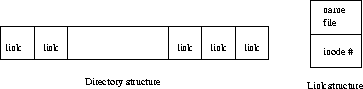
Figure 4: Directory and Link Structure
Each file has to have at least one link in one directory. This is true for directories too, except for the root directory. All files can be identified by their path, which is the list of links which have to be traversed to reach the file (either starting at the root directory, or at the current directory). A file can have links in many directories; a directory has to have a single link towards itself (except ``.'' and ``..''), from its parent directory.
The Unix program mkfs transforms a ``raw'' partition into a file system by creating the superblock, initializing inodes and chaining all the data blocks into a huge list of blocks available for future file growth.
The free blocks are practically grouped into a big fictitious file, from which they are retrieved on demand (when other files or directories grow), and to which they return on file removal or truncation.
Let us observe that all operations carried on files have to bring the relevant data (e.g. inodes) in-core (in the RAM). The in-core representation of the data structures is significantly more complex than the structure on disk, because a lot of information implicit on the disk is missing in-core (for instance the inode number, the device, the file system type).
The main deficiency of the Version VII file system (the one presented above) lies in its total ignorance of disk geometry. After awhile, the free list has a random ordering, so blocks are allocated haphazardly, leading to very long seek times inside files.
The FFS [6] tried to solve this problem, by forcing clustering of the data. The main idea was to divide the disk into ``cylinder groups'', which are sets of neighbouring cylinders (i.e. with small seek time between the component tracks). Each cylinder is treated like an independent partition in UFS, having its own superblock, inodes, free list and data blocks, but allowing overflow into neighbouring cylinder groups.
FFS tried to allocate ``logically close'' blocks close. For instance, it allocates (if possible) regular file inodes in the same group as the directory holding them, and data blocks for a file in the same group as the file's inode. On the contrary, it allocates directory inodes on the less loaded group, and it forces the change of cylinder group at each megabyte of file size (to avoid fragmentation inside a cylinder group). The allocation uses geometry parameters to compute a ``closest block''.
The allocation schemes of FFS work well if the disk is loaded under 90% of full capacity, else they trash.
Besides improved layout, FFS brought some other ideas to the area, like:
SunOS introduced yet another extension to the file system technology, which allowed a kernel to simultaneously support multiple file systems which differ wildly in the internal architecture. This was built to allow a kernel to support simultaneously a ``local'' file system and an NFS-mounted file system.
The technique, named ``Virtual File System Switch, (VFS)'' is reminiscent of object-oriented programming: you have a base class, named filesystem which has a bunch of virtual methods which are overridden by every other custom file system present in the kernel.
VFS works on its own data structures, called ``virtual inodes'', or ``vnodes'', on which it can carry many operations which may be file system independent. Each vnode describes a file belonging to some file system. Whenever VFS needs custom operations, it dispatches the call to the file system owning the inode (figure 5).
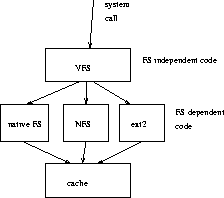
Figure 5: Virtual File System Switch
All information about physical file placement is file system dependent (thus unknown to VFS); this allows us to add yet another file system which uses special layout (in our case two disks) without changing anything in the VFS layer.
The ext2 file system draws heavily on the legacy of the FFS and VFS systems. It has its own characteristics, though:
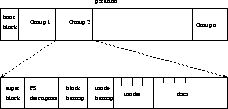
Figure 6: Group Structure in ext2
The power of the VFS is apparent in Linux in its entirety, as Linux supports with the same easiness as many as 10 different file systems, ranging from NFS to DOS FAT.
There are three principal data structures in the Linux VFS layer, which point to file system dependent and independent parts. These are:
Each in-core version of such an object has a structure with pointers to the handlers manipulating that specific object. Figure 7 illustrates this fact for the inodes. (In official SunOS terminology the structure is a vnode, and the file system-dependent part is the inode, but Linux names both inodes.)
Here is a typical piece of code from the kernel, in the file system-dependent routine of ext2 which loads an inode:
if (REGULAR(inode->mode))
inode->operations = &ext2_file_inode_operations;
else if (DIRECTORY(inode->mode))
inode->operations = &ext2_dir_inode_operations;
else if (SYMLINK(inode->mode))
inode->operations = &ext2_symlink_inode_operations;
else ...
The VFS will call the inode operations indirectly (e.g. inode->operations->link()), without having to know anything about the implementation.
ext4 is basically a refinement of ext2, which uses two partitions simultaneously, ideally placed on separate disks.
Both partitions contain the information ordinarily found inside a file system: inodes, direct and indirect blocks, superblocks and bitmap information. The only difference between the two partitions is that all directories will sit on one of them (both the blocks and inodes), and ordinary files on the other one.
Right now all other types of files (symbolic links, named pipes, special files) are kept on the same partition as the regular files, although their right place obviously is the directories' partition, because their usage pattern is supposedly similar to the directories themselves. This change should not prove difficult.
This layout allows the operations on files and directories to proceed in parallel. Requests for reading/writing a directory block and a file block can be processed simultaneously, reducing user-perceived latency.
Let us observe that simultaneous outstanding requests for directory and file manipulation arise even in the context of I/O of a single user process, because of the write-behind and read-ahead actions of the cache; this means they are not an exotic circumstance, and we are indeed trying to solve a real problem.
Basically two things have to be changed in ext2 to obtain ext4:
The development platform of the project is Linux OS, with a kernel version 2.1.18.
The development comprises not only a modification of the kernel sources of the ext2 file system, but also of the associated utilities, including the mkfs and fsck programs. One conspicuous absent from this suite is the mount/umount executable programs, which don't even need recompilation. The kernel does most of the argument parsing!
Only one real design difficulty had to be faced, and this is concerned
with the availability of the information. Recall that a directory
holds in the links only pairs 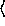 name, inode number
name, inode number 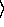 . To open
a file one needs first to load the corresponding inode into memory.
. To open
a file one needs first to load the corresponding inode into memory.
But having two partitions, I end up having twice the inode 5. Which inode 5 is to be loaded when a directory entry contains the number 5? The one on the partition with directories, or the one on the partition with files? To disambiguate I played a dirty trick, recording the partition number (and implicitly the file type...) inside the inode number. The last bit was chosen for this purpose.
In this way all directories have even-numbered inodes, and all regular files have odd-numbered inodes. This change is transparent to the applications and to the VFS, who do give any meaning to inode numbers.
Because disk blocks can be referenced only from one place at a time (i.e. two files cannot share a block) we did not use the same technique for block numbering. But then every time we need to read/write say block 7, we must have at hand information indicating which partition is considered. We distinguish some cases (refer again to figure 6):
This proves that at anytime there is no ambiguity about the partition to be accessed to manipulate an indicated block; this is why we don't need to use discriminatory schemes in block numbering to indicate the partition, like we did for inodes.
Here is a brief chronological account of the phases of the development process:
Some work remains to be done for the system to prove useful. The following areas will receive special attention, roughly in the specified order:
Even before making any measurements, we can anticipate that we will not get tremendous performance increase, and that ordinary benchmarks should not show remarkable advantages of the new design. This is due to the following factors:
I have tried to evaluate the design using the famous Andrew benchmark, but the results are not relevant, due to the low precision of the timing available to the shell. I have thus run the following simple benchmark:
cycles=5 date mount while [ $cycles -ge 0 ]; do time cp -R /usr/src /fs1 time cp -R /usr/src /fs2 time cp -R /usr/src /fs3 time cp -R /fs2/src /fs2/src1 time cp -R /fs3/src /fs3/src1 time rm -rf /fs1/src time rm -rf /fs2/src time rm -rf /fs3/src time rm -rf /fs2/src1 time rm -rf /fs3/src1 cycles=`expr $cycles - 1` done
There are about 150Mb of data moved on each copy. The machine has 64Mb of RAM (so cache is essential in timing), has a Pentium processor at 166MHz, and two drives, denoted by a and b. [Need some disk information.]
The following file systems are involved:

The results of the benchmark are encouraging; these are some of the timings, in seconds. This is true elapsed time, on an otherwise idle system.
The observed results are not very good considering the resources thrown into play. Apparently the ``md'' driver for RAID-0 gives more benefits for the same resources (i.e. two disks) (I have been told; I don't know exactly what is the improvement in performance offered by it). More complex tests and better allocation techniques may reduce somehow the gap.
The performance is still better than two file systems which use the
same resources, at least for the tests I carried out (compare copies a
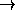 b
with a+b
b
with a+b  a+b).
a+b).
The amount of enhancement observed in my tests is also partially a measure of the amount of asynchronous operations of the cache, because it is caused only by these operations. Maybe a careful re-read of the whole file system code would reveal additional places where parallelization could give benefits (although I don't expect to find many such places; maybe for the synchronous writes).
The results are not bad enough to discourage further enhancements; the design has some viable features, which aren't maybe yet exploited to their full capacity.
A Dual-Disk File System: ext4
This document was generated using the LaTeX2HTML translator Version .95.3 (Nov 17 1995) Copyright © 1993, 1994, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -split 0 fs.tex.
The translation was initiated by Mihai-Dan Budiu on Tue Aug 5 11:55:45 EDT 1997