3D Social Saliency
from Head-mounted Cameras
Hyun Soo Park1, Eakta Jain2, and Yaser Sheikh1
1Carnegie Mellon University
2Texas Instruments
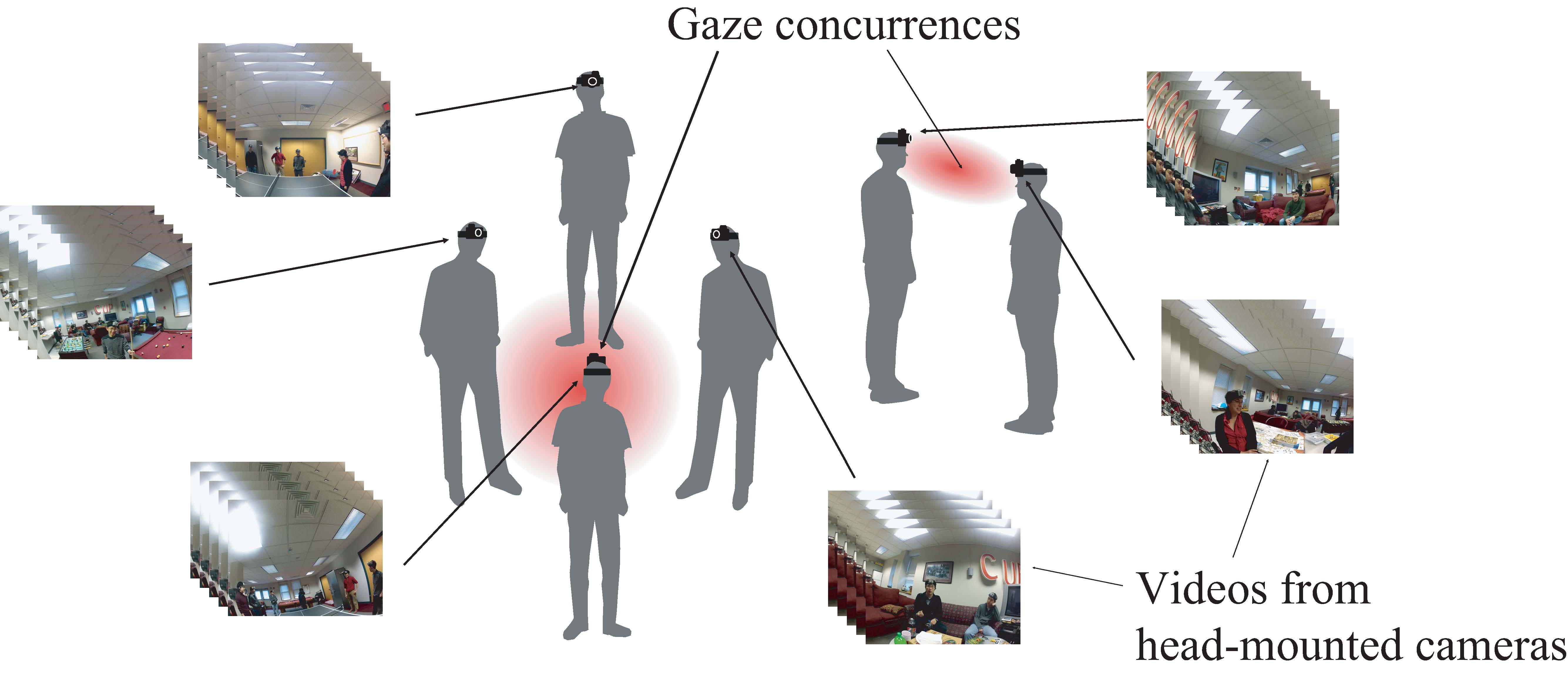
Figure 1: We present a method to reconstruct 3D gaze concurrences from videos taken by head-mounted cameras.

Figure 2: We reconstruct the gaze concurrences for the party scene. 11 head-mounted cameras were used to capture the scene. Top row: images with the reprojection of the gaze concurrences, bottom row: rendering of the 3D gaze concurrences with cone-shaped gaze models
Abstract
A gaze concurrence is a point in 3D where the gaze directions of two or more people intersect. It is a strong indicator of social saliency because the attention of the participating group is focused on that point. In scenes occupied by large groups of people, multiple concurrences may occur and transition over time. In this paper, we present a method to construct a 3D social saliency field and locate multiple gaze concurrences that occur in a social scene from videos taken by head-mounted cameras. We model the gaze as a cone-shaped distribution emanating from the center of the eyes, capturing the variation of eye-in-head motion. We calibrate the parameters of this distribution by exploiting the fixed relationship between the primary gaze ray and the head-mounted camera pose. The resulting gaze model enables us to build a social saliency field in 3D. We estimate the number and 3D locations of the gaze concurrences via provably convergent mode-seeking in the social saliency field. Our algorithm is applied to reconstruct multiple gaze concurrences in several real world scenes and evaluated quantitatively against motion-captured ground truth.
Paper
Hyun Soo Park, Eakta Jain, and Yaser Sheikh "3D Social Saliency from Head-mounted Cameras" Advances in Neural Information Processing Systems (NIPS), Dec., 2012, [PDF, PDF_supplementary, bib]
Video
video download (92.8 MB) The code is supplied with no warranty and Carnegie Mellon or the authors will not be held responsible for the correctness of the code. The code of the software will not be transferred to outside parties without the authors' permission and will be used only for research purposes. In particular, the code will not be included as part of any commercial software package or product of this institution.Acknowledgements
This work was supported by a Samsung Global Research Outreach Program, Intel ISTC-EC, NSF IIS 1029679, and NSF RI 0916272. We thank Jessica Hodgins, Irfan Essa, and Takeo Kanade for comments and suggestions on this work.