 Fx Overview
Fx Overview
David R. O'Hallaron
School of Computer Science
Carnegie Mellon University
droh@cs.cmu.edu
Fx is a parallelizing Fortran compiler, based on a dialect of High Performance
Fortran (HPF), that supports sensor-based and scientific computations. Fx
has been ported to the Intel iWarp, IBM SP/2, Intel Paragon, Cray T3D,
and networks of workstations.
Fx pioneered (1) the development of real applications for HPF, (2) the
integration of task and data parallelism, and (3) direct deposit
message passing. This report discusses Fx applications, the performance
gains from task and data parallelism, and the performance gains from
direct deposit message passing.
1. Example applications
Fx has been used to implement a number of sensor-based and scientific
applications. Here are some examples:
- Air quality modeling (CMU Mech Eng)
- Stereo imaging (CMU vision group)
- Spotlight SAR (Sandia and CMU)
- Earthquake ground motion modeling (USC and CMU)
- Magnetic resonance imaging (Pitt and CMU)
- Narrowband tracking radar (CMU and MIT)
Figure 1 shows the performance of a spotlight synthetic aperture radar
code on the Intel Paragon. The Fx code was adapted by Peter Lieu at
Carnegie Mellon from original F77 code provided by Sandia
Laboratories. The performance of the single-node Fx code is
comparable to that of the original F77, and the speedup as a function
of the number of Paragon is nearly linear.

| 
|
| (a) Output image with four targets.
| (b) Measured performance on Paragon.
|
Figure 1: Spotlight synthetic
aperture radar.
Figure 2 shows the performance of an earthquake ground motion simulation.
The simulation, based on the method of boundary elements,
was adapted from an original F77 program by
Yoshi Hisadi while he was visiting Carnegie Mellon from the Southern
California Earthquake Center. Again, speedup as a function of the
the number of nodes is almost linear.

| 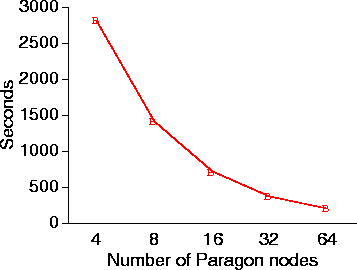
|
| (a) Frequency response of 3D synthetic basin.
| (b) Performance of ground motion simulation on Paragon.
|
Figure 2: Earthquake ground motion
simulation.
For additional information on Fx applications:
-
D. O'Hallaron, J. Webb, J. Subhlok. Performance issues in HPF
implementations of sensor-based programs. Scientific Programming,
1996, to appear.
abstract,
postscript.
2. Integrating task and data parallelism in Fx
If a program consists of one or more functions that do not scale well
because of internal communication, or if it operates on small data
sets (typical of sensor-based computations), then exploiting a mix of
task and data parallelism can have a significant impact on
performance.
Figure 3 shows how Fx integrates task and data parallelism, while
still retaining sequential semantics. Tasks are subroutines (called
task-subroutines) within special code regions called parallel
sections. For each task-subroutine, the programmer uses directives to
tell the compiler whether each parameter is input, output, or both,
and how many processors the task-subroutine will run on. The compiler
can either ignore the directives and generate the typical data
parallel code, or use the directives to generate task parallel code.
Figure 3: Approach: integrating
task and data parallelism in Fx
Figure 4 shows the speedup on iWarp of mixed Fx task and data parallel
programs over purely data parallel Fx programs.
Figure 4: Performance benefit of
mixed task and parallel over purely data parallel mappings on
iWarp
A suite of small, yet realistic F77 programs
that can benefit from a mix of task and data parallelism is
available to the public. For additional information on task
parallelism in Fx:
-
T. Gross, D. O'Hallaron, and J. Subhlok.
Task parallelism in a High Performance Fortran framework.
IEEE Parallel & Distributed Technology, vol 2, no 2, pp 16-26.
abstract,
postscript.
The basic Fx task parallelism reference.
-
J. Subhlok, D. O'Hallaron, T. Gross, P. Dinda, J. Webb,
Communication and memory requirements as the basis for mapping task and
data parallel programs. In Proc. Supercomputing '94, Washington, DC,
Nov. 1994, pp. 330-339.
abstract,
postscript.
Description of the approach used for mapping task parallel Fx programs.
-
J. Subhlok, and G. Vondran.
Optimal mapping of sequences of data parallel tasks.
In Proc. of the Fifth ACM SIGPLAN Symposium on Principles and
Practice of Parallel Programming, Santa Barbara, CA, July, 1995,
pp. 134-143.
abstract,
postscript.
Explores tTradeoffs between latency and throughput for chains.
-
J. Subhlok, Automatic mapping of task and data
parallel programs for efficient execution on multicomputers,
Technical Report CMU-CS-93-212, School of Computer Science, Carnegie
Mellon University, November, 1993.
abstract,
postscript.
Descibes a tool that automatically maps task parallel Fx programs
-
P. Dinda, T. Gross, D. O'Hallaron, E. Segall, J.
Stichnoth, J. Subhlok, J. Webb, and B. Yang,
The CMU task parallel program suite,
Technical Report CMU-CS-94-131, School of Computer
Science, Carnegie Mellon University, March, 1994.
abstract,
postscript.
Describe a suite of small, yet realistic F77 programs (with sources) that can benefit from a mix of
task and data parallelism.
-
J. Subhlok, J. Stichnoth, D. O'Hallaron, and T. Gross,
Exploiting task and data parallelism on a multicomputer, Proceedings
of the ACM SIGPLAN Symposium on Principles and Practice of Parallel
Programming, San Diego, CA, May, 1993, pp 13-22.
abstract,
postscript.
The original paper describing the integration of task and data parallelism in Fx.
3. Direct deposit message passing
Fx pioneered direct deposit message passing for efficient
communication between processing nodes. The central idea behind direct
deposit message passing is to decouple communication from
synchronization. Figure 5 shows the basic approach.
Figure 5: Direct deposit message
passing
Figure 6 shows the per-node communication performance of a transpose
operation on the Cray T3D. Deposit message passing is compared
to the vendor supplied PVM interface, the vendor-supplied
tranpose instrinsic, and the transpose operation generated by the
CRAFT compiler. The chief result is a factor of two gain over the
vendor transpose.
Figure 6: Per-node communication performance for transpose operation on the Cray T3D.
Figure 7 shows the aggregate communication performance of T3D transpose.
Again, performance using direct deposit message passing shows a factor
of two gain over the vendor supplied intrinsic.
Figure 7: Aggregate communication performance for transpose operation on the Cray T3D.
A fast transpose
library, based on direct deposit, has been developed for the T3D
at Pittsburgh Supercomputing Center. For more information on direct deposit message passing,
and generating communication code in general:
-
T. Stricker, J. Stichnoth, D. O'Hallaron, S. Hinrichs, and T. Gross.
Decoupling synchronization and data transfer in message passing
systems of parallel computers.
In Proc. of the 9th International Conference on Supercomputing,
ACM, Barcelona, Spain, July, 1995. pp 1-10.
abstract,
postscript.
The basic direct deposit reference.
-
J. Stichnoth, D. O'Hallaron, and T. Gross, Generating
communication for array statements: Design, implementation, and
evaluation, Journal of Parallel and Distributed
Computing, vol. 21, no. 1, Apr, 1994, pp. 150-159.
abstract,
postscript.
Describes the Fx algorithm for communication code generation and
introduces an early version of deposit message passing.
-
P. Dinda and D. O'Hallaron.
Fast message assembly using compact address relations.
In Proc of the Intl. Conf. on Measurement and Modeling of Computer
Systems, ACM SIGMETRICS, Philadelphia, PA, May, 1996.
abstract,
postscript.
Describes an efficient runtime technique for communication code generation.
-
S. Hinrichs, C. Kosak, D. O'Hallaron, T. Stricker, and R. Take. An
architecture for optimal all-to-all personalized communication.
In Proc. of SPAA '94, ACM, June 1994, pp. 310-319.
abstract,
postscript.
Extended and updated version of paper appears as CMU technical report
CMU-CS-94-140.
postscript.
Describes eEfficient code generation for the complete exchange.
fx-compiler@cs.cmu.edu 3/96


