My Research Interests
I am interested in devising practical algorithms for important learning and optimization problems with strong theoretical guarantees on their performance. Below are descriptions of (some of) the projects I have worked on.
Active Learning and Experimental Design
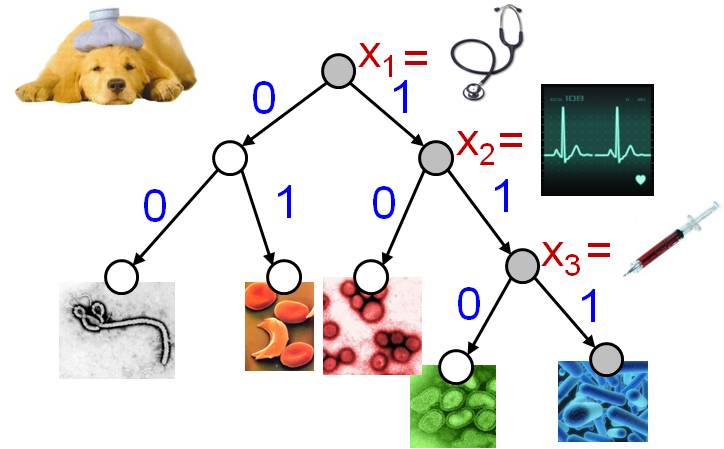 I have worked with Andreas Krause
on an extension of the very useful notion
of submodularity to adaptive optimization problems. In these
problems, you perform a sequence of actions, where each action can
depend on the result of the previous actions. An example adaptive
optimization problem might be a physician trying to diagnose a
patient; the physician performs a sequence of tests where each
choice of test depends on the outcomes of all previous tests.
These problems are notoriously difficult to reason about in
general.
I have worked with Andreas Krause
on an extension of the very useful notion
of submodularity to adaptive optimization problems. In these
problems, you perform a sequence of actions, where each action can
depend on the result of the previous actions. An example adaptive
optimization problem might be a physician trying to diagnose a
patient; the physician performs a sequence of tests where each
choice of test depends on the outcomes of all previous tests.
These problems are notoriously difficult to reason about in
general.
However, if the problem satisfies a property we invented called adaptive submodularity, we can prove that a natural greedy algorithm gives near optimal performance, and in fact gives the best possible approximation factors under very reasonable complexity-theoretic assumptions. We use these ideas to recover, improve upon, and generalize several results in stochastic optimization and active learning, as well as discover some new results. The initial fruits of this work appeared in COLT '10. Subsequently, I and my collaborators used adaptive submodularity to develop a new greedy algorithm for Bayesian active learning with noise that is the first to have approximation guarantees in the presence of noisy observations, even when the noise is correlated [NIPS `10].
I believe there will be many more applications of adaptive submodularity, and that it represents an important advancement in our understanding of these notoriously difficult problems.
Distributed Learning and Sensor Selection
 How inherently sequential are the algorithms required for learning?
What are the fundamental lower limits on communication between
sensors and processors for systems that learn and adapt to their
environments?
These are two questions I have been looking at from the perspective
of community sensing and distributed sensor selection. One potential
application is in earthquake monitoring. Most modern laptops and
smartphones now have built in accelerometers.
By collecting enormous quantities of these noisy accelerometer
readings one might be able to obtain extremely detailed
maps of seismic activity. However, given that the users are
volunteering their data, taking constant readings from their devices
is not acceptable, especially in the case of phones. So, which
devices should you query when? In recent work [IPSN '10]
I and my collaborators have developed novel distributed sampling
approaches with essentially optimal theoretical guarantees on both
performance (i.e., quality of measurements obtained) and communication cost, in
the model we consider.
Not surprisingly, they also work extremely well in simulation.
How inherently sequential are the algorithms required for learning?
What are the fundamental lower limits on communication between
sensors and processors for systems that learn and adapt to their
environments?
These are two questions I have been looking at from the perspective
of community sensing and distributed sensor selection. One potential
application is in earthquake monitoring. Most modern laptops and
smartphones now have built in accelerometers.
By collecting enormous quantities of these noisy accelerometer
readings one might be able to obtain extremely detailed
maps of seismic activity. However, given that the users are
volunteering their data, taking constant readings from their devices
is not acceptable, especially in the case of phones. So, which
devices should you query when? In recent work [IPSN '10]
I and my collaborators have developed novel distributed sampling
approaches with essentially optimal theoretical guarantees on both
performance (i.e., quality of measurements obtained) and communication cost, in
the model we consider.
Not surprisingly, they also work extremely well in simulation.
Sequential Decision Making with Complex Decision Sets
I have worked on algorithms for sequential decision problems in which the decision space is exponentially large in the natural problem parameters. By fusing approximation algorithms for NP-hard problems with no-regret algorithms for online decision problems, my collaborators and I have been able to make significant progress on some of these problems, particularly ones that exhibit a natural diminishing returns property called submodularity. Below I describe some example applications. If you are interested, have a look at some of the resulting papers: [NIPS 09], [NIPS 08], [AAAI 07a], and [AAAI 07b].
Speeding up solvers for NP-hard problems by cleverly combining multiple heuristics.
 This line of research has led to algorithms for combining multiple heuristics online that are
both theoretically optimal in the model we consider, and can
demonstrably improve performance
for, e.g., SAT solvers in practice.
We combine (black-box) heuristics via a schedule, that assigns
blocks of CPU time to different heuristics until the given instance
is solved. Our algorithms learn good schedules over time, like the
one in the figure.
This line of research has led to algorithms for combining multiple heuristics online that are
both theoretically optimal in the model we consider, and can
demonstrably improve performance
for, e.g., SAT solvers in practice.
We combine (black-box) heuristics via a schedule, that assigns
blocks of CPU time to different heuristics until the given instance
is solved. Our algorithms learn good schedules over time, like the
one in the figure.
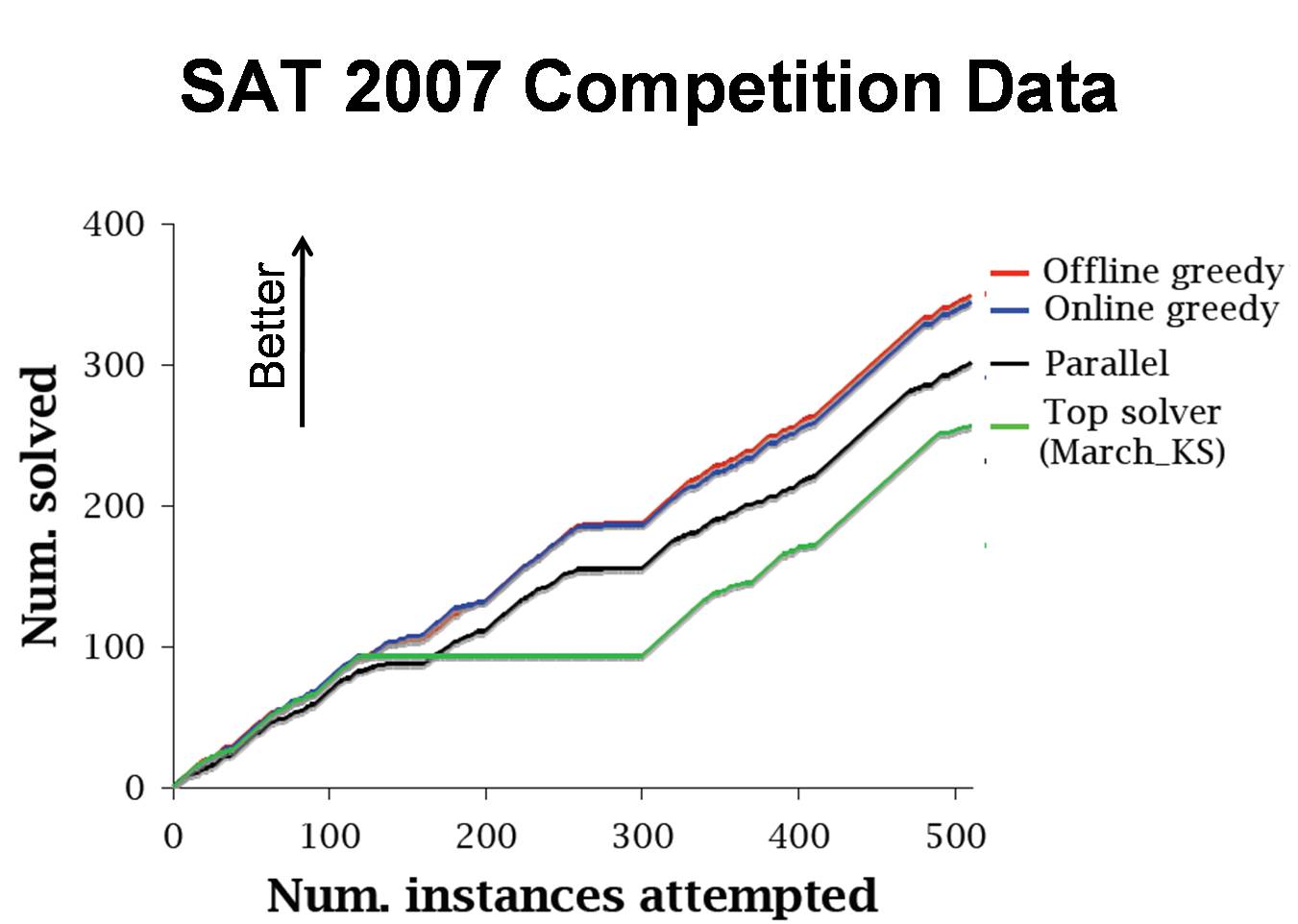 Using data from solver competitions, we can show that our algorithm
can typically learn a "metasolver" which combines the competition
entrants in such a way as to outperform all of its constituent
solvers.
The figure shows the result using the entrants for the SAT
2007 competition. Using this approach, my collaborator
Matthew Streeter won the 2008
International Joint Conference on Automated Reasoning CADE ATP System
Competition in every division he entered (namely FNT and SAT).
His entrant was named MetaProver 1.0; The full
results are available here.
If you are interested, have a look at some of the resulting papers:
[NIPS 08],
[AAAI 07a], and
[AAAI 07b].
Using data from solver competitions, we can show that our algorithm
can typically learn a "metasolver" which combines the competition
entrants in such a way as to outperform all of its constituent
solvers.
The figure shows the result using the entrants for the SAT
2007 competition. Using this approach, my collaborator
Matthew Streeter won the 2008
International Joint Conference on Automated Reasoning CADE ATP System
Competition in every division he entered (namely FNT and SAT).
His entrant was named MetaProver 1.0; The full
results are available here.
If you are interested, have a look at some of the resulting papers:
[NIPS 08],
[AAAI 07a], and
[AAAI 07b].
Sequential Selection of Sets and Lists with Complex Submodular Objectives
In [NIPS 08] we describe how to efficiently learn to select sets of bounded size to optimize an a sequence of unknown submodular objective functions. In [NIPS 09] we describe how to learn to select lists of bounded length in the same model. Submodularity allows us to encode a value for diversity within a set/list in ways that a linear function cannot. Both algorithms have very strong theoretical performance guarantees. Specifically, they asymptotically guarantee at least (1-1/e), or about 63.2%, of the best fixed set/list of items in hindsight, and this is optimal for efficient algorithms (assuming P not equal to NP for set selection, and unconditionally for list selection). We also demonstrate that they perform well in practice on a blog selection task ("which 10 out of 45,000 blogs should you read?"), a water networks pollution detection task, and on a sponsored search ad allocation task.Sensor Selection for Environmental Monitoring and Outbreak Detection
 Where should you place sensors to maximize the value of the
information collected? It depends on how you measure value, but
for many applications, the measure is submodular, and our algorithms
are appropriate. Examples of reasonable measures that are
submodular include:
Where should you place sensors to maximize the value of the
information collected? It depends on how you measure value, but
for many applications, the measure is submodular, and our algorithms
are appropriate. Examples of reasonable measures that are
submodular include:
- area of total sensor coverage (perhaps weighted by importance),
- likelihood for detecting a pollution event, and
- number of people who avoided contamination as a result of detecting a pollution event.

Sponsored Search Ad Selection with Holistic Quality Measures
Submodularity allows us to encode diversity considerations and other complex interdependencies among ads, allowing us to take a holistic view of the value of an ad list. And while the exact details of how the large search engine companies do sponsored search ad allocation are closely guarded secrets, it is fairly safe to say that their current approaches don't address this point. Instead, their current approaches are based on estimating the quality of an ad and the quality of a advertising slot on the webpage, or jointly estimating the quality of an (ad, position) pair, and declaring the value of a list of ads to be the sum of the values of the individual (ad, position) pairs. The result of this disregard for interactions among ads is ad slates like the one on the left (for the query "Santa Clara") which will appeal only to those seeking hotels. Since even a user who wants a hotel room is unlikely to click on more than two such ads, it would be better to try to appeal to a wider range of users.
While it would be foolish to say that we have solved the sponsored search ad allocation problem with rich, holistic quality measures, it is fair to say that our algorithms provide the first principled approach to optimizing lists of ads under such quality measures -- measures which are ultimately defined by the preferences of the users, evolve over time, and must be learned from rather sparse data (e.g., user clicks).

Recommendation Systems and News Aggregators
Recommendation systems and news aggregators present users with lists of results, or more generally, assignments of results to various positions. For an example of the latter, a typical news aggregator will provide, say, a list of three results for various categories like "business", "sports", and "international". Here too diversity of results is important and diminishing returns among news items is evident. Most users prefer K articles covering distinct interesting events over K articles all covering one interesting event.
Our algorithm provides a principled way to learn which lists of results to display, and it performed excellently on a blog-selection task, which recommended a list of blogs for people to read and sought to provide good coverage of major "information cascades," which informally are ongoing discussions within the blogosphere.
Viral Marketing
 Which set of people should you provide with a promotional offer in
order to best encourage "viral growth" in demand for your product?
Even making the (unrealistic)
assumption that you know the complete social network, and know
exactly how demand for a product propagates through it, this is
still an NP-hard problem.
However, if you will be running several advertising
campaigns, then even if you initially
don't know anything about the social dynamics (other than that the
effects of your promotions have diminishing returns)
our algorithm will
learn who should get the promotions and do approximately at least as
well as the best fixed solution in hindsight. And it will achieve
these guarantees
even if the social dynamics are changing over time, as social dynamics
tend to do.
Which set of people should you provide with a promotional offer in
order to best encourage "viral growth" in demand for your product?
Even making the (unrealistic)
assumption that you know the complete social network, and know
exactly how demand for a product propagates through it, this is
still an NP-hard problem.
However, if you will be running several advertising
campaigns, then even if you initially
don't know anything about the social dynamics (other than that the
effects of your promotions have diminishing returns)
our algorithm will
learn who should get the promotions and do approximately at least as
well as the best fixed solution in hindsight. And it will achieve
these guarantees
even if the social dynamics are changing over time, as social dynamics
tend to do.
Uniquely Represented Data Structures, with Applications to Privacy
This is my doctoral dissertation topic: [Abstract], [Dissertation] (PDF, 2.3 MB).
 My thesis work provides the theoretical foundation for efficient
uniquely represented data structures, while overturning thirty years
of pessimism in the literature about the possibility of doing so.
These data structures ensure that the memory layout of the data
structure is a function of the logical state it is supposed to encode,
rather than a function of the sequence of operations used to create
it. Thus each logical state is encoded in a unique machine state.
This opens up the possibility, for the first time, of efficient systems that
store exactly the information that we ask them to store, and
nothing
more. Such systems would eliminate the potential for privacy and
security violations enabled by the undesirable storage of extraneous information.
My thesis work provides the theoretical foundation for efficient
uniquely represented data structures, while overturning thirty years
of pessimism in the literature about the possibility of doing so.
These data structures ensure that the memory layout of the data
structure is a function of the logical state it is supposed to encode,
rather than a function of the sequence of operations used to create
it. Thus each logical state is encoded in a unique machine state.
This opens up the possibility, for the first time, of efficient systems that
store exactly the information that we ask them to store, and
nothing
more. Such systems would eliminate the potential for privacy and
security violations enabled by the undesirable storage of extraneous information.
For example, my work provides the foundation for:
- A filesystem where deleting a file provably leaves no trace whatsoever that it ever existed.
- A voting machine that stores the set of voters who participated in an election, while provably storing no information about the order in which they voted.
- File formats that allow efficient updates while guaranteeing secure redaction of content and removal of history (to avoid embarrassing leaks, as discussed e.g., here, here, and here. )