Finding
Patterns and Anomalies in Large Time-Evolving Graphs
This material
is based upon work supported by the National Science Foundation
under Grant No. IIS-0534205. Any opinions, findings, and
conclusions or recommendations expressed in this material are those
of the author(s) and do not necessarily reflect the views of the
National Science Foundation.
1. GENERAL
INFORMATION
1.1.
Abstract
Social
networks can be represented as time-evolving graphs where the nodes
are the members/entities of the social network and the edges
represent connections/relationships between the nodes. This project
tries to answer questions such as: How does a "normal" social
network look like? How will it evolve over time? How can we spot
"abnormal" interactions (e.g., spam), in a time-evolving e-mail
graph? The approach developed in this project is to look for
time-evolution "laws", and to design fast, scalable data mining
tools for real graphs with millions and billions of nodes. The
approach consist of two efforts: (1) discovery of patterns that
hold when graphs evolve over time and (2) tools to analyze,
visualize and mine such graphs to discover anomalies. The resulting
tools will have a broad applicability. They will be vital for
mining and outlier detection in numerous settings, such as
money-laundering rings, mis-configured routers on the Internet,
suspicious user accesses to database records, surprising
protein-protein interactions in a gene regulatory network, and many
applications involving large-scale evolving social networks. The
project Web site
(http://www.cs.cmu.edu/~christos/PROJECTS/GRAPH-MINING/) provides
additional information and will be used for results
dissemination.
1.2.
Keywords
Data mining, network traffic, time
evolution.
1.3. Funding
agency
- NSF, Award Number: IIS-0534205, Duration:
03/15/2006-2/28/2009
2. PEOPLE
INVOLVED
In addition to the PI, the following graduate students worked on
the project.
3.
RESEARCH
3.1. Project
goals
The goal of the project is to find patterns
in large static and time-evolving graphs. The activities were the
following:
The first was
the use of tensors to analyze time-evolving graphs. Tensors are
multi-dimensional extensions of arrays, and there is a wealth of
decomposition methods for them, analogous to the SVD decomposition
for arrays. We used tensors to find correlations and hidden
variables in IP traffic matrices, as well as other graphs, like the
DBLP author-paper-keyword datasets, evolving over time. The effort
led to several publications [Sun et al, KDD'06], [Sun et al
Siam DM'07], and a tutorial on tensors (with Sun and Kolda, Siam
DM'07).
The second activity was the analysis of influence propagation in
blogs. We found several power-law patterns, in real blog data, and
we publish the results in [Leskovec, Siam DM 2007]. The third
activity was the development of fast algorithms to find the
so-called 'CenterPiece SubGraphs' (CePS). Given a social network,
and $k$ query nodes (eg., criminals), we want to find the most
central node or nodes for that set (eg., the master-mind of the
crime-gang). Our algorithms are 2 orders of magnitude faster than
the naive implementation, and received the 'best paper' award in
ICDM [Tong Faloutsos, ICDM'06].
3.2. Current
Results
The first
major finding was the introduction of tensors for the analysis of
time-evolving graphs. Tensors provide powerful tools, which, in our
opinion, will greatly benefit the graph mining community. The Ph.D.
dissertation of Dr. Jimeng Sun focused exactly on that, and showed
that tensors can extract the 'normal' patterns in sensor data, as
well as spot outliers.
The second finding was that cascades in blogs follow several power
laws. Analysis of a large body of blogs and postings shows that (a)
the probability to point to a post drops as a *power law* with time
(as opposed to exponentially, that one might guess) (b) the most
typical shapes of cascades are 'star-like' cascades, instead of
random (c) the activity in cascades is bursty over time, as we
showed by using tools from chaotic time series analysis.
The third finding was the 150-fold speed-up of a graph mining
algorithm ('CePS'), which tries to find the most central nodes, for
a given set of query nodes.
We developed 'NetProbe', a system for fraud detection in electronic
auctions. Fraudsters give false feedback to their alter
egos, to deceive honest users. We observed that a common pattern in
that case is the 'bi-partite core': fraudsters get good feedbacks,
from 'accomplices' who behave like honest ones, except that they
give good feedbacks to many fraudsters-to-be. Our algorithm, using
Belief Propagation, is able to detect such bi-partite cores. The
system attracted a lot of media attention, as we mention later.
In 2007 we also developed CELF, a fast algorithm to find
near-optimal placement for sensors in a water distribution networ,
to protect against poisoning attacks. The algorithm is much faster
than the usual 'greedy' algorithm; it has provable performance
bounds, and it also attracted media attention and a 'best student
paper' award [Leskovec+, KDD'07]
In 2008, we worked on weighted graphs and the 'butterfly'
generator. We found that the total node weight grows super-linearly
with the degree of a node, and that the non-largest connected
components remain about constant in size (in fact, they oscillate).
The 'butterfly' generator obeys all these new patterns.
In 2008 we also worked on the 'Colibri' method. It focuses on
summarizing and tracking time-evolving graphs and it achieves
orders of magnitude better speed, for zero or tiny loss of
accuracy, versus older methods (CUR, SVD etc).
3.3.
Publications - refereed conferences
- Hanghang Tong, Christos Faloutsos Center-Piece
Subgraphs: Problem Definition and Fast Solutions, KDD 2006,
Philadelphia, PA
- Jimeng Sun, Dacheng Tao, Christos Faloutsos Beyond
Streams and Graphs: Dynamic Tensor Analysis, KDD 2006,
Philadelphia, PA
- Jure Leskovec, Christos Faloutsos Sampling from Large
Graphs (poster) KDD 2006, Philadelphia, PA.
- Duen Horng (Polo) Chau, Shashank Pandit and Christos Faloutsos
Detecting Fraudulent Personalities in Networks of Online
Auctioneers PKDD 2006, Berlin Germany.
- Hanghang Tong, Christos Faloutsos, and Jia-Yu Pan Fast
Random Walk with Restart and Its Applications ICDM 2006,
Hong Kong.
- Deepayan Chakrabarti, Jure Leskovec, Christos Faloutsos, Samuel
Madden, Carlos Guestrin and Michalis Faloutsos
Information Survival Threshold in Sensor and P2P Networks
INFOCOM, Anchorage, Alaska, USA, May 2007.
- Shashank Pandit, Duen Horng (Polo) Chau, Samuel Wang and
Christos Faloutsos
NetProbe: A Fast and Scalable System for Fraud Detection in Online
Auction Networks
WWW 2007, Banff, Alberta, Canada, May 8-12, 2007.
- Jimeng Sun, Yinglian Xie, Hui Zhang and Christos Faloutsos
Less
is More: Compact Matrix Decomposition for Large Sparse
Graphs (best research paper award) SDM'07,
Minneapolis, MN, USA, April 26-28, 2007.
- Jure Leskovec, Mary McGlohon, Christos Faloutsos, Natalie
Glance and Matthew Hurst Cascading Behavior in Large Blog
Graphs (poster presentation); SDM'07, Minneapolis, MN, USA,
April 26-28, 2007.
- Mary McGlohon, Jure Leskovec, Christos Faloutsos, Matthew Hurst
and Natalie Glance Finding
patterns in blog shapes and blog evolution Int. Conf. on
Weblogs and Social Media Boulder, CO, USA, March 26-28, 2007.
- Jure Leskovec, Andreas Krause, Carlos Guestrin, Christos
Faloutsos, Jeanne VanBriesen, and Natalie Glance Cost-effective
Outbreak Detection in Networks ACM SIGKDD Conference, San
Jose, CA, August 2007. (
expanded version, as CMU tech report ) Best student paper
award .
- Hanghang Tong, Yehuda Koren, and Christos Faloutsos, Fast
Direction-Aware Proximity for Graph Mining ACM SIGKDD
Conference, San Jose, CA, August 2007.
- Jimeng Sun, Spiros Papadimitriou, Philip S. Yu, and Christos
Faloutsos, GraphScope: Parameter-free Mining of Large
Time-evolving Graphs ACM SIGKDD Conference, San Jose, CA,
August 2007.
- Hanghang Tong, Brian Gallagher, Christos Faloutsos, and Tina
Eliassi-Rad Fast
Best-Effort Pattern Matching in Large Attributed Graphs
(short paper) ACM SIGKDD Conference, San Jose, CA, August
2007.
- Hanghang Tong, Spiros Papadimitriou, Philip S. Yu and Christos
Faloutsos Proximity Tracking on Time-Evolving Bipartite
Graphs SDM 08, Atlanta, GA, April 24-26, 2008.
- M. McGlohon, L. Akoglu, and C. Faloutsos, "Weighted Graphs and
Disconnected Components: Patterns and a Generator", KDD 2008, Las
Vegas, NV.
- Brian Gallagher, Hanghang Tong, Tina Eliassi-Rad, Christos
Faloutsos, "Using ghost edges for classification in sparsely
labeled networks", KDD 2008: 256-264, Las Vegas, NV.
-
Hanghang Tong, Spiros Papadimitriou, Jimeng Sun, Philip S. Yu,
Christos Faloutsos, "Colibri: fast mining of large static and
dynamic graphs", KDD 2008: 686-694, Las Vegas, NV.
3.4.
Publications - refereed journals
- Christos Faloutsos and Vasileios Megalooikonomou On Data
Mining, Compression, and Kolmogorov Complexity Data Mining and
Knowledge Discovery, 2006
- Deepayan Chakrabarti and Christos Faloutsos Graph mining: Laws, generators, and
algorithms ACMComputing Surveys (CSUR) 38,1, Article No. 2
(2006)
- Jurij (Jure) Leskovec, Jon Kleinberg and Christos Faloutsos
Graph Evolution: Densification
and Shrinking Diameters ACM TKDD, 1(1), 2007.
- Deepayan Chakrabarti, Yang Wang, Chenxi Wang, Jurij Leskovec
and Christos Faloutsos Epidemic
Thresholds in Real Networks ACM Trans. on Information and
System Security (TISSEC), 10(4), 2007.
- Hanghang Tong, Christos Faloutsos and Jia Yu (Tim) Pan
Random walk with restart: Fast
solutions and applications Knowledge and Information
Systems, Springer, 2007
4. IMPACT -
DISSEMINATION
4.1.
Software
- TensorStream, by Jimeng
Sun: matlab source
code - download. It requires the tensor
toolbox (v2.0). It implements tensors in a streaming setting.
Data stream values are often associated with multiple aspects. For
example, each value from environmental sensors may have an
associated type (e.g., temperature, humidity, etc) as well as
location. Aside from timestamp, type and location are the two
additional aspects. How to model such streams? How to
simultaneously find patterns within and across the multiple
aspects? How to do it incrementally in a streaming fashion? The
code addresses all these problems through a general data
model, tensor streams, and a suite of online summarization
algorithms including Dynamic tensor analysis (DTA), Streaming
tensor analysis (STA) and window-based tensor analysis (WTA). The
high level objective is to summarize the tensor stream as a smaller
core tensor streams in different space.
Related Publications:KDD06,
ICDM06
4.2.
Demos
- InteMon: Intelligent Monitoring System for Data
Center. Modern data centers
have a large number of components that must be monitored, including
servers, switches/routers, and environmental control systems.
InteMon is a prototype monitoring and
mining system for data centers. It uses the SNMP protocol to
monitor a new data data using a JSP web-based frontend interface
for system administrators. What sets InteMon apart from other cluster
monitoring systems is its ability to automatically analyze
correlations in the monitoring data in real time and alert
administrators of potential anomalies. It uses efficient, state of
the art stream mining methods to report broken correlations among
input streams. It also uses these methods to intelligently compress
historical data and avoid the need for administrators to configure
threshold-based monitoring bands.
4.3.
Awards
- Best Paper Award:
Hanghang Tong, Christos Faloutsos, and Jia-Yu Pan Fast
Random Walk with Restart and Its Applications ICDM 2006,
Hong Kong.
- Best Paper Award:
Jimeng Sun, Yinglian Xie, Hui Zhang and Christos Faloutsos
Less
is More: Compact Matrix Decomposition for Large Sparse
Graphs SIAM Data Mining, Minneapolis, MN, USA, April
2007.
- Best Student Paper
Award: Jure Leskovec, Andreas Krause, Carlos Guestrin,
Christos Faloutsos, Jeanne VanBriesen, and Natalie Glance
Cost-effective
Outbreak Detection in Networks ACM SIGKDD Conference, San
Jose, CA, August 2007.
- Best Research paper
award: Krause, A., Leskovec, J., Guestrin, C., VanBriesen,
J., Faloutsos, C. Efficient Sensor Placement Optimization for
Securing Large Water Distribution Networks ASCE Journal of
Water Resources Planning and Management, 134(6): 516-526,
2008.
- 2008 ACM-KDD best
dissertation award (runner up): Jimeng Sun, "Incremental
Pattern Discovery on Streams, Graphs and Tensors",
(2007). CMU-CS-07-149, CS, CMU
- 2009 ACM-KDD best
dissertation award: Jurij (Jure) Leskovec, "Dynamics
of large networks", (2008). CMU-ML-08-111, MLD, SCS, CMU
4.4. Out-reach
- presentations and tutorials
- We are in contact with E-bay and Symantec for further
collaborations on fraud detection. Mr. Chau attracted a prestigious
Symantec Research Labs fellowship., 2 years in a row.
- The PI and colleagues gave a tutorial on tensor analysis in
multiple conferences (SDM'07,
ICML'07,
KDD'07,
SIGMOD'07)
[Christos Faloutsos, Tamara Kolda, Jimeng Sun].
- Additional tutorials on blog analysis and graph mining have
been presented in WWW'08 (with Jure Leskovec), ICWSM'08 (with Mary
McGlohon) , CIKM'08
and ICDE'09
(with Hanghang Tong)
- The PI has also given several invited and/or distinguished
lectures on data mining and graph mining (Kent State U., Florida
Int. U., Lawrence Livermore Nat. Labs, Purdue,
in 2007;
Georgia Tech in 2008; PAKDD
2008; MMDS 2008,
IMC
2008)
4.5. In the
news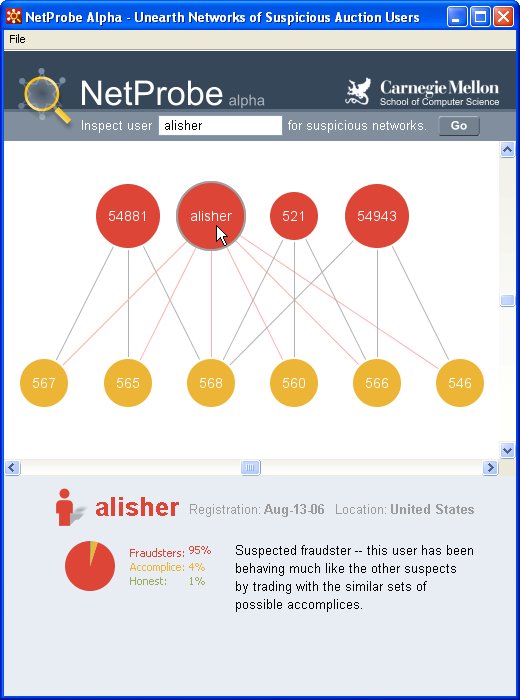
- NETPROBE
: Our 'NetProbe' system is spots the 'non-delivery'
type of fraud in electronic auctions. The project attracted
media attention (
Wall Street Journal Online,
Los Angeles Times,
USA Today,
Washington Post, etc). Specifically, 'NetProbe' [Pandit+,
WWW07] is able to spot sellers that are prone to commit the
'non-delivery' type of fraud. The idea is that such sellers usually
have 'accomplices', that is, nodes with good reputation, who have
never committed any fraud, but are willing to give good feedback
scores to the fraudsters-to-be. Our approach is based on the
observation that frauster-accomplice nodes form near-perfect
bi-partite cores, and our belief-propagation algorithm is able to
spot such cores with high accuracy.
Last updated: June 3,
2009,, by Christos Faloutsos.