Examples
This example scores and visualizes the machine translation output examples included with the Meteor distribution. First, run the Meteor jar file with no arguments:
$ java -jar meteor-*.jar
Meteor version 1.3
Usage: java -Xmx2G -jar meteor-*.jar
Running Meteor without any arguments produces the above help message outlining the various options available for scoring. For detailed descriptions of each option, see the included README file.
Now use Meteor to score the output of System1:
$ java -Xmx2G -jar meteor-*.jar example/xray/system1.hyp example/xray/reference -norm -writeAlignments -f system1
Meteor version: 1.3
Eval ID: meteor.1.3-en-norm-0.85_0.2_0.6_0.75-ex_st_sy_pa-1.0_0.6_0.8_0.6
Language: English
Format: plaintext
Task: Ranking
Modules: exact stem synonym paraphrase
Weights: 1.0 0.6 0.8 0.6
Parameters: 0.85 0.2 0.6 0.75
Segment 1 score: 0.447752250844953
Segment 2 score: 0.4284116369815996
Segment 3 score: 0.2772888474043816
...
Segment 2487 score: 0.2825995999223381
Segment 2488 score: 0.32037812996981163
Segment 2489 score: 0.33120147321343485
System level statistics:
Test Matches Reference Matches
Stage Content Function Total Content Function Total
1 16268 20842 37110 16268 20842 37110
2 485 26 511 489 22 511
3 820 119 939 845 94 939
4 3813 3162 6975 3954 2717 6671
Total 21386 24149 45535 21556 23675 45231
Test words: 61600
Reference words: 62469
Chunks: 20118
Precision: 0.6767347074578696
Recall: 0.6500539115850005
f1: 0.663126043401952
fMean: 0.6539211143997783
Fragmentation penalty: 0.5099053526424513
Final score: 0.3204832379614146
This displays the segment-level scores for the translation hypotheses and summary statistics for System1. The file system1-align.out is written, which contains human-readable alignments annotated with Meteor statistics. While the examample uses plaintext input, Meteor can also score input in WMT SGML and NIST XML formats using the -sgml option.
To visualize these alignments and statistics, run Meteor X-ray:
$ python xray/xray.py -p system1 system1-align.out
This produces system1-align-system-1.pdf containing scored alignment matrices as seen here:
 |
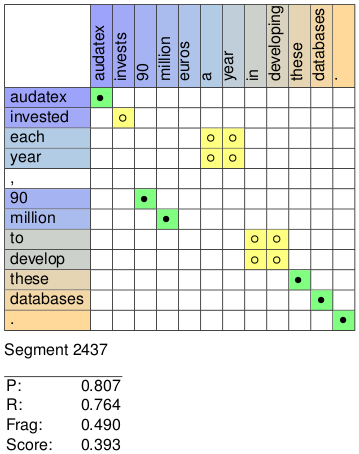 |
The TeX source for these alignments can be found in system1-files/align-1.tex. The file system1-score.pdf is also produced, though the score distributions will be more interesting when comparing two systems.
Next score the output of System2:
$ java -Xmx2G -jar meteor-*.jar example/xray/system2.hyp example/xray/reference -norm -writeAlignments -f system2
Run Meteor X-ray in comparison mode:
$ python xray/xray.py -c -p compare system1-align.out system2-align.out
This produces several useful files. The file compare-align.pdf contains matrices where the alignments of System2 (right, solid and hollow dots) are overlain on alignments of System1 (left, grey and yellow boxes), as seen here:
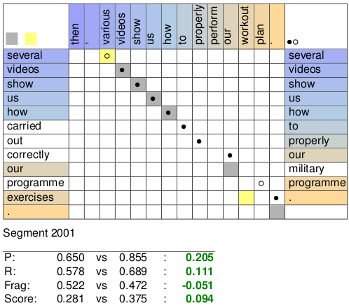
The alignments are also annotated with the differences in Meteor statistics between the two translations, allowing a thorough inspection of the differences between the two hypotheses as compared to the reference.
The file compare-score.pdf contains graphs of score distributions for individual segments for both systems:

Scores are also broken down by Meteor statistic and sentence length, as seen here:
 |
 |
All TeX and Gnuplot files used to create these visualizations are available in the created directory compare-files.