Design, Implementation, and Performance of a
Scalable Multi-Camera Interactive Video Capture System(1)
Martin Frankel and Jon A. Webb
Department of Computer Science
Carnegie Mellon University
Pittsburgh, PA 155213-3891
This paper will apear in the proceedings of "Computer
Architectures and Machine Perception," Como, Italy, September, 1995.
Table of Contents
Abstract
We describe a system for interactive, real time, multi-camera video capture and display. The system is almost entirely software-based and as a result is flexible and expandable. Computation and data storage is provided by the Carnegie Mellon-Intel Corporation iWarp computer. Video display is accomplished using a High Performance Parallel Interface network to write to a high resolution frame buffer. Video can be displayed as it is captured, with only a single frame latency. We provide interactivity with a VCR-like graphical interface running on a host workstation, which in turn controls the operation of the capture system. This system allows a user to interactively monitor, capture, and replay video with the ease of use of a VCR, yet with flexibility and performance that is unavailable in all but the most expensive and customized video capture systems.
For the purposes of a fast, accurate multi-baseline stereo vision system currently under development [1]), a video capture and display system was required to meet the following specifications:
- multiple cameras
- high frame rate (30 Hz)
- high resolution and image quality
- interactive, flexible user interface
In particular, in order to provide an interactive capture process, it is necessary to include video display capabilities. Ideally, the video would be displayed during capture, providing immediate feedback to the user.
Our system meets all of these goals, and provides considerable
flexibility for future expansion. In the current implementation it
supports four synchronized cameras sampling 512x480 8-bit greyscale
images at 30 Hz. The foundation of this system is an iWarp parallel
computer [2][3], which manages the overall data flow. Video input to
the iWarp is performed by locally developed hardware. The video data
is stored in the iWarp's local memory, and simultaneously sent via a
High Performance Parallel Interface (HiPPI) network to a frame buffer,
where all four images are displayed at full resolution in real
time. The user directs this process with an X Windows application
running on a workstation.
iWarp Architecture
The iWarp computer we are using has 64 cells in an 8x8 array (see
Figure 1.) Each cell consists of a processor, its local memory, and
support hardware. The processor itself consists of a computation agent
and a communication agent; the computation agent is under program
control, while the communication agent transparently supports the
communication needs of the processor. Each cell is connected to each
of its four nearest neighbors by a full-duplex, 40 MB/s physical bus;
the boundaries of the array are connected together, resulting in a
torus.
The iWarp executes a single array program at a time. An array program
consists of a set of programs which execute on individual cells, a
mapping of programs to cells, and a set of logical communication
pathways to be established between processors.
Each cell has 512kB of fast static RAM, which is used for the
operating system kernel, user program, and data. The cells in rows 0-3
also have 16MB each of slower dynamic RAM, which in our case is used
for video data storage. With a combined total of 512MB of dynamic RAM,
these cells can store roughly 17 seconds of four camera full frame
rate video.
The iWarp provides hardware expandability via two mechanisms. First, special purpose auxiliary cells can be connected to the array. One such cell, the Sun Interface Board (SIB), provides mechanisms whereby a host workstation can control the iWarp array and provides some I/O capability to the array program. Another pair of auxiliary cells, the HiPPI Interface Boards (HIBs), provide extremely high bandwidth, full duplex communications to other devices on a High Performance Parallel Interface (HiPPI) network.
While auxiliary cells offer tremendous flexibility, the design effort is considerable. Alternatively, each general purpose iWarp cell has an external memory bus to which a memory-mapped I/O device can be connected. The iWarp's 10 MB/s synchronous memory access rate enables high bandwidth I/O to be performed via this connector, as long as the control requirements are relatively simple. The video interface, described below, takes advantage of this external memory bus.
We use four black and white NTSC interlaced video cameras. The NTSC standard specifies 525 lines per frame, divided into two interlaced fields. Each field contains roughly 240 lines of useful information, with the remainder of the field devoted to the vertical retrace interval.
With 525 lines per frame and 30 frames per second, each scanline is roughly 63.5 microseconds (ms) long. Horizontal retrace and blanking take up some of that interval, leaving a useful video portion of about 51.2 ms. Using a 10 MHz sampling rate provides 512 pixels of horizontal resolution. The result is a 512x480 image for each frame, consisting of two fields which are captured 1/60th of a second apart.
The actual video sampling is performed by specialized hardware [4] which performs simultaneous A/D conversion of four synchronized video signals. Each A/D converter produces an 8 bit intensity for each pixel. The four pixels are concatenated into a single 32-bit word. This word is read from the external memory bus of a general purpose iWarp cell, the capture cell.
The design of the capture hardware was considerably simplified by not including a buffer between the A/D converter and the iWarp interface. However, the lack of buffering makes the task of the capture software particularly difficult. Since we are using a 10 MHz sampling rate, a sample must be acquired on alternate cycles of the 20 MHz system clock. Since the memory read instruction takes two clock cycles, the capture cell must read a sample from the video capture hardware and transmit it to another cell in the array in every instruction. Any delay, even a single clock cycle, causes unacceptable jitter in the resulting image.
The fact that this is possible in a software-based system is due to several notable features of the iWarp architecture described below.
4.1: Systolic communication model
In traditional message passing, messages are accumulated in memory and transmitted as a unit to a destination cell. In our application the overhead imposed by memory access and message processing would make real-time performance completely impossible: at the very least, storing each value in a memory buffer after it is sampled would require a second memory access in the inner loop, reducing the frame rate to 15 Hz. With systolic communications, this need for buffering is eliminated because single words are transmitted and routed independently through the array.
4.2: Efficient data routing
The iWarp provides hardware-assisted data routing with logical pathways and logical ports. A logical pathway is a data transport mechanism with a predefined source and destination cell; each end of the pathway is assigned a logical port, which the program uses to send or receive data over the pathway. Data passes through the cells along the route with negligible delay and no performance impact upon the intermediate cells. Furthermore, several logical pathways can pass over a single physical bus, without added overhead, and without contention until the full 40MB/s bandwidth of the physical bus is reached. These mechanisms allow the user to largely ignore the physical topology of the array and the details of data routing, multiplexing, and transport.
4.3: Zero-overhead loops
The iWarp processor has dedicated support for automatic loop iteration and branching. Using a special loop count register and a dedicated bit field in the instruction set, a loop need not contain any instructions to decrement the loop counter or perform the branch; that is all performed by dedicated hardware, in most cases without any time penalty or overhead. This eliminates the need for loop unrolling, which would complicate programming and might make the design impossible due to cache size limits.
4.4: Real time performance
The few interrupt-based services in the iWarp kernel can easily be disabled. When this is done, the execution of a non-I/O-bound array program becomes largely deterministic, ignoring instruction caching. Furthermore, each iWarp processor contains a hardware timer which decrements every 8 clock cycles. As a result, the behavior and timing of an array program can be made predictable, reliable, repeatable, and measurable down to a sub-microsecond level.
The inner loop which captures a single line of video data and sends it continuously to another cell could be as simple as the following:(2)
loop 512 ; executes once
endloop load (video_ADC_address),gate0
; executes 512 times
(Here the load in the second line copies data from the A/D converter to systolic pathway 0.)
However, this causes two problems:
- (a) A four-byte word is being transmitted every other clock cycle within the video scanline, for a burst transfer rate of 40 MB/s. This is the maximum theoretical bandwidth of the physical busses used to connect cells. However, a bug in the handshaking mechanism between cells results in unacceptable jitter when this full bandwidth is used entirely with data being read directly from memor, as opposed to a combination of data passed from other cells and data from memory.
- (b) Other cells must process the data stream, and if one sample arrives every two cycles, not enough time is left for processing.
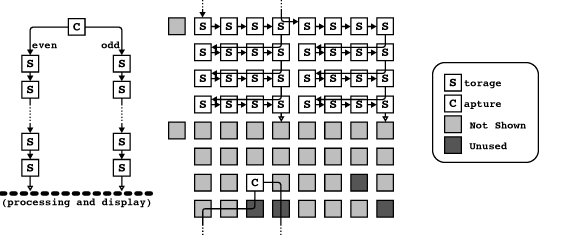
In order to reduce the peak transfer rate from 40 MB/s, we split the video data stream by transmitting alternate samples over two pathways to two identical sets of storage cells. As a result, each video field is stored as two separate half-fields, one with the even-numbered pixels from each scanline, and the other with the odd-numbered pixels from each scanline. The inner loop which actually executes on the capture cell is as follows:
loop 256 ; executes once
load (video_ADC_address),gate0
; executes 256 times
endloop load (video_ADC_address),gate1
; executes 256 times
The storage cells are cells 0 through 31, each of which is has 16 MB of dynamic RAM. These cells make up the top half of the array, as it is shown in Figure 2. Of these 32 cells, the left 16 store the half-fields containing the even-numbered pixels, and the right 16 store the half-fields containing the odd-numbered pixels. The storage cells in each half are connected together in a serial, unidirectional fashion. The capture cell is connected to the first storage cell in each chain, and the last storage cell is connected to the display processing cells, which are discussed in Section 7. In all, these cells can store 2048 half-fields, which make up 512 frames, or slightly over 17 seconds of 30 Hz video.
When data is being captured, every storage cell passes the incoming data, uninterrupted, to the next cell in the chain. One of these cells also copies the data into its local memory; the control mechanism which determines which cell should store a given frame is discussed in Section 8.
We considered three methods for displaying video during capture:
- (a) On the host workstation. It would be possible to send image data from the iWarp, via the SIB, to the host, and then display it on the host's monitor. However, the performance of this approach would be completely unacceptable. The SIB-to-host communications have low bandwidth and very high, unpredictable latency imposed by the Sun's operating system.
- (b) On television monitors. In addition to the video A/D converters described above, we have D/A converters which operate similarly, and provide an NTSC signal suitable for display on high quality television monitors. However, using separate monitors for each camera is inelegant, scales badly, is inflexible, and requires a dedicated analog network for video distribution.
- (c) On a dedicated framebuffer via a high speed, general purpose network. This is the approach we chose to implement.
High Performance Parallel Interface (HiPPI) is a connection oriented, switched, very high bandwidth network protocol [5][6]. It provides guaranteed 100 MB/s connections between devices, using crossbar switches to create small networks [7]. A recent collaboration between Carnegie Mellon University and the Network Systems Corporation resulted in the development of HiPPI transmit and receive hardware for the iWarp computer [9][10].
We also have a HiPPI frame buffer developed by Network Systems Corporation. The frame buffer receives data in a simple protocol (Frame Buffer Protocol) layered over the HiPPI framing protocol ("raw" HiPPI). The frame rate is limited only by the HiPPI bandwidth and the size of the window being updated. Using the X-HIB and the HiPPI framebuffer, we can easily display four 512x480 images tiled in a 1024x960 window at 30 Hz.
HiPPI communications on the iWarp are handled by a software suite running on the HiPPI Interface Boards called the HiPPI Streams Interface (HSI) [8]. The HSI insulates the array program from network-specific or protocol-specific details.
A significant amount of processing is required before the video data can be sent to the HSI and the framebuffer. The data arrives with three levels of interleaving, and must be sent to the frame buffer as a single 1024x960 window. The necessary processing tasks are as follows:
- (a) Pixel interleaving. Data arrives on two separate pathways, one with even pixels, the other with odd pixels.
- (b) Image demultiplexing. Each word of incoming data consists of four 8-bit pixel values, one from each camera. These must be separated so that each image can be transmitted independently.
- (c) Line interlacing. The even lines of an image arrive first, followed by the odd lines.
- (d) Image tiling. The resulting four images must be combined for transmission to frame buffer.
The requirement that these tasks be implemented using the 31 available iWarp cells, each of which has only 512kB of memory, yet provide 30 Hz frame rate with as little latency as possible, limits the options in performing these tasks considerably. For example, during a video scanline, two words of data arrive at the display processing cells every four clock cycles; these must be rearranged and then sent at an average rate of 30 MB/s over a single pathway. Even if the task were split evenly across all available processors, without any blocking or overhead, only 21 clock cycles would be available to process each byte of data sent to the frame buffer.
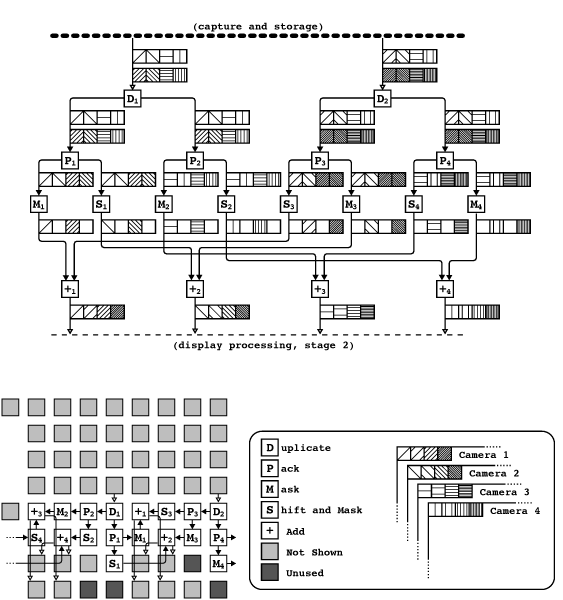
Our approach involves two stages, which use different operational paradigms. The first stage, which performs pixel de-interleaving and channel demultiplexing, operates on the data as a continuous pixel stream, ignoring scanline and frame boundaries. Consecutive cells perform simple operations on the data stream and then pass data on to other cells for further processing. The second stage, which performs line de-interlacing and image tiling, uses double-buffering to store complete frames and then send them, line by line, in a rearranged order.
Stage 1 is best understood by considering the first four pixels of a frame arriving from the storage cells. Due to pixel interleaving, the first and third pixels arrive on one pathway, while the second and fourth arrive on another pathway. Due to pixel multiplexing, the incoming images are combined, with a single word containing the pixel values for all four images. The output of stage 1 should be four words on four separate pathways, each one of which contain the first four pixels of an image. Subsequent blocks of four pixels are processed identically. The operations performed by each cell to achieve this goal are illustrated in Figure 3..
Stage 2 is somewhat simpler, consisting of only two basic types of cells: 8 buffer cells, and one switcher cell. The 8 buffer cells are broken into two sets of four, which are used to double-buffer the four images. While one set is buffering data from the capture cell, the other is transmitting data to the switcher cell; at the end of the frame, the two sets of buffer cells trade roles. This process is illustrated in Figure Figure 4. by physical switches; in reality, the switching is performed by the combine cells (from stage 1) and the switcher cell, which bind alternating sets of logical ports on alternating frames.
Line interlacing is performed trivially by the buffer cells; they read the interlaced video data directly into a memory buffer, and then send individual scanlines from the buffer in such a way that the switcher cell receives non-interlaced data.
The switcher cell is responsible for tiling the images and sending them to the X-HIB. The upper half of the window consists of images 1 and 2 side-by-side, which is accomplished by passing individual scanlines of images 1 and 2 in alternation. The lower half of the window is filled with images 3 and 4 in an identical manner.
Our graphical user interface (GUI) imitates a VCR and runs on the Sun. The GUI program sends messages to the SIB, and receives return messages, in what we call the external protocol. The external protocol concerns actions by the user, and is restricted to a relatively coarse level of control. The SIB then performs real-time, frame-by-frame control of the rest of the iWarp array, using the internal protocol to communicate with the other cells.
The external protocol is used to transmit user actions to the array, and to update the state of the GUI (to reflect, for instance, the number of frames available for recording).
The internal protocol consists of short control messages, which are sent over a dedicated pathway connecting every cell in the array in a closed loop. During the video retrace interval between frames, the SIB sends a message, e.g. to capture a frame into memory at a specific location. Each cell copies and passes the message, and then executes it. The message takes about 47 \xb5 s to pass through the entire array, leaving time to spare before the end of the 1.25 ms vertical retrace interval.
The system provides all the usual capabilities of a conventional VCR --- play, record, fast forward, and rewind --- through a convenient graphical interface at full frame rate, and achieves a transfer rate over HiPPI of 30 MB/s, a significant fraction of the peak 42.5 MB/s achievable with the current hardware interface. It also supports many capabilities important in research in multi-baseline stereo research, such as variable capture rates and integration with a computer system (allowing frame capture to be triggered under program control).
We are considering:
- 1. Additional camera support. Video interfaces can be attached to up to 8 cells in the 8x8 array, allowing simultaneous capture from as many as 32 synchronized cameras.
- 2. External storage over HiPPI. The Parallel Data Laboratory at Carnegie Mellon University is developing a large (100+ GB) storage server which should provide high bandwidth disk storage over HiPPI [11]. Much of the software developed for image display will be directly applicable to image storage over HiPPI, including the user interface and video processing. Furthermore, since additional processing could be performed in the iWarp cells currently devoted to storage, a greater number of cameras could be supported at high frame rates.
- 3. External stereo vision calculation over HiPPI. In the past, stereo vision processing was performed on the iWarp. Since more powerful computers are now available, the iWarp could serve as a dedicated video capture system and feed data over HiPPI to another computer which would do further processing.
Bibliography
[1] Kang, S. B., J. A. Webb, et al. (1994). An Active Multi-baseline Stereo Vision System with Real-time Image Acquisition. ARPA Image Understanding Workshop, Monterey, CA, 1325-1334, Morgan Kaufmann.
[2] Borkar, S., R. Cohn, et al. (1988). iWarp: An Integrated Solution to High-Speed Parallel Computing. Proceedings of Supercomputing `88, Orlando, Florida, 330-339.
[3] Borkar, S., R. Cohn, et al. (1990). Supporting Systolic and Memory Communications in iWarp. 17th International Symposium on Computer Architecture, Seattle, WA.
[4] Kang, S. B., T. Warfel, J. A. Webb (1994). A Scalable Video Rate Camera Interface. CMU-CS-94-192, Carnegie Mellon University.
[5] Tolmie, D. and J. Renwick (1993). "HIPPI: Simplicity Yields Success." IEEE Network (January).
[6] ANSI X3T9 (1991). High Performance Parallel Interface -- Mechanical, Electrical, and Signalling Protocol Specification (HIPPI-PH). ANSI X3.183-1991.
[7] ANSI X3T9 (1993). High Performance Parallel Interface -- Physical Switch Control (HIPPI-SC). ANSI X3.222-1993.
[8] Hemy, M. (1993). HIB Interface Manual, Revision 1. CMU-CS-93-186, Carnegie Mellon University.
[9] Steenkiste, P., B. Zill, et al. (1992). A Host Interface Architecture for High Speed Networks. Proceedings of the 4th IFIP Conference on High Performance Networks, Liege, Belgium, 1-16, IFIP.
[10] Steenkiste, P., M. Hemy, et al. (1994). Architecture and Evaluation of a High Speed Networking Subsystem for Distributed-Memory Subsystems. The 21st Annual International Symposium on Computer Architecture, Chicago, IL, IEEE.
[11] Gibson, G., D. Stodolsky, et al. (1995). The Scotch Parallel Storage Systems. Proceedings of the IEEE CompCon Conference, San Fransisco, CA, IEEE.
Footnotes
- (1)
- This research was partially supported by the Adanced Research Projects Agency of the Department of Defense under contract number F19628-93-C-0171, ARPA order number A655, "High Performance Computing Graphics," monitored by Hanscom Air Force Base. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Advanced Research Projects Agency, the Department of Defense, or the U.S. government.
- (2)
- The assembly language syntax used here is modified slightly for clarity.
{kind=link}
{kind=link}