We initiated our research with the task of having an agent learn to shoot a moving ball passed by a passing agent with a simple behavior which could affect the speed and the trajectory of the ball. Hence, in this task there is a single learning agent. We call the learned behavior a shooting template. This initial task provided the basis for our interest and on-going research on more elaborate multi-agent learning scenarios. We describe here only enough of the experiments to illustrate the task. For more details, please see [Stone & Veloso1995].
In all of our initial experiments, a passer accelerates as fast
as possible towards a stationary ball in order to propel it between a
shooter and the goal. The resulting speed of the ball is
determined by the distance that the passer started from the ball. The
shooter's task is to time its acceleration so that it intercepts the
ball's path and redirects it into the goal. We constrain the shooter
to accelerate at a fixed constant rate (while steering along a fixed
line) once it has decided to begin its approach. Thus the
behavior to be learned consists of the decision of when to begin
moving: at each action opportunity the shooter either starts or
waits. Once having started, the decision may not be retracted. The
shooter must make its decision based solely on the ball's and its own
![]() coordinates reported at a (simulated) rate of 60Hz.
coordinates reported at a (simulated) rate of 60Hz.
Throughout our initial experiments, the shooter's initial position
varies randomly within a continuous range: its initial heading varies
over 70 degrees and its initial x and y coordinates vary independently
over 40 units as shown in Figure 2(a).![]() The two shooters pictured show the extreme possible starting
positions, both in terms of heading and location.
The two shooters pictured show the extreme possible starting
positions, both in terms of heading and location.
Since the ball's momentum is initially across the front of the goal, the shooter must compensate by aiming wide of the goal (by 170 units) when making contact with the ball (see Figure 2(b)). Before beginning its approach, the shooter chooses a point wide of the goal at which to aim. Once deciding to start, it then steers along an imaginary line between this point and the shooter's initial position, continually adjusting its heading until it is moving in the right direction along this line. The shooter's aim is to intercept the ball's path so as to redirect it into the goal.
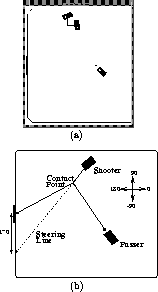
Figure: (a) The initial position for the experiments. The
car in the lower part of the picture, the passer, accelerates
full speed ahead until it hits the ball. Another car, the
shooter then attempts to redirect the ball into the goal on the left.
The two cars in the top of the figure illustrate the extremes of the
range of angles of the shooter's initial position. The square behind
these two cars indicates the range of the initial position of the
center of the shooter. (b) A diagram illustrating the paths
of the ball and the cars during a typical trial.
The task of learning a shooting template has several parameters that
can control how hard it is. First, the ball can be moving at the same
speed for all training examples or at different speeds. Second, the
ball can be coming with the same trajectory or with different
trajectories. Third, the goal can always be in the same place during
testing as during training, or it can change locations (think of this
parameter as the possibility of aiming for different parts of the
goal). Fourth, the training and testing can occur all in the same
location, or the testing can be moved to a different symmetrical
location on the field. Figure 3 illustrates some of
these variations. Using a neural network (NN), we have learned a
shooting template that can be successful despite variations along all
of these dimensions. Table ![]() summarizes our initial
results.
summarizes our initial
results.
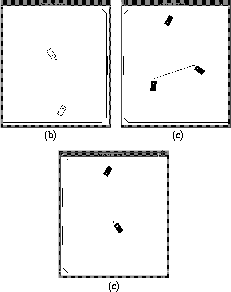
Figure: Variations to the initial setup: (a) The initial position
in the opposite corner of the field (a different action quadrant);
(b) Varied ball trajectory: The line indicates the ball's
possible initial positions, while the passer always starts directly
behind the ball facing towards a fixed point. The passer's initial
distance from the ball controls the speed at which the ball is passed;
(c) Varied goal position: the placement of the higher and
lower goals are both pictured at once.
: A summary of our learning results for shooting a moving ball
into a goal. The learned decision policy is trained on the examples
generated with the random decision criterion.
