One of the ultimate goals subjacent to the development of intelligent agents is to have multiple agents collaborating in the achievement of specific tasks in the presence of hostile opponents. Our research works towards this broad goal from a Machine Learning perspective. We are particularly interested in investigating how an individual intelligent agent can choose an action in an adversarial environment. We assume that the agent has a specific goal to achieve. We conduct this investigation in a framework where teams of agents compete in a game of robotic soccer. The real system of model cars remotely controlled from off-board computers is under development. Our research is currently conducted in a simulator of the physical system.
Both the simulator and the real-world system are based closely on systems designed by the Laboratory for Computational Intelligence at the University of British Columbia [5]. In particular, our simulator's code is adapted from their own code, for which we thank Michael Sahota whose work [8] and personal correspondence [7] has been motivating and invaluable. The simulator facilitates the control of any number of cars and a ball within a designated playing area. Care has been taken to ensure that the simulator models real-world responses (friction, conservation of momentum, etc.) as closely as possible. A graphic display allows the researcher to watch the action in progress, or the graphics can be toggled off to speed up the rate of the experiments. Figure 1 shows the simulator graphics.
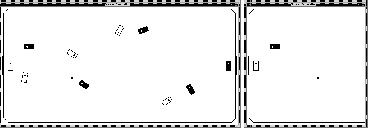
Figure 1: On the left is the graphic view of our simulator. On the
right is the initial position for all of the experiments in this
paper. The teammate (black) remains stationary, the defender (white)
moves in a small circle at different speeds, and the ball can move
either directly towards the goal or towards the teammate. The
position of the ball represents the position of the learning agent.
We have focused on the question of learning to choose among actions in the presence of an adversary. This paper describes our work on applying memory-based supervised learning techniques to acquire strategy knowledge that enables an agent to decide how to achieve a goal. For other work in the same domain, please see [12, 13].
The input to the learning task includes a continuous-valued range of the position of the adversary. This raises the question of how to discretize the space of values into a set of learned features. We present our empirical studies and results on learning an appropriate generalization degree in this continuous-valued space. Due to the cost of learning and reusing a large set of specialized instances, we notice a clear advantage to having an appropriate degree of generalization.
Next, we address the issue of the effect of differences between past episodes and the current situation. We performed extensive experiments, training the system under particular conditions and then testing it (with training continuing incrementally) in nondeterministic variations of the training situation. Our results show that when the random variations fall within some bound of the initial training, the agent performs better with some initial training rather than from a tabula-rasa. This intuitive fact is interestingly well- supported by our empirical results.
The paper is organized in five sections. Section 2 describes the memory-based learning method and the experimental setup. Section 3 presents and discusses the results obtained. Section 4 discusses related work and our own directions for future work. Section 5 summarizes our conclusions.