As in any RL approach, the reward function plays a large role in determining what policy is learned. One possible reward function is based entirely upon reaching the ultimate goal. Although goals scored are the true rewards in this domain, such events are very sparse. In order to increase the feedback from actions taken, it is useful to use an internal reinforcement function, which provides feedback based on intermediate states towards the goal. Without exploring the space of possible such functions, we created one reward function R.
R gives rewards for goals scored. However, players also receive
rewards if the ball goes out of bounds, or else after a fixed period
of time ![]() based on the ball's average lateral position on the
field. In particular, when a player takes action
based on the ball's average lateral position on the
field. In particular, when a player takes action ![]() in state s
such that
in state s
such that ![]() , the player records the time t at which the
action was taken as well as the x coordinate of the ball's position at
time t,
, the player records the time t at which the
action was taken as well as the x coordinate of the ball's position at
time t, ![]() . The reward function R takes as input the observed
ball position over time
. The reward function R takes as input the observed
ball position over time ![]() (a subset of
(a subset of ![]() ) and
outputs a reward r. Since the ball position over time depends also
on other agents' actions, the reward is stochastic and non-stationary.
Under the following conditions, the player fixes the reward r:
) and
outputs a reward r. Since the ball position over time depends also
on other agents' actions, the reward is stochastic and non-stationary.
Under the following conditions, the player fixes the reward r:
In case 1, the reward r is based on the value ![]() as
indicated in Figure 1(b):
as
indicated in Figure 1(b): ![]() . Thus, the farther in the future the ball goes
out of bounds (i.e. the larger
. Thus, the farther in the future the ball goes
out of bounds (i.e. the larger ![]() ), the smaller the absolute value
of r. This scaling by time is akin to the discount factor used in
Q-learning. We use
), the smaller the absolute value
of r. This scaling by time is akin to the discount factor used in
Q-learning. We use ![]() and
and ![]() .
.
In cases 2 and 3, the reward r is based on the
average x-position of the ball over the time t to the time ![]() or
or ![]() . Over that entire time span, the player samples the
x-coordinate of the ball at fixed, periodic intervals and computes the
average
. Over that entire time span, the player samples the
x-coordinate of the ball at fixed, periodic intervals and computes the
average ![]() over the times at which the ball position is known.
Then if
over the times at which the ball position is known.
Then if ![]() ,
, ![]() where
where ![]() is the x-coordinate of the opponent goal (the right
goal in Figure 1(b)). Otherwise, if
is the x-coordinate of the opponent goal (the right
goal in Figure 1(b)). Otherwise, if ![]() ,
,
![]() where
where ![]() is the
x-coordinate of the learner's goal.
is the
x-coordinate of the learner's goal.![]() Thus, the reward is the fraction of the
available field by which the ball was advanced, on average, over the
time-period in question. Note that a backwards pass can lead to
positive reward if the ball then moves forward in the near future.
Thus, the reward is the fraction of the
available field by which the ball was advanced, on average, over the
time-period in question. Note that a backwards pass can lead to
positive reward if the ball then moves forward in the near future.
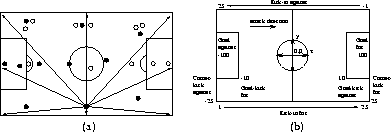
Figure 1: (a) The black and white dots represent the players attacking the
right and left goals respectively. Arrows indicate a single player's
action options when in possession of the ball. The player kicks the
ball towards a fixed set of markers around the field, including the
corner flags and the goals.
(b) The component ![]() of the reward function R based on the
circumstances under which the ball went out of bounds. For kick-ins,
the reward varies linearly with the x position of the ball.
of the reward function R based on the
circumstances under which the ball went out of bounds. For kick-ins,
the reward varies linearly with the x position of the ball.
The reward r is based on direct environmental feedback. It is a domain-dependent internal reinforcement function based upon heuristic knowledge of progress towards the goal. Notice that it relies solely upon the player's own impression of the environment. If it fails to notice the ball's position for a period of time, the internal reward is affected. However, players can track the ball much more easily than they can deduce the internal states of other players as they would have to do were they to determine future team state transitions.
As teammates learn concurrently, the concept to be learned by each
individual agent changes over time. We address this problem by
gradually increasing exploitation as opposed to exploration in all
teammates and by using a learning rate ![]() (see
Equation 1). Thus, even though we are averaging
several reward values for taking an action in a given state, each new
example accounts for 2% of the updated Q-value: rewards gained while
teammates were acting more randomly are weighted less heavily.
(see
Equation 1). Thus, even though we are averaging
several reward values for taking an action in a given state, each new
example accounts for 2% of the updated Q-value: rewards gained while
teammates were acting more randomly are weighted less heavily.
