

Next: Computing the Parameters
Up: Maxent Modeling
Previous: Maximum likelihood
Respecting the importance of the material in this section, we pause to provide
an outline.
- We began by seeking the conditional distribution
 which had
maximal entropy
which had
maximal entropy  subject to a set of linear constraints
(7).
subject to a set of linear constraints
(7).
- Following the traditional procedure in constrained optimization, we
introduced the Lagrangian
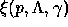 , where
, where  are a set of Lagrange multipliers for the constraints we imposed on
are a set of Lagrange multipliers for the constraints we imposed on
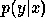 .
.
- To find the solution to the optimization problem, we appealed to the
Kuhn-Tucker theorem, which states that we can (1) first solve
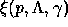 for
for  to get a parametric form for
to get a parametric form for
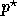 in terms of
in terms of 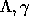 ; (2) then plug
; (2) then plug 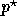 back in to
back in to
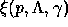 , this time solving for
, this time solving for  .
.
- The parametric form for
 turns out to have the exponential form
(11).
turns out to have the exponential form
(11).
- The
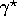 gives rise to the normalizing factor
gives rise to the normalizing factor 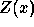 , given in
(12).
, given in
(12).
- The
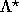 will be solved for numerically using
the dual function (14). Furthermore, it so happens that this
function,
will be solved for numerically using
the dual function (14). Furthermore, it so happens that this
function, 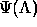 , is the log-likelihood for the exponential model
, is the log-likelihood for the exponential model
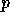 (11). So what started as the maximization of
entropy subject to a set of linear constraints turns out to be equivalent to
the unconstrained maximization of likelihood of a certain parametric family of
distributions.
(11). So what started as the maximization of
entropy subject to a set of linear constraints turns out to be equivalent to
the unconstrained maximization of likelihood of a certain parametric family of
distributions.
Table 1 summarizes the primal-dual framework we have
established.

Adam Berger
Fri Jul 5 11:43:50 EDT 1996