In the literature we find theoretical analyses for the alternative approaches to one aspect of parallel search, namely task distribution. Kumar and Rao [19] provide an analysis of the speedup of distributed tree search, and Powley and Korf [25] provide an analysis of parallel window search. In this section we summarize these analyses with a unifying representation, and empirically compare the performance of the techniques using the derived equations.
These analyses assume that the average branching factor bremains constant throughout the search space and that the least-cost goal is located at a depth d. We also let b represent the heuristic branching factor, or the ratio of nodes generated during one iteration of IDA* to the number of nodes generated during the previous iteration of IDA*. Forcing the heuristic branching factor to be equal to the average branching allows the analysis to be the same as for incremental-deepening depth-first search.
For the distributed tree search analysis, we assume that a breadth-first
expansion is used to generate enough nodes, n, to distribute one node to
each of P processors. Since
![]() and
and
![]() ,
we can assume that the tree is expanded to depth x where
,
we can assume that the tree is expanded to depth x where
![]() .
We will assume a time of
.
We will assume a time of
![]() to perform the node distribution
and to collect the solution results from each processor. The speedup of
distributed tree search, measured as the run time of the serial algorithm
divided by the run time of the parallel algorithm, can be computed here
as the number of serial nodes generated (assuming a constant node expansion
time) divided by the number of serial node expansions performed by the parallel
algorithm. This is derived in the literature [19,35] as
to perform the node distribution
and to collect the solution results from each processor. The speedup of
distributed tree search, measured as the run time of the serial algorithm
divided by the run time of the parallel algorithm, can be computed here
as the number of serial nodes generated (assuming a constant node expansion
time) divided by the number of serial node expansions performed by the parallel
algorithm. This is derived in the literature [19,35] as
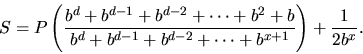 |
(1) |
As d increases, the leftmost fractional part of this equation approaches 1 and can be ignored. The 1/2bx term contributes a minimal amount to the final value and can also be ignored. In this case, speedup approaches P, which represents linear speedup.
Figure 5 shows the performance of the distributed tree search algorithm based on these equations on a perfectly balanced tree and on a heavily imbalanced tree for P = 10, b = 3, and d = 10. In the imbalanced case, the size of the processors' search spaces varies as an exponential function where the first processor is assigned a majority of the work and the load decreases as the processor number increases. In this graph, the goal position ranges from the far left side of the tree (position = 0) to the far right side of the tree (position = 1). Performance of the search algorithm always peaks when the goal is on the far left side of a processor's portion of the search space. For the case of an imbalanced tree, much of the search space is assigned to a single processor, which increases the resulting amount of serial effort required.
We next consider the theoretical performance of the parallel window search algorithm. Recall that parallel window search operates by distributing the window sizes, or cost thresholds, to each available processor so each processor performs one iteration of IDA*. Since thresholds are not explored sequentially, the first solution found may not represent an optimal path. To ensure an optimal solution, all processors with a lower threshold must complete their current iteration of IDA*. In the worst case, this can make the performance of parallel window search equal to that of a serial version of IDA*.
In this analysis the assumption is made that a sufficient number of processors
exists such that the goal iteration will start without delay.
Speedup of parallel window search can be calculated as
the ratio of the number of non-goal plus goal iteration nodes to the number of
nodes generated by the processor performing the goal
iteration. Powley and Korf generate this ratio using the notion of the
left-to-right goal position a, defined as the fraction of the total number
of nodes in the goal iteration that must be expanded before reaching the
first goal node [25].
Speedup of parallel window search can thus be expressed as
Given this formula, we can empirically compare the performance of distributed tree search and parallel window search for P = 10, b = 6, and d = 10. From the graph in Figure 6 we can see that parallel window search will outperform distributed tree search only if the goal is located on the far left of the search space. We also observe that performance of distributed tree search peaks whenever the goal node is located on the far left of the subspace assigned to a particular processor.
Similar analyses have been provided to compare node ordering techniques and to determine the optimal number of clusters [10,25,35]. These analyses do indicate trends in the performance of alternative strategies based on features of the problem space, and can also be used to determine the theoretical performance of a particular technique for a given problem. However, the terms used to predict the performance in many of these analyses are not always measurable and many assumptions made are too constraining for real-world problems.


