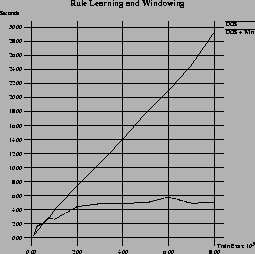
The motivation for our study came from a brief experiment in which we compared windowing with a decision tree algorithm to windowing with a rule learning algorithm in the noise-free Mushroom domain. This domain contains 8124 examples represented by 22 symbolic attributes. The task is to discriminate between poisonous and edible mushrooms. Figure 2 shows the results of this experiment.

 |
The left graph shows the run-time behavior over different training set sizes of C4.5 invoked with its default parameters versus C4.5 invoked with one pass of windowing (parameter setting -t 1). No significant differences can be observed, although windowing seems to eventually achieve a little run-time gain. The graph is quite similar to one resulting from experiments with ID3 and windowing shown by [59], so that we believe the differences in the original version of windowing and the one implemented in C4.5 are negligible in this domain. The results are also consistent with those of [53], who, for this domain, reported run-time savings of no more than 15% for windowing with appropriate parameter settings. In any case, it is obvious that the run-time of both C4.5 and C4.5 with windowing grows linearly with the number of training examples.2
On the other hand, the right half of Figure 2 depicts a similar experiment with windowing and DOS, a simple separate-and-conquer rule learning algorithm. DOS3 is basically identical to p FOIL, a propositional version of FOIL [52] that uses information gain as a search heuristic, but no stopping criterion. Our implementation of windowing closely follows the algorithm depicted in Figure 1. The results show a large difference between DOS without windowing, which again takes linear time, and DOS with windowing, which seems to take only constant time for training set sizes of about 3000 examples and above. This surprising constant-time learning behavior can be explained by the fact that if windowing is able to reliably discover a correct theory from a subset of the examples, it will never use more than this amount of examples for learning this theory. The remaining examples are only used for verifying that the learned theory has been correctly learned. These costs, albeit linear in principle, are negligible compared to the costs of learning the correct theory.