The first step is to generate the Q-DAG. This is accomplished by applying the
Q-DAG clustering algorithm with the fault as a query variable and the sensors
as evidence variables. The resulting Q-DAG has five query nodes,
![]() ,
,
![]() ,
,
![]() ,
,
![]() , and
, and
![]() . Each node
evaluates to the probability of the corresponding fault under any instantiation
of evidence. The probabilities constitute a differential diagnosis that
tells us which fault is most probable given certain sensor values.
. Each node
evaluates to the probability of the corresponding fault under any instantiation
of evidence. The probabilities constitute a differential diagnosis that
tells us which fault is most probable given certain sensor values.
Figure 15 shows a stylized description of the Q-DAG restricted to
two of the five query nodes, corresponding to
![]() and
and ![]() .
The Q-DAG structure is symmetric for each fault value and sensor.
.
The Q-DAG structure is symmetric for each fault value and sensor.

Figure: A partial Q-DAG for the car example, displaying two of the
five query nodes, broken_fuel_pump and normal.
The shaded regions are portions of the Q-DAG that are shared by multiple query
nodes; the values of these nodes are relevant to the value of more than one
query node.
Given that the Q-DAG is symmetric for these possible faults, for clarity of
exposition we look at just the subset needed to evaluate node
![]() . Figure 16 shows a
stylized version of the Q-DAG produced for this node. Following are some
observations about this Q-DAG. First, there is an evidence-specific node for
every instantiation of sensor variables, corresponding to all forms of sensor
measurements possible. Second, all other roots of the Q-DAG are probabilities.
Third, one of the five parents of the query node
. Figure 16 shows a
stylized version of the Q-DAG produced for this node. Following are some
observations about this Q-DAG. First, there is an evidence-specific node for
every instantiation of sensor variables, corresponding to all forms of sensor
measurements possible. Second, all other roots of the Q-DAG are probabilities.
Third, one of the five parents of the query node
![]() is
for the prior on
is
for the prior on ![]() , and the other four are
for the contributions of the four sensors. For example, Figure 16
highlights (in dots) that part of the Q-DAG for computing the contribution
of the battery sensor.
, and the other four are
for the contributions of the four sensors. For example, Figure 16
highlights (in dots) that part of the Q-DAG for computing the contribution
of the battery sensor.
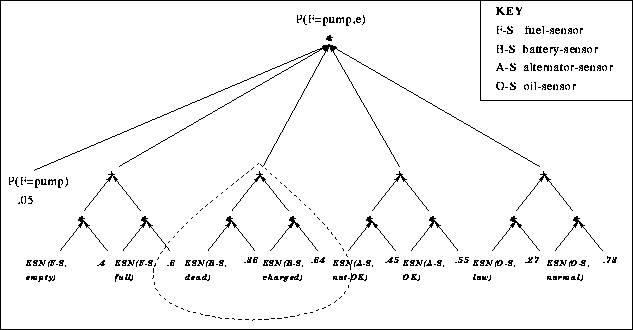
Figure: A partial Q-DAG for the car example.