A branch of the theory of adaptive control is devoted to learning automata, surveyed by Narendra and Thathachar [85], which were originally described explicitly as finite state automata. The Tsetlin automaton shown in Figure 3 provides an example that solves a 2-armed bandit arbitrarily near optimally as N approaches infinity.
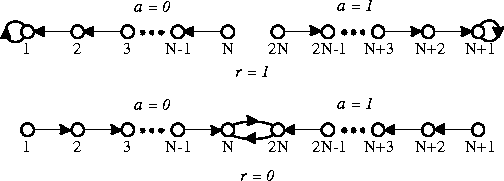
Figure 3: A Tsetlin automaton with 2N states. The top row shows the state
transitions that are made when the previous action resulted in a
reward of 1; the bottom row shows transitions after a reward of 0.
In states in the left half of the figure, action 0 is taken; in
those on the right, action 1 is taken.
It is inconvenient to describe algorithms as finite-state automata, so a move was made to describe the internal state of the agent as a probability distribution according to which actions would be chosen. The probabilities of taking different actions would be adjusted according to their previous successes and failures.
An example, which stands among a set of algorithms independently
developed in the mathematical psychology literature [45],
is the linear reward-inaction algorithm. Let ![]() be the
agent's probability of taking action i.
be the
agent's probability of taking action i.
![]()
This algorithm converges with probability 1 to a vector containing a
single 1 and the rest 0's (choosing a particular action with
probability 1). Unfortunately, it does not always converge to the
correct action; but the probability that it converges to the wrong one
can be made arbitrarily small by making ![]() small [86]. There is no literature on the regret of this
algorithm.
small [86]. There is no literature on the regret of this
algorithm.